Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring efficiency in high-accuracy, broad-coverage statistical parsing
Paper and Code
Aug 24, 2000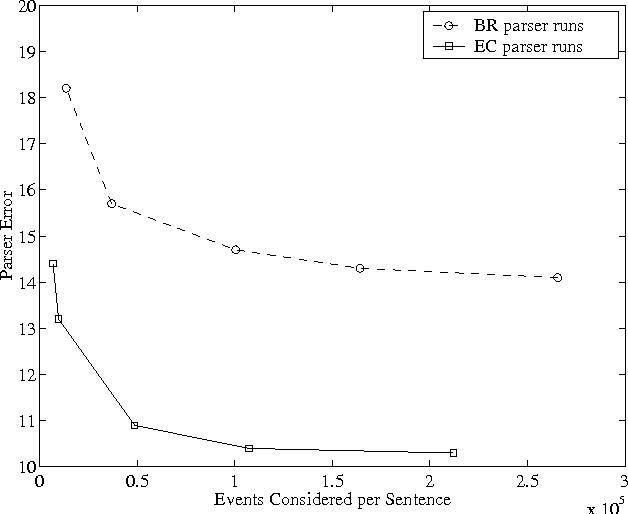
Very little attention has been paid to the comparison of efficiency between high accuracy statistical parsers. This paper proposes one machine-independent metric that is general enough to allow comparisons across very different parsing architectures. This metric, which we call ``events considered'', measures the number of ``events'', however they are defined for a particular parser, for which a probability must be calculated, in order to find the parse. It is applicable to single-pass or multi-stage parsers. We discuss the advantages of the metric, and demonstrate its usefulness by using it to compare two parsers which differ in several fundamental ways.
* Proceedings of the COLING 2000 Workshop on Efficiency in
Large-Scale Parsing Systems, 2000, pages 29-36 * 8 pages, 4 figures, 2 tables
View paper on