 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Variational Inference
Mar 01, 2017


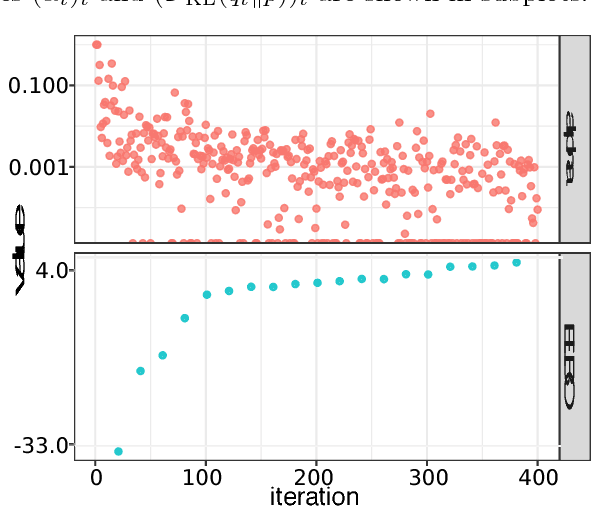
Variational inference (VI) provides fast approximations of a Bayesian posterior in part because it formulates posterior approximation as an optimization problem: to find the closest distribution to the exact posterior over some family of distributions. For practical reasons, the family of distributions in VI is usually constrained so that it does not include the exact posterior, even as a limit point. Thus, no matter how long VI is run, the resulting approximation will not approach the exact posterior. We propose to instead consider a more flexible approximating family consisting of all possible finite mixtures of a parametric base distribution (e.g., Gaussian). For efficient inference, we borrow ideas from gradient boosting to develop an algorithm we call boosting variational inference (BVI). BVI iteratively improves the current approximation by mixing it with a new component from the base distribution family and thereby yields progressively more accurate posterior approximations as more computing time is spent. Unlike a number of common VI variants including mean-field VI, BVI is able to capture multimodality, general posterior covariance, and nonstandard posterior shapes.
Parallelizing MCMC with Random Partition Trees
Oct 26, 2015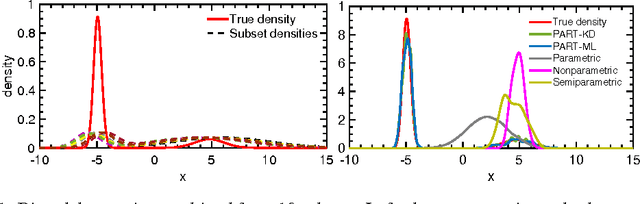

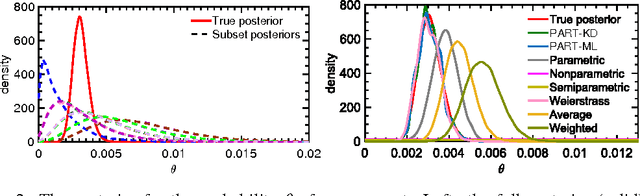
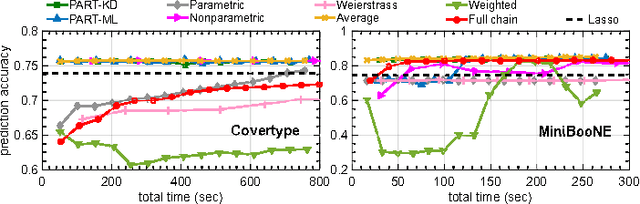
The modern scale of data has brought new challenges to Bayesian inference. In particular, conventional MCMC algorithms are computationally very expensive for large data sets. A promising approach to solve this problem is embarrassingly parallel MCMC (EP-MCMC), which first partitions the data into multiple subsets and runs independent sampling algorithms on each subset. The subset posterior draws are then aggregated via some combining rules to obtain the final approximation. Existing EP-MCMC algorithms are limited by approximation accuracy and difficulty in resampling. In this article, we propose a new EP-MCMC algorithm PART that solves these problems. The new algorithm applies random partition trees to combine the subset posterior draws, which is distribution-free, easy to resample from and can adapt to multiple scales. We provide theoretical justification and extensive experiments illustrating empirical performance.
The Bayesian Echo Chamber: Modeling Social Influence via Linguistic Accommodation
Jan 27, 2015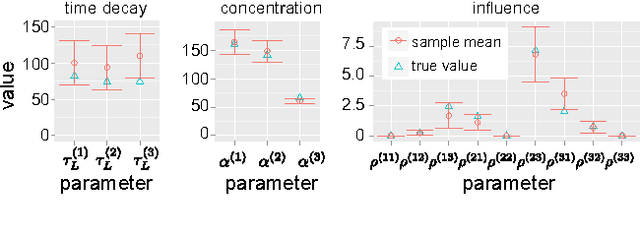


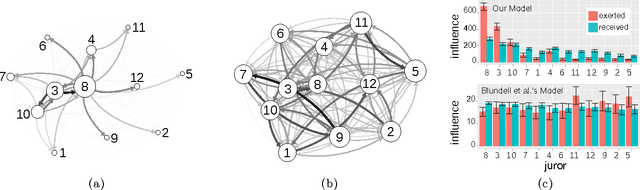
We present the Bayesian Echo Chamber, a new Bayesian generative model for social interaction data. By modeling the evolution of people's language usage over time, this model discovers latent influence relationships between them. Unlike previous work on inferring influence, which has primarily focused on simple temporal dynamics evidenced via turn-taking behavior, our model captures more nuanced influence relationships, evidenced via linguistic accommodation patterns in interaction content. The model, which is based on a discrete analog of the multivariate Hawkes process, permits a fully Bayesian inference algorithm. We validate our model's ability to discover latent influence patterns using transcripts of arguments heard by the US Supreme Court and the movie "12 Angry Men." We showcase our model's capabilities by using it to infer latent influence patterns from Federal Open Market Committee meeting transcripts, demonstrating state-of-the-art performance at uncovering social dynamics in group discussions.