 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCONE-GAN: Semantic Contrastive learning-based Generative Adversarial Network for an end-to-end image translation
Nov 07, 2023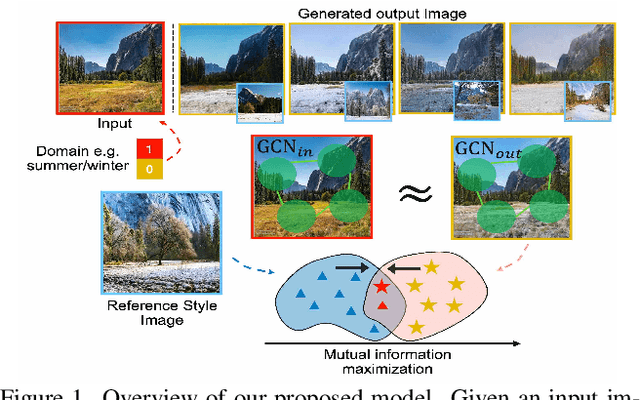
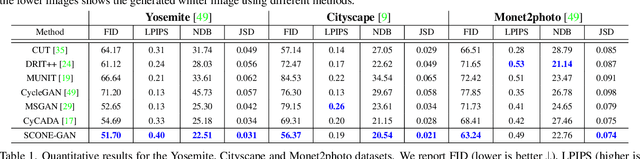
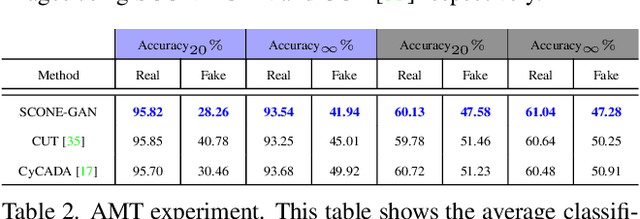

SCONE-GAN presents an end-to-end image translation, which is shown to be effective for learning to generate realistic and diverse scenery images. Most current image-to-image translation approaches are devised as two mappings: a translation from the source to target domain and another to represent its inverse. While successful in many applications, these approaches may suffer from generating trivial solutions with limited diversity. That is because these methods learn more frequent associations rather than the scene structures. To mitigate the problem, we propose SCONE-GAN that utilises graph convolutional networks to learn the objects dependencies, maintain the image structure and preserve its semantics while transferring images into the target domain. For more realistic and diverse image generation we introduce style reference image. We enforce the model to maximize the mutual information between the style image and output. The proposed method explicitly maximizes the mutual information between the related patches, thus encouraging the generator to produce more diverse images. We validate the proposed algorithm for image-to-image translation and stylizing outdoor images. Both qualitative and quantitative results demonstrate the effectiveness of our approach on four dataset.
SAGE: Generating Symbolic Goals for Myopic Models in Deep Reinforcement Learning
Mar 09, 2022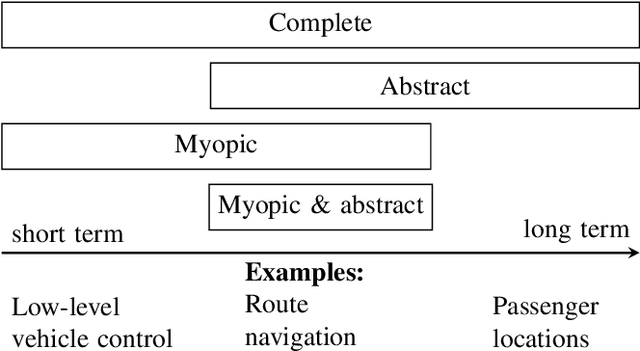
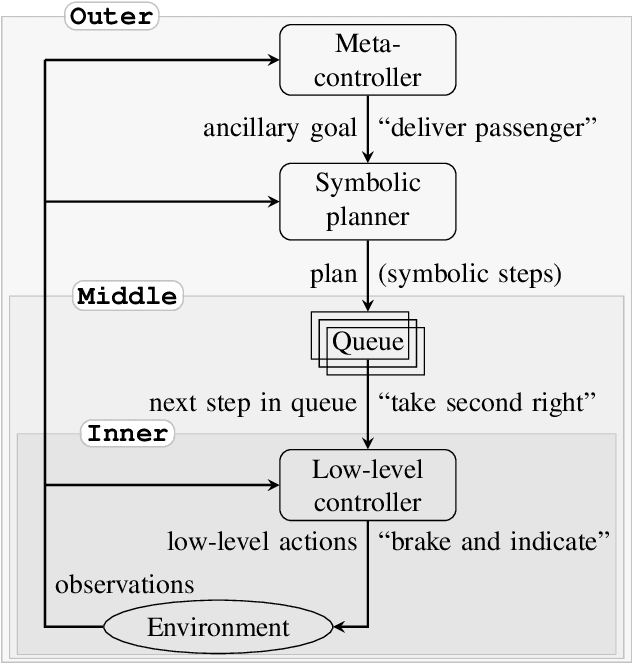


Model-based reinforcement learning algorithms are typically more sample efficient than their model-free counterparts, especially in sparse reward problems. Unfortunately, many interesting domains are too complex to specify the complete models required by traditional model-based approaches. Learning a model takes a large number of environment samples, and may not capture critical information if the environment is hard to explore. If we could specify an incomplete model and allow the agent to learn how best to use it, we could take advantage of our partial understanding of many domains. Existing hybrid planning and learning systems which address this problem often impose highly restrictive assumptions on the sorts of models which can be used, limiting their applicability to a wide range of domains. In this work we propose SAGE, an algorithm combining learning and planning to exploit a previously unusable class of incomplete models. This combines the strengths of symbolic planning and neural learning approaches in a novel way that outperforms competing methods on variations of taxi world and Minecraft.
Informing a BDI Player Model for an Interactive Narrative
Sep 23, 2019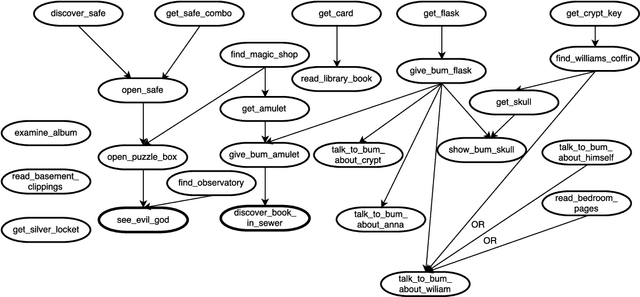
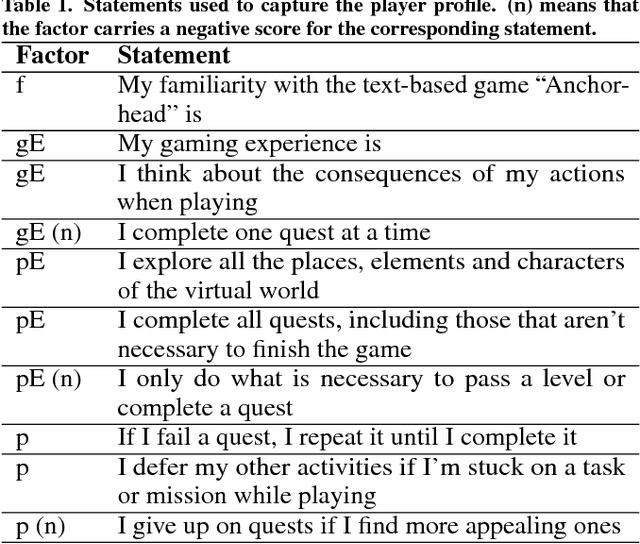
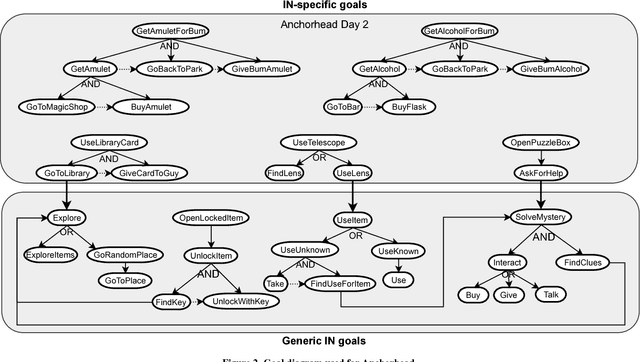

This work focuses on studying players behaviour in interactive narratives with the aim to simulate their choices. Besides sub-optimal player behaviour due to limited knowledge about the environment, the difference in each player's style and preferences represents a challenge when trying to make an intelligent system mimic their actions. Based on observations from players interactions with an extract from the interactive fiction Anchorhead, we created a player profile to guide the behaviour of a generic player model based on the BDI (Belief-Desire-Intention) model of agency. We evaluated our approach using qualitative and quantitative methods and found that the player profile can improve the performance of the BDI player model. However, we found that players self-assessment did not yield accurate data to populate their player profile under our current approach.
* CHI Play 2018
Exploring Apprenticeship Learning for Player Modelling in Interactive Narratives
Sep 16, 2019

In this paper we present an early Apprenticeship Learning approach to mimic the behaviour of different players in a short adaption of the interactive fiction Anchorhead. Our motivation is the need to understand and simulate player behaviour to create systems to aid the design and personalisation of Interactive Narratives (INs). INs are partially observable for the players and their goals are dynamic as a result. We used Receding Horizon IRL (RHIRL) to learn players' goals in the form of reward functions, and derive policies to imitate their behaviour. Our preliminary results suggest that RHIRL is able to learn action sequences to complete a game, and provided insights towards generating behaviour more similar to specific players.
Approximating Optimisation Solutions for Travelling Officer Problem with Customised Deep Learning Network
Mar 08, 2019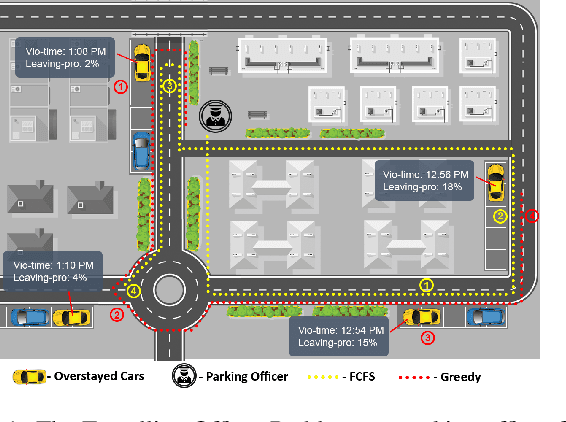
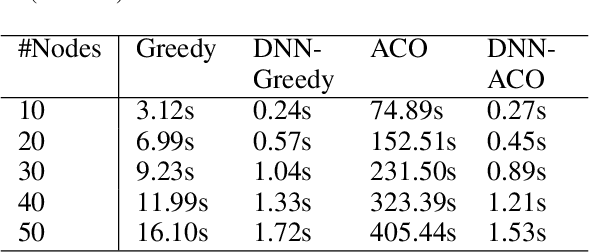
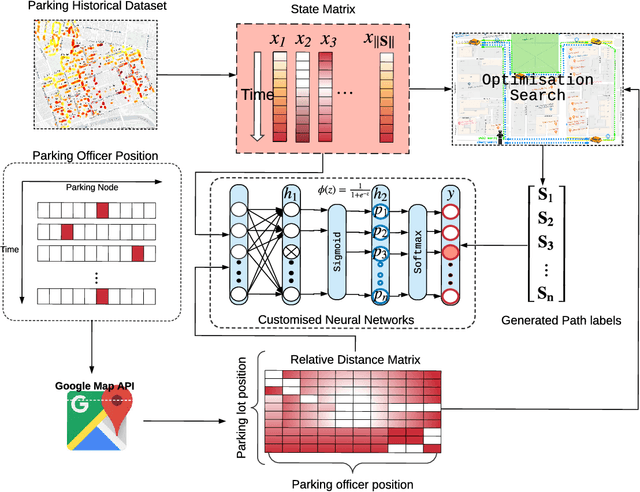
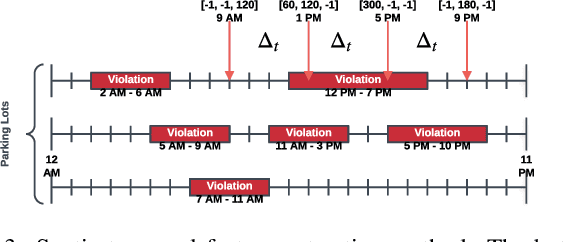
Deep learning has been extended to a number of new domains with critical success, though some traditional orienteering problems such as the Travelling Salesman Problem (TSP) and its variants are not commonly solved using such techniques. Deep neural networks (DNNs) are a potentially promising and under-explored solution to solve these problems due to their powerful function approximation abilities, and their fast feed-forward computation. In this paper, we outline a method for converting an orienteering problem into a classification problem, and design a customised multi-layer deep learning network to approximate traditional optimisation solutions to this problem. We test the performance of the network on a real-world parking violation dataset, and conduct a generic study that empirically shows the critical architectural components that affect network performance for this problem.