 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEAR: Automatic construction of a knowledge graph of chemical entities and roles from scientific literature
Jul 31, 2024


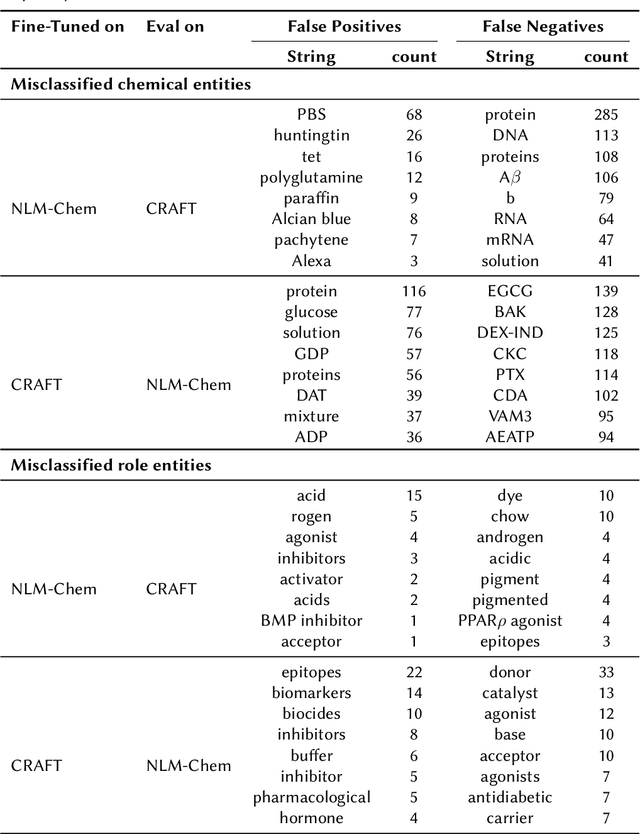
Ontologies are formal representations of knowledge in specific domains that provide a structured framework for organizing and understanding complex information. Creating ontologies, however, is a complex and time-consuming endeavor. ChEBI is a well-known ontology in the field of chemistry, which provides a comprehensive resource for defining chemical entities and their properties. However, it covers only a small fraction of the rapidly growing knowledge in chemistry and does not provide references to the scientific literature. To address this, we propose a methodology that involves augmenting existing annotated text corpora with knowledge from Chebi and fine-tuning a large language model (LLM) to recognize chemical entities and their roles in scientific text. Our experiments demonstrate the effectiveness of our approach. By combining ontological knowledge and the language understanding capabilities of LLMs, we achieve high precision and recall rates in identifying both the chemical entities and roles in scientific literature. Furthermore, we extract them from a set of 8,000 ChemRxiv articles, and apply a second LLM to create a knowledge graph (KG) of chemical entities and roles (CEAR), which provides complementary information to ChEBI, and can help to extend it.
A semantic loss for ontology classification
May 03, 2024Deep learning models are often unaware of the inherent constraints of the task they are applied to. However, many downstream tasks require logical consistency. For ontology classification tasks, such constraints include subsumption and disjointness relations between classes. In order to increase the consistency of deep learning models, we propose a semantic loss that combines label-based loss with terms penalising subsumption- or disjointness-violations. Our evaluation on the ChEBI ontology shows that the semantic loss is able to decrease the number of consistency violations by several orders of magnitude without decreasing the classification performance. In addition, we use the semantic loss for unsupervised learning. We show that this can further improve consistency on data from a distribution outside the scope of the supervised training.
The Mercurial Top-Level Ontology of Large Language Models
Apr 26, 2024



In our work, we systematize and analyze implicit ontological commitments in the responses generated by large language models (LLMs), focusing on ChatGPT 3.5 as a case study. We investigate how LLMs, despite having no explicit ontology, exhibit implicit ontological categorizations that are reflected in the texts they generate. The paper proposes an approach to understanding the ontological commitments of LLMs by defining ontology as a theory that provides a systematic account of the ontological commitments of some text. We investigate the ontological assumptions of ChatGPT and present a systematized account, i.e., GPT's top-level ontology. This includes a taxonomy, which is available as an OWL file, as well as a discussion about ontological assumptions (e.g., about its mereology or presentism). We show that in some aspects GPT's top-level ontology is quite similar to existing top-level ontologies. However, there are significant challenges arising from the flexible nature of LLM-generated texts, including ontological overload, ambiguity, and inconsistency.
Ontology Pre-training for Poison Prediction
Jan 20, 2023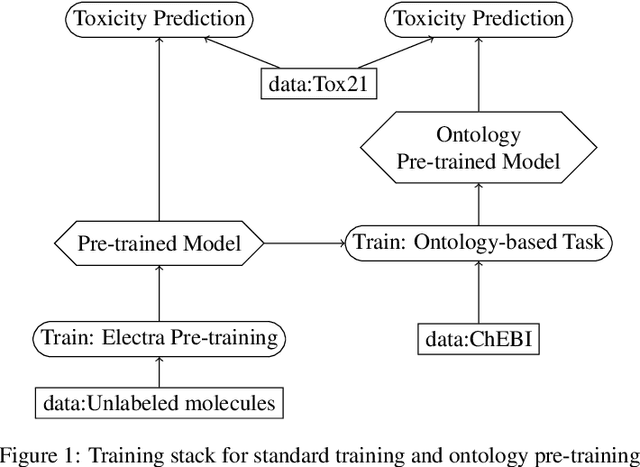
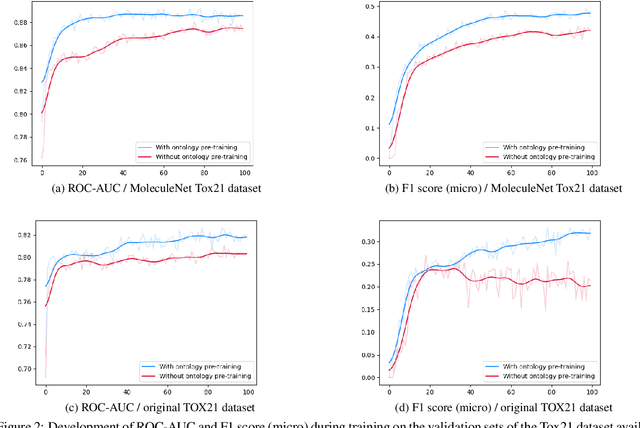
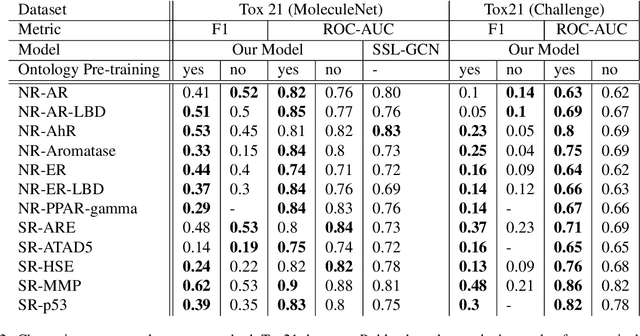
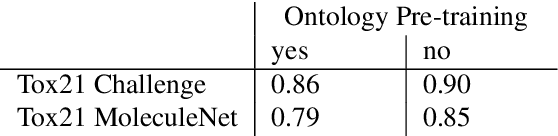
Integrating human knowledge into neural networks has the potential to improve their robustness and interpretability. We have developed a novel approach to integrate knowledge from ontologies into the structure of a Transformer network which we call ontology pre-training: we train the network to predict membership in ontology classes as a way to embed the structure of the ontology into the network, and subsequently fine-tune the network for the particular prediction task. We apply this approach to a case study in predicting the potential toxicity of a small molecule based on its molecular structure, a challenging task for machine learning in life sciences chemistry. Our approach improves on the state of the art, and moreover has several additional benefits. First, we are able to show that the model learns to focus attention on more meaningful chemical groups when making predictions with ontology pre-training than without, paving a path towards greater robustness and interpretability. Second, the training time is reduced after ontology pre-training, indicating that the model is better placed to learn what matters for toxicity prediction with the ontology pre-training than without. This strategy has general applicability as a neuro-symbolic approach to embed meaningful semantics into neural networks.
When one Logic is Not Enough: Integrating First-order Annotations in OWL Ontologies
Oct 07, 2022
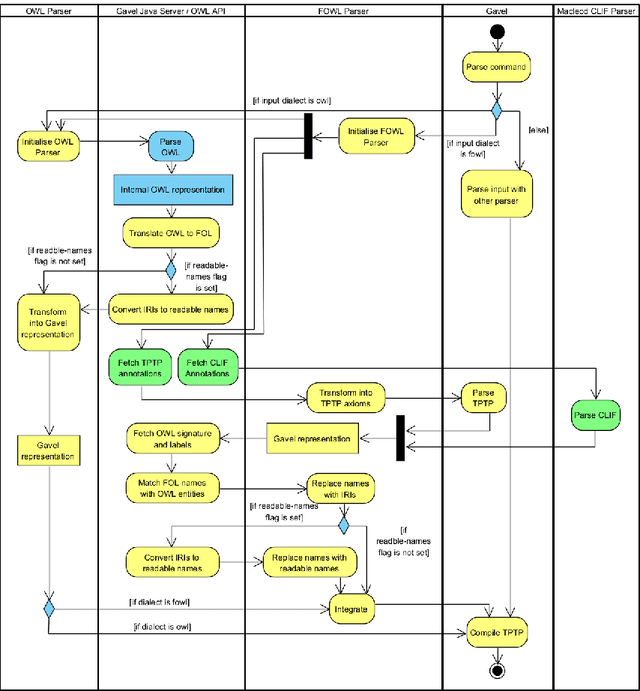

In ontology development, there is a gap between domain ontologies which mostly use the web ontology language, OWL, and foundational ontologies written in first-order logic, FOL. To bridge this gap, we present Gavel, a tool that supports the development of heterogeneous 'FOWL' ontologies that extend OWL with FOL annotations, and is able to reason over the combined set of axioms. Since FOL annotations are stored in OWL annotations, FOWL ontologies remain compatible with the existing OWL infrastructure. We show that for the OWL domain ontology OBI, the stronger integration with its FOL top-level ontology BFO via our approach enables us to detect several inconsistencies. Furthermore, existing OWL ontologies can benefit from FOL annotations. We illustrate this with FOWL ontologies containing mereotopological axioms that enable new meaningful inferences. Finally, we show that even for large domain ontologies such as ChEBI, automatic reasoning with FOL annotations can be used to detect previously unnoticed errors in the classification.
Automated and Explainable Ontology Extension Based on Deep Learning: A Case Study in the Chemical Domain
Sep 19, 2021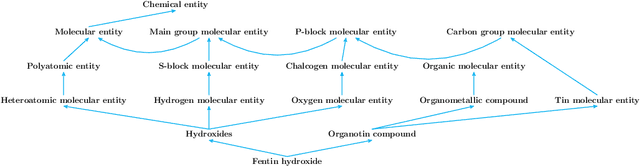
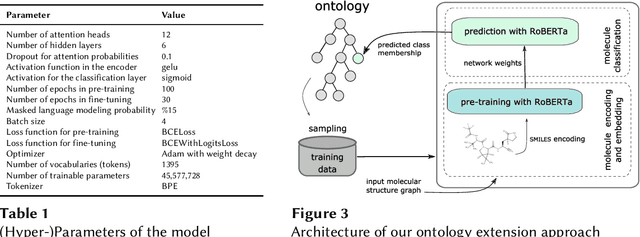

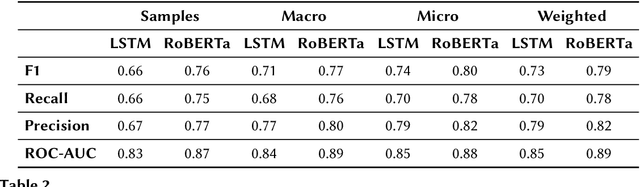
Reference ontologies provide a shared vocabulary and knowledge resource for their domain. Manual construction enables them to maintain a high quality, allowing them to be widely accepted across their community. However, the manual development process does not scale for large domains. We present a new methodology for automatic ontology extension and apply it to the ChEBI ontology, a prominent reference ontology for life sciences chemistry. We trained a Transformer-based deep learning model on the leaf node structures from the ChEBI ontology and the classes to which they belong. The model is then capable of automatically classifying previously unseen chemical structures. The proposed model achieved an overall F1 score of 0.80, an improvement of 6 percentage points over our previous results on the same dataset. Additionally, we demonstrate how visualizing the model's attention weights can help to explain the results by providing insight into how the model made its decisions.
Generic Ontology Design Patterns at Work
Jun 20, 2019

Generic Ontology Design Patterns, GODPs, are defined in Generic DOL, an extension of DOL, the Distributed Ontology, Model and Specification Language, and implemented using Heterogeneous Tool Set. Parameters such as classes, properties, individuals, or whole ontologies may be instantiated with arguments in a host ontology. The potential of Generic DOL is illustrated with GODPs for an example from the literature, namely the Role design pattern. We also discuss how larger GODPs may be composed by instantiating smaller GODPs.
What is an Ontology?
Oct 22, 2018In the knowledge engineering community "ontology" is usually defined in the tradition of Gruber as an "explicit specification of a conceptualization". Several variations of this definition exist. In the paper we argue that (with one notable exception) these definitions are of no explanatory value, because they violate one of the basic rules for good definitions: The defining statement (the definiens) should be clearer than the term that is defined (the definiendum). In the paper we propose a different definition of "ontology" and discuss how it helps to explain various phenomena: the ability of ontologies to change, the role of the choice of vocabulary, the significance of annotations, the possibility of collaborative ontology development, and the relationship between ontological conceptualism and ontological realism.
Modular Semantics and Characteristics for Bipolar Weighted Argumentation Graphs
Sep 26, 2018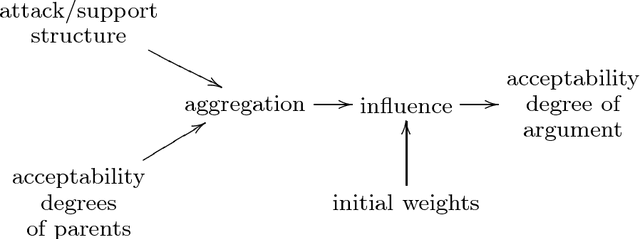
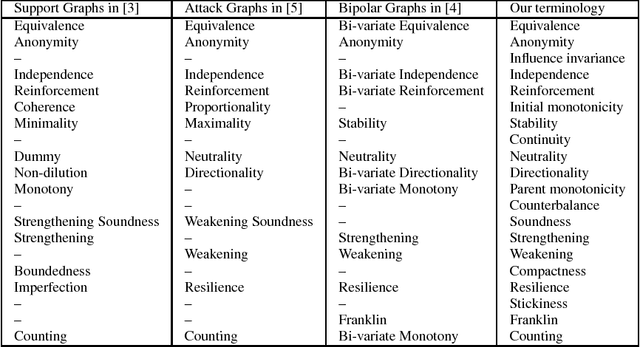

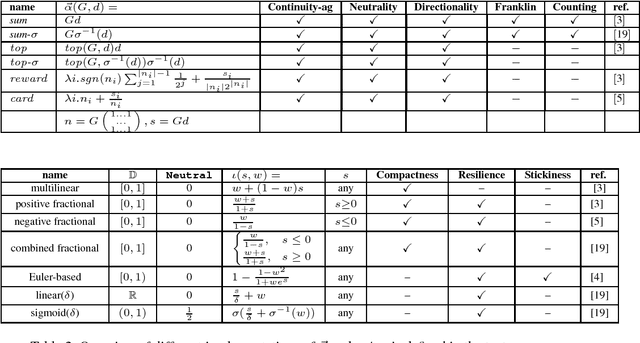
This paper addresses the semantics of weighted argumentation graphs that are bipolar, i.e. contain both attacks and supports for arguments. It builds on previous work by Amgoud, Ben-Naim et. al. We study the various characteristics of acceptability semantics that have been introduced in these works, and introduce the notion of a modular acceptability semantics. A semantics is modular if it cleanly separates aggregation of attacking and supporting arguments (for a given argument $a$) from the computation of their influence on $a$'s initial weight. We show that the various semantics for bipolar argumentation graphs from the literature may be analysed as a composition of an aggregation function with an influence function. Based on this modular framework, we prove general convergence and divergence theorems. We demonstrate that all well-behaved modular acceptability semantics converge for all acyclic graphs and that no sum-based semantics can converge for all graphs. In particular, we show divergence of Euler-based semantics (Amgoud et al.) for certain cyclic graphs. Further, we provide the first semantics for bipolar weighted graphs that converges for all graphs.
Bipolar Weighted Argumentation Graphs
Dec 23, 2016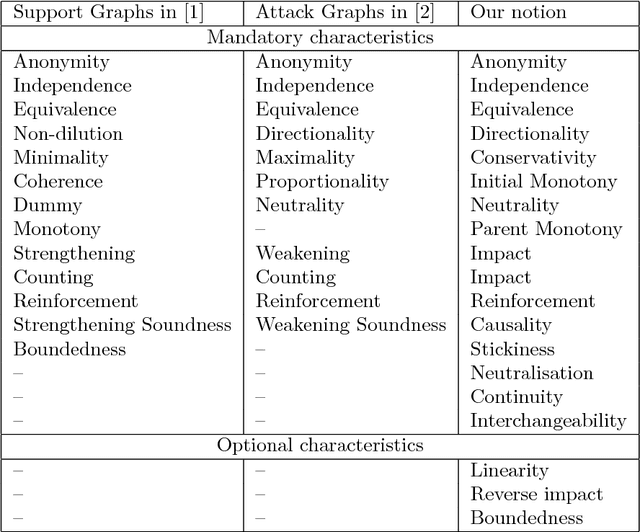
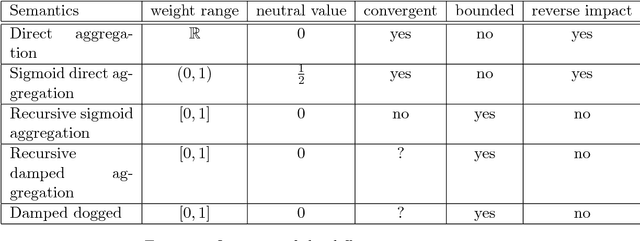
This paper discusses the semantics of weighted argumentation graphs that are biplor, i.e. contain both attacks and support graphs. The work builds on previous work by Amgoud, Ben-Naim et. al., which presents and compares several semantics for argumentation graphs that contain only supports or only attacks relationships, respectively.