Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtrapolation in Gridworld Markov-Decision Processes
Paper and Code
Apr 14, 2020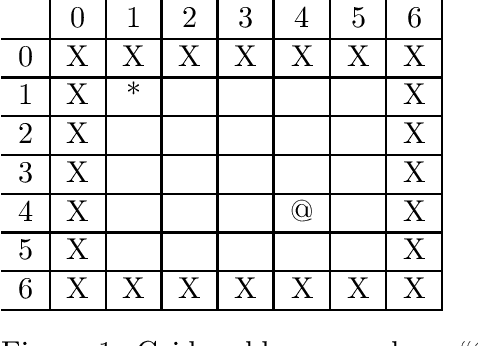
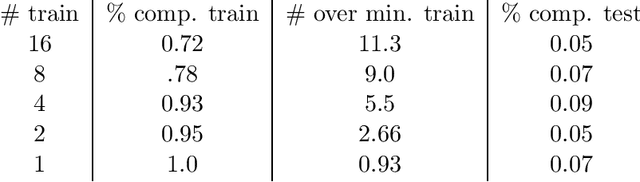


Extrapolation in reinforcement learning is the ability to generalize at test time given states that could never have occurred at training time. Here we consider four factors that lead to improved extrapolation in a simple Gridworld environment: (a) avoiding maximum Q-value (or other deterministic methods) for action choice at test time, (b) ego-centric representation of the Gridworld, (c) building rotational and mirror symmetry into the learning mechanism using rotational and mirror invariant convolution (rather than standard translation-invariant convolution), and (d) adding a maximum entropy term to the loss function to encourage equally good actions to be chosen equally often.
View paper on