 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtrapolation in Gridworld Markov-Decision Processes
Apr 14, 2020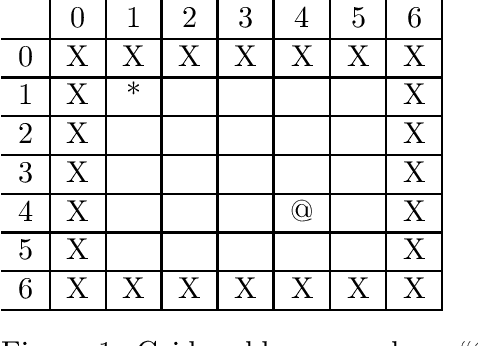


Extrapolation in reinforcement learning is the ability to generalize at test time given states that could never have occurred at training time. Here we consider four factors that lead to improved extrapolation in a simple Gridworld environment: (a) avoiding maximum Q-value (or other deterministic methods) for action choice at test time, (b) ego-centric representation of the Gridworld, (c) building rotational and mirror symmetry into the learning mechanism using rotational and mirror invariant convolution (rather than standard translation-invariant convolution), and (d) adding a maximum entropy term to the loss function to encourage equally good actions to be chosen equally often.
Plan Recognition in Stories and in Life
Mar 27, 2013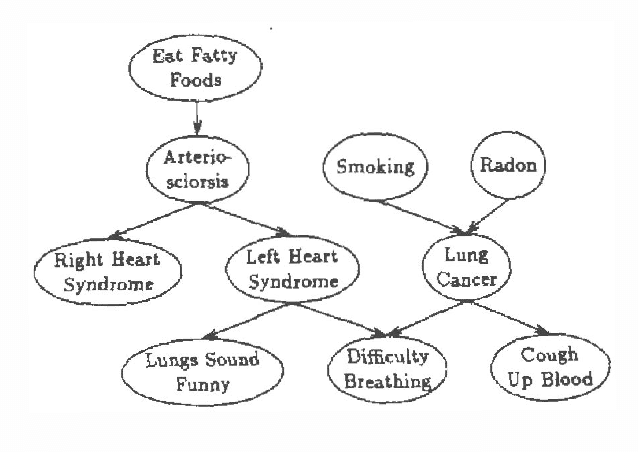
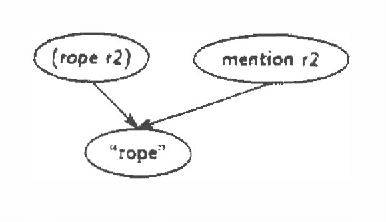
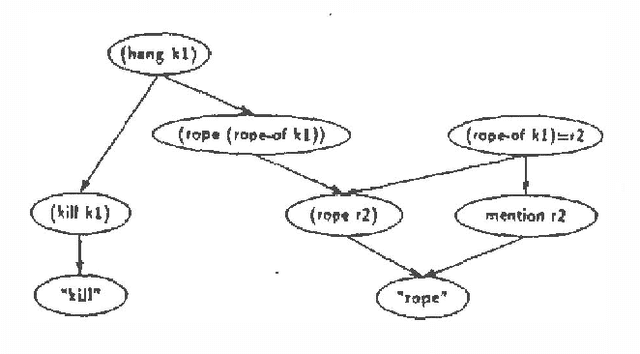
Plan recognition does not work the same way in stories and in "real life" (people tend to jump to conclusions more in stories). We present a theory of this, for the particular case of how objects in stories (or in life) influence plan recognition decisions. We provide a Bayesian network formalization of a simple first-order theory of plans, and show how a particular network parameter seems to govern the difference between "life-like" and "story-like" response. We then show why this parameter would be influenced (in the desired way) by a model of speaker (or author) topic selection which assumes that facts in stories are typically "relevant".
A New Algorithm for Finding MAP Assignments to Belief Networks
Mar 27, 2013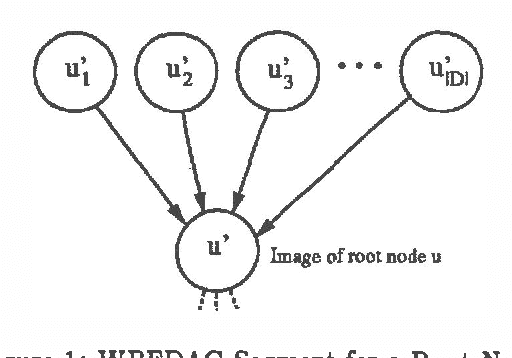
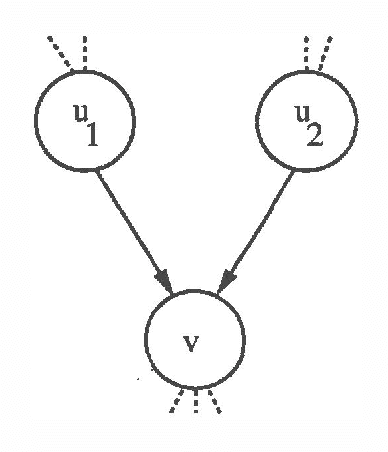
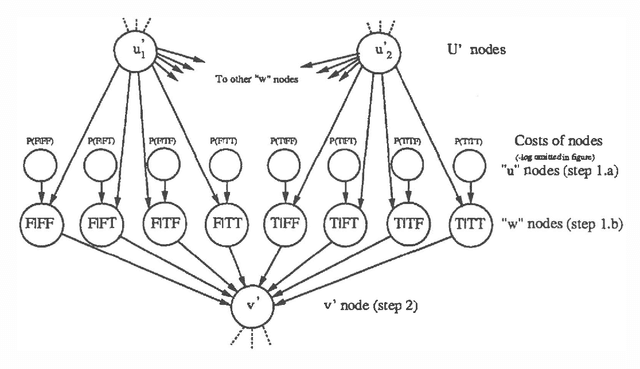
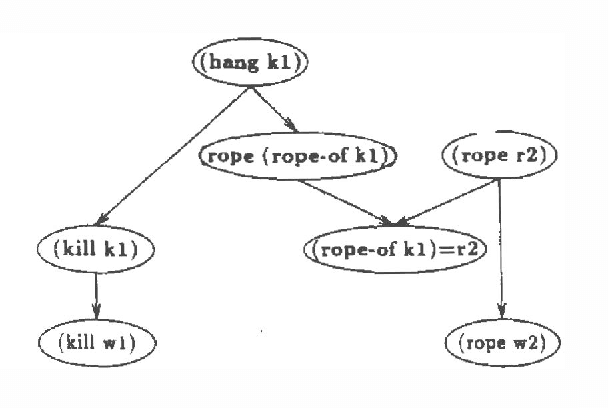
We present a new algorithm for finding maximum a-posterior) (MAP) assignments of values to belief networks. The belief network is compiled into a network consisting only of nodes with boolean (i.e. only 0 or 1) conditional probabilities. The MAP assignment is then found using a best-first search on the resulting network. We argue that, as one would anticipate, the algorithm is exponential for the general case, but only linear in the size of the network for poly trees.
Dynamic Construction of Belief Networks
Mar 27, 2013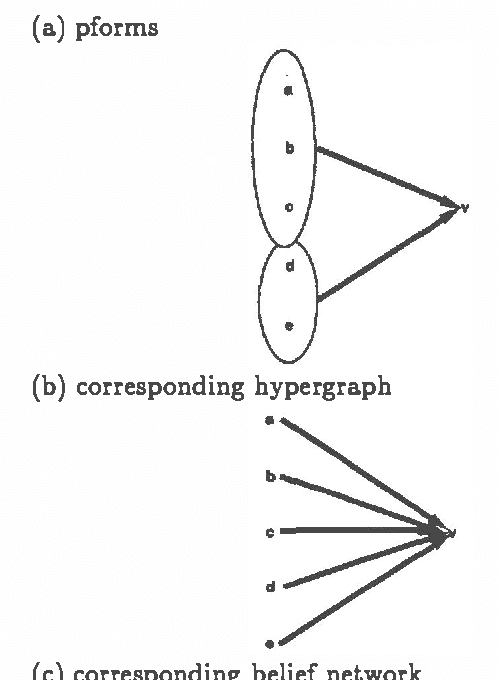
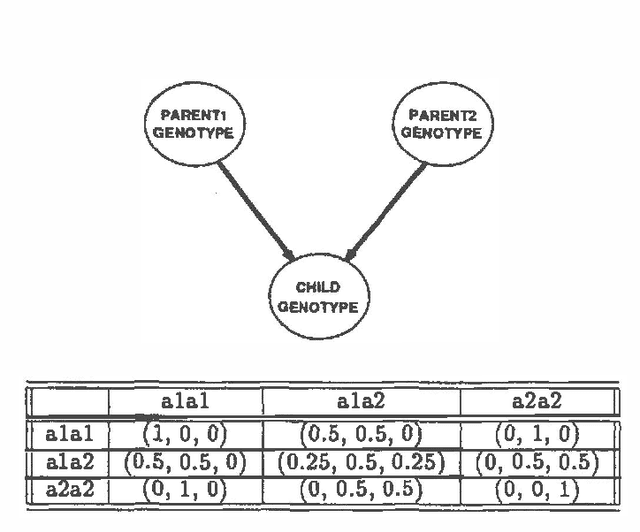
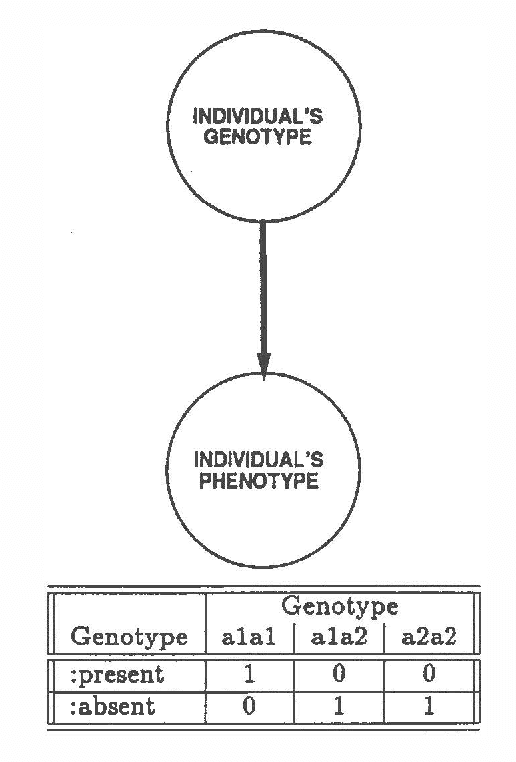
We describe a method for incrementally constructing belief networks. We have developed a network-construction language similar to a forward-chaining language using data dependencies, but with additional features for specifying distributions. Using this language, we can define parameterized classes of probabilistic models. These parameterized models make it possible to apply probabilistic reasoning to problems for which it is impractical to have a single large static model.
A Probabilistic Analysis of Marker-Passing Techniques for Plan-Recognition
Mar 20, 2013Useless paths are a chronic problem for marker-passing techniques. We use a probabilistic analysis to justify a method for quickly identifying and rejecting useless paths. Using the same analysis, we identify key conditions and assumptions necessary for marker-passing to perform well.
Measuring efficiency in high-accuracy, broad-coverage statistical parsing
Aug 24, 2000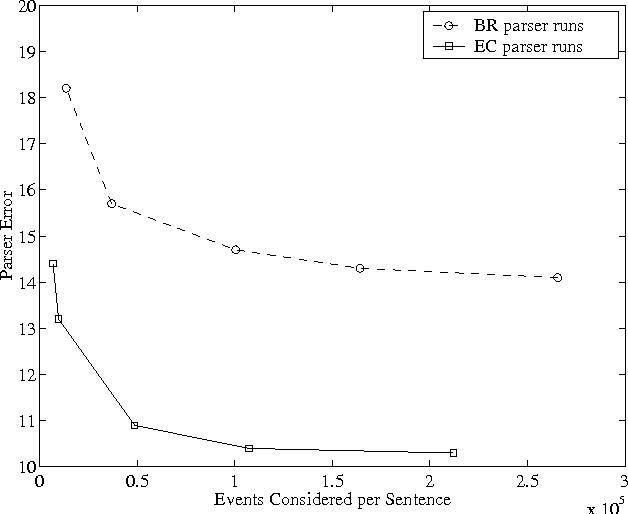
Very little attention has been paid to the comparison of efficiency between high accuracy statistical parsers. This paper proposes one machine-independent metric that is general enough to allow comparisons across very different parsing architectures. This metric, which we call ``events considered'', measures the number of ``events'', however they are defined for a particular parser, for which a probability must be calculated, in order to find the parse. It is applicable to single-pass or multi-stage parsers. We discuss the advantages of the metric, and demonstrate its usefulness by using it to compare two parsers which differ in several fundamental ways.
* 8 pages, 4 figures, 2 tables
Noun-phrase co-occurrence statistics for semi-automatic semantic lexicon construction
Aug 24, 2000
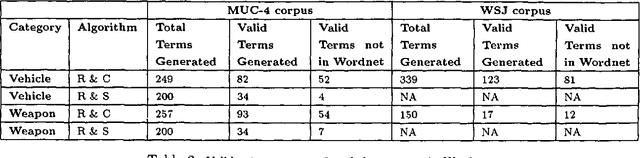
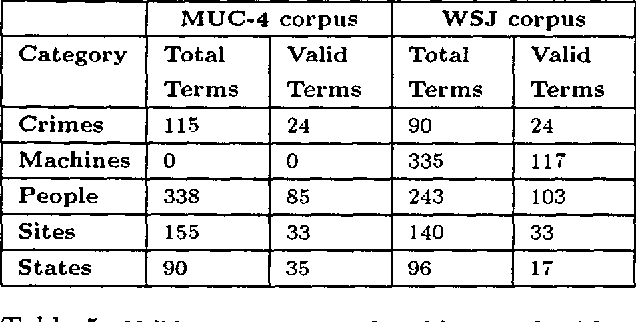
Generating semantic lexicons semi-automatically could be a great time saver, relative to creating them by hand. In this paper, we present an algorithm for extracting potential entries for a category from an on-line corpus, based upon a small set of exemplars. Our algorithm finds more correct terms and fewer incorrect ones than previous work in this area. Additionally, the entries that are generated potentially provide broader coverage of the category than would occur to an individual coding them by hand. Our algorithm finds many terms not included within Wordnet (many more than previous algorithms), and could be viewed as an ``enhancer'' of existing broad-coverage resources.
* 7 pages, 1 figure, 5 tables