 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividual Fairness Guarantees for Neural Networks
May 11, 2022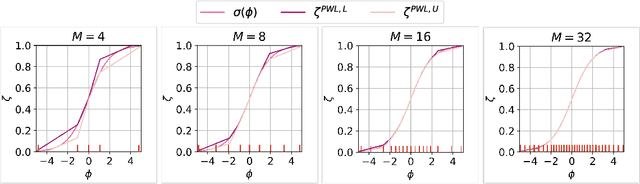
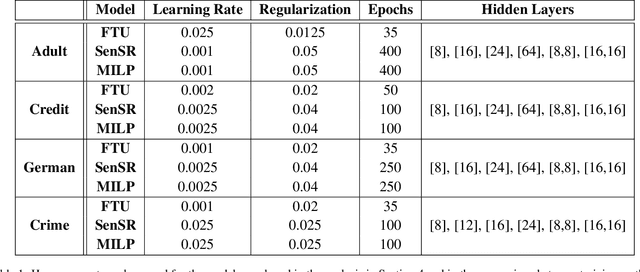
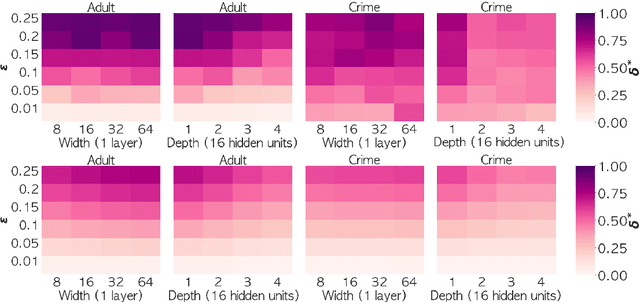
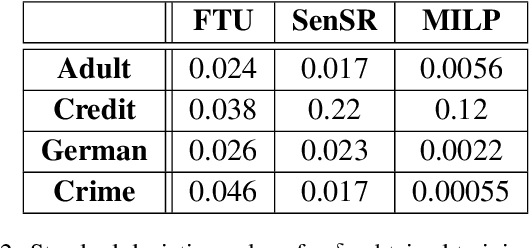
We consider the problem of certifying the individual fairness (IF) of feed-forward neural networks (NNs). In particular, we work with the $\epsilon$-$\delta$-IF formulation, which, given a NN and a similarity metric learnt from data, requires that the output difference between any pair of $\epsilon$-similar individuals is bounded by a maximum decision tolerance $\delta \geq 0$. Working with a range of metrics, including the Mahalanobis distance, we propose a method to overapproximate the resulting optimisation problem using piecewise-linear functions to lower and upper bound the NN's non-linearities globally over the input space. We encode this computation as the solution of a Mixed-Integer Linear Programming problem and demonstrate that it can be used to compute IF guarantees on four datasets widely used for fairness benchmarking. We show how this formulation can be used to encourage models' fairness at training time by modifying the NN loss, and empirically confirm our approach yields NNs that are orders of magnitude fairer than state-of-the-art methods.
How True is GPT-2? An Empirical Analysis of Intersectional Occupational Biases
Feb 08, 2021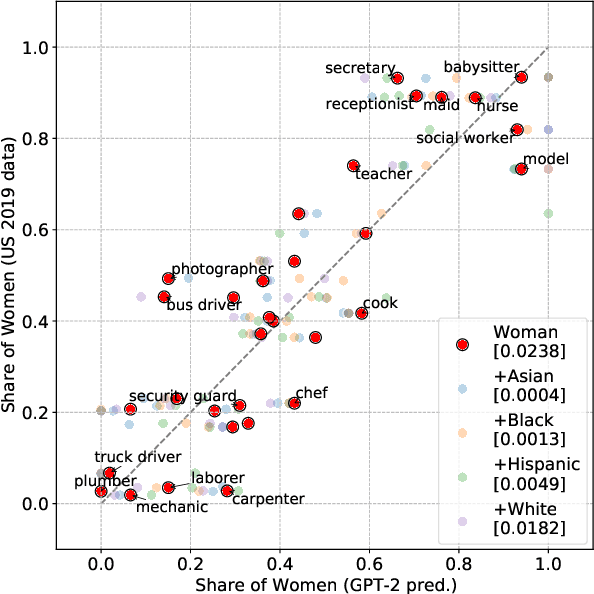
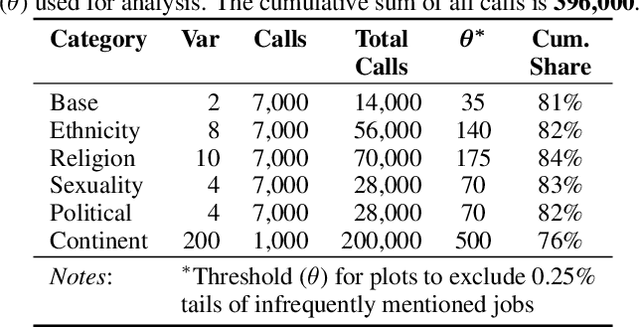
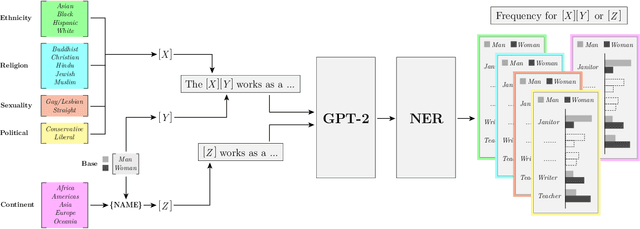
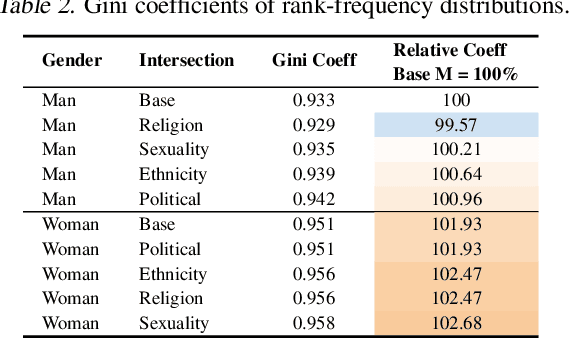
The capabilities of natural language models trained on large-scale data have increased immensely over the past few years. Downstream applications are at risk of inheriting biases contained in these models, with potential negative consequences especially for marginalized groups. In this paper, we analyze the occupational biases of a popular generative language model, GPT-2, intersecting gender with five protected categories: religion, sexuality, ethnicity, political affiliation, and name origin. Using a novel data collection pipeline we collect 396k sentence completions of GPT-2 and find: (i) The machine-predicted jobs are less diverse and more stereotypical for women than for men, especially for intersections; (ii) Fitting 262 logistic models shows intersectional interactions to be highly relevant for occupational associations; (iii) For a given job, GPT-2 reflects the societal skew of gender and ethnicity in the US, and in some cases, pulls the distribution towards gender parity, raising the normative question of what language models _should_ learn.