Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoun-phrase co-occurrence statistics for semi-automatic semantic lexicon construction
Paper and Code
Aug 24, 2000
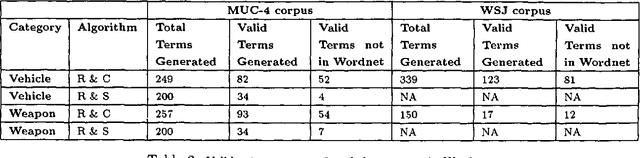
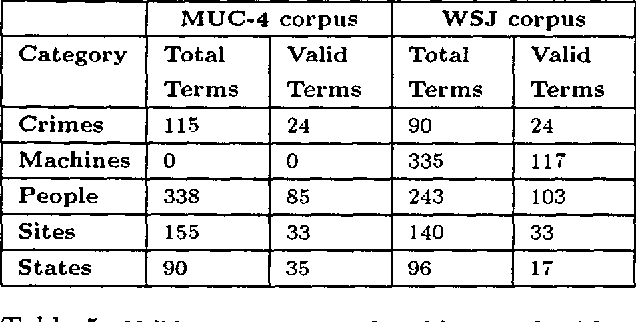
Generating semantic lexicons semi-automatically could be a great time saver, relative to creating them by hand. In this paper, we present an algorithm for extracting potential entries for a category from an on-line corpus, based upon a small set of exemplars. Our algorithm finds more correct terms and fewer incorrect ones than previous work in this area. Additionally, the entries that are generated potentially provide broader coverage of the category than would occur to an individual coding them by hand. Our algorithm finds many terms not included within Wordnet (many more than previous algorithms), and could be viewed as an ``enhancer'' of existing broad-coverage resources.
* Proceedings of the 36th Annual Meeting of the Association for
Computational Linguistics and 17th International Conference on Computational
Linguistics (COLING-ACL), 1998, pages 1110-1116 * 7 pages, 1 figure, 5 tables
View paper on