 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor-based oversampling for imbalanced tabular data via contrastive and adversarial learning
Mar 24, 2025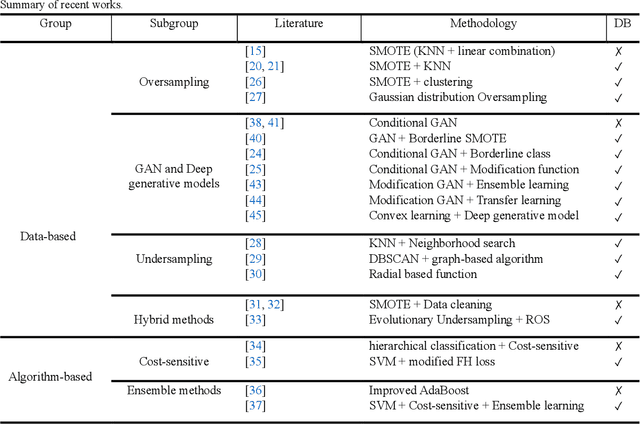
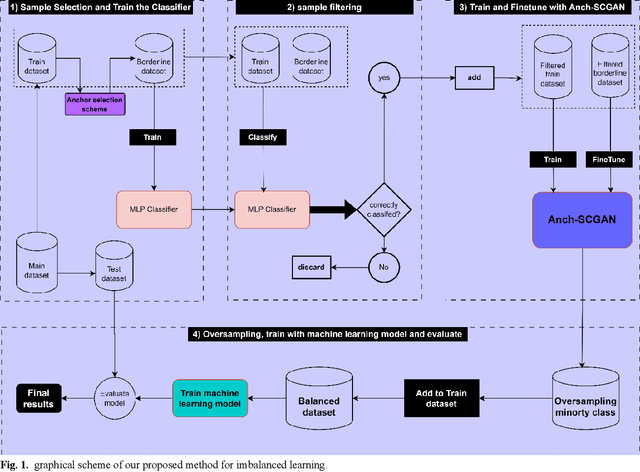

Imbalanced data represent a distribution with more frequencies of one class (majority) than the other (minority). This phenomenon occurs across various domains, such as security, medical care and human activity. In imbalanced learning, classification algorithms are typically inclined to classify the majority class accurately, resulting in artificially high accuracy rates. As a result, many minority samples are mistakenly labelled as majority-class instances, resulting in a bias that benefits the majority class. This study presents a framework based on boundary anchor samples to tackle the imbalance learning challenge. First, we select and use anchor samples to train a multilayer perceptron (MLP) classifier, which acts as a prior knowledge model and aids the adversarial and contrastive learning procedures. Then, we designed a novel deep generative model called Anchor Stabilized Conditional Generative Adversarial Network or Anch-SCGAN in short. Anch-SCGAN is supported with two generators for the minority and majority classes and a discriminator incorporating additional class-specific information from the pre-trained feature extractor MLP. In addition, we facilitate the generator's training procedure in two ways. First, we define a new generator loss function based on reprocessed anchor samples and contrastive learning. Second, we apply a scoring strategy to stabilize the adversarial training part in generators. We train Anch-SCGAN and further finetune it with anchor samples to improve the precision of the generated samples. Our experiments on 16 real-world imbalanced datasets illustrate that Anch-SCGAN outperforms the renowned methods in imbalanced learning.
SegLoc: Visual Self-supervised Learning Scheme for Dense Prediction Tasks of Security Inspection X-ray Images
Oct 21, 2023

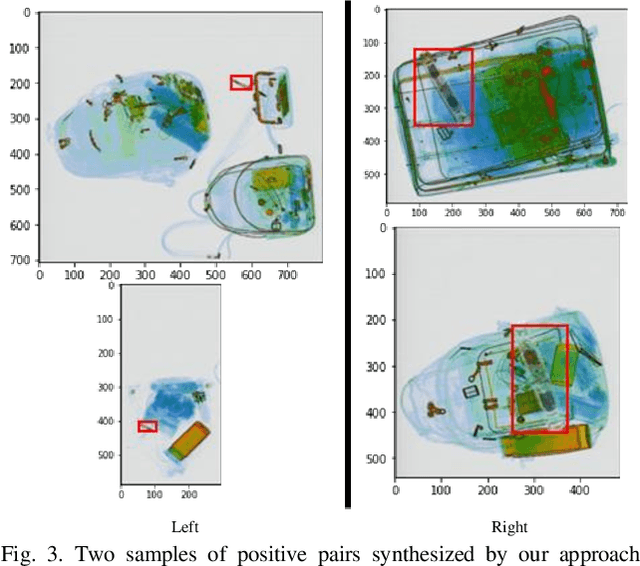
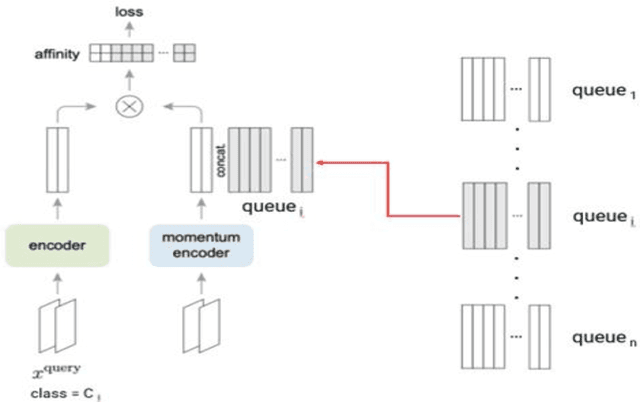
Lately, remarkable advancements of artificial intelligence have been attributed to the integration of self-supervised learning (SSL) scheme. Despite impressive achievements within natural language processing (NLP), SSL in computer vision has not been able to stay on track comparatively. Recently, integration of contrastive learning on top of existing visual SSL models has established considerable progress, thereby being able to outperform supervised counterparts. Nevertheless, the improvements were mostly limited to classification tasks; moreover, few studies have evaluated visual SSL models in real-world scenarios, while the majority considered datasets containing class-wise portrait images, notably ImageNet. Thus, here, we have considered dense prediction tasks on security inspection x-ray images to evaluate our proposed model Segmentation Localization (SegLoc). Based upon the model Instance Localization (InsLoc), our model has managed to address one of the most challenging downsides of contrastive learning, i.e., false negative pairs of query embeddings. To do so, our pre-training dataset is synthesized by cutting, transforming, then pasting labeled segments, as foregrounds, from an already existing labeled dataset (PIDray) onto instances, as backgrounds, of an unlabeled dataset (SIXray;) further, we fully harness the labels through integration of the notion, one queue per class, into MoCo-v2 memory bank, avoiding false negative pairs. Regarding the task in question, our approach has outperformed random initialization method by 3% to 6%, while having underperformed supervised initialization, in AR and AP metrics at different IoU values for 20 to 30 pre-training epochs.
Reinforcement Learning-based Mixture of Vision Transformers for Video Violence Recognition
Oct 04, 2023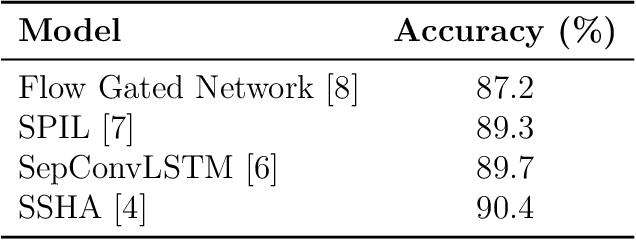
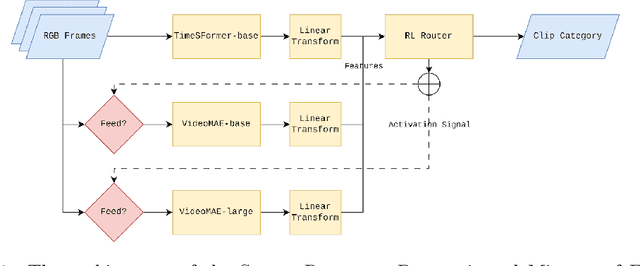
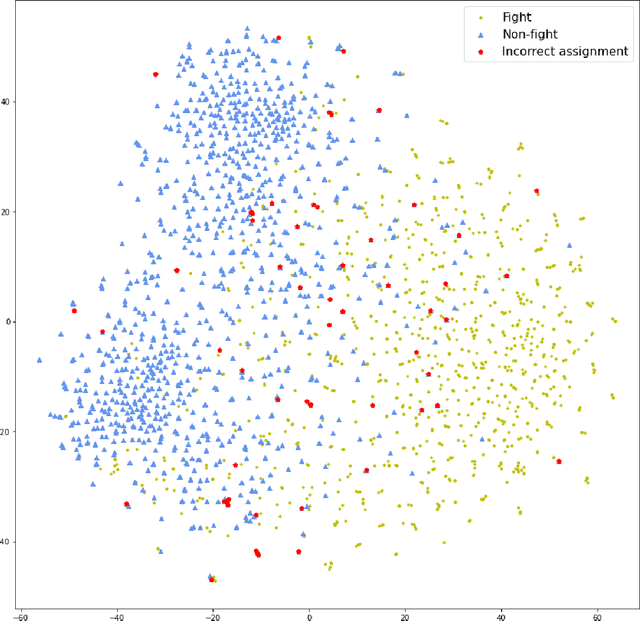
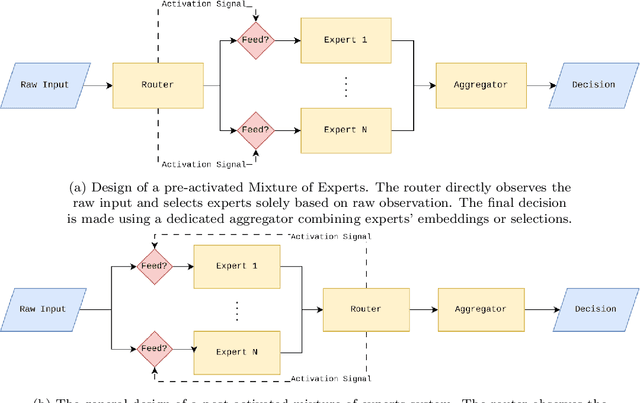
Video violence recognition based on deep learning concerns accurate yet scalable human violence recognition. Currently, most state-of-the-art video violence recognition studies use CNN-based models to represent and categorize videos. However, recent studies suggest that pre-trained transformers are more accurate than CNN-based models on various video analysis benchmarks. Yet these models are not thoroughly evaluated for video violence recognition. This paper introduces a novel transformer-based Mixture of Experts (MoE) video violence recognition system. Through an intelligent combination of large vision transformers and efficient transformer architectures, the proposed system not only takes advantage of the vision transformer architecture but also reduces the cost of utilizing large vision transformers. The proposed architecture maximizes violence recognition system accuracy while actively reducing computational costs through a reinforcement learning-based router. The empirical results show the proposed MoE architecture's superiority over CNN-based models by achieving 92.4% accuracy on the RWF dataset.
Video Violence Recognition and Localization using a Semi-Supervised Hard-Attention Model
Feb 04, 2022


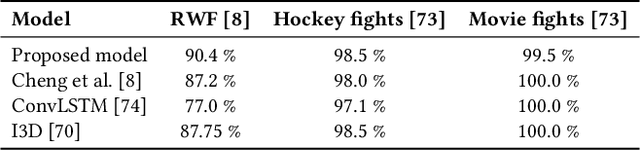
Empowering automated violence monitoring and surveillance systems amid the growing social violence and extremist activities worldwide could keep communities safe and save lives. The questionable reliability of human monitoring personnel and the increasing number of surveillance cameras makes automated artificial intelligence-based solutions compelling. Improving the current state-of-the-art deep learning approaches to video violence recognition to higher levels of accuracy and performance could enable surveillance systems to be more reliable and scalable. The main contribution of the proposed deep reinforcement learning method is to achieve state-of-the-art accuracy on RWF, Hockey, and Movies datasets while removing some of the computationally expensive processes and input features used in the previous solutions. The implementation of hard attention using a semi-supervised learning method made the proposed method capable of rough violence localization and added increased agent interpretability to the violence detection system.
Cross-Subject Transfer Learning in Human Activity Recognition Systems using Generative Adversarial Networks
Mar 29, 2019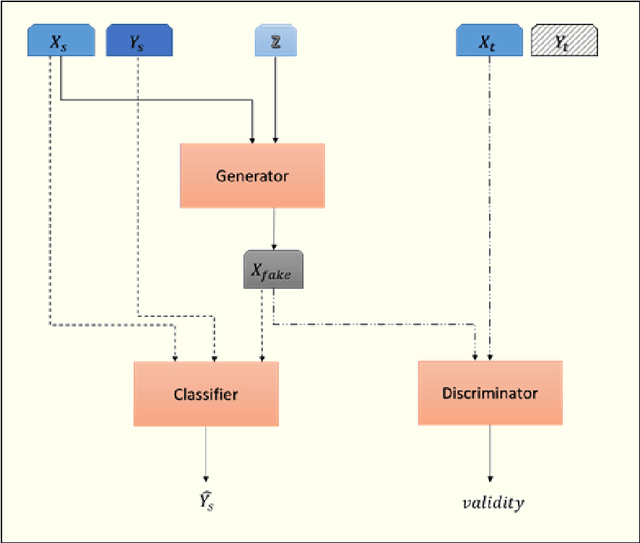

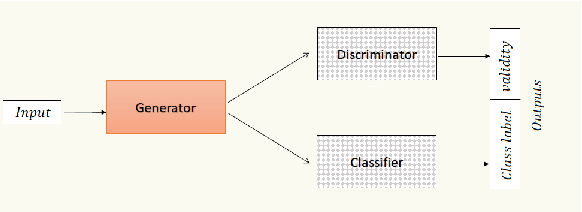
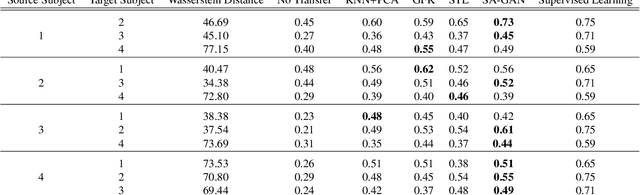
Application of intelligent systems especially in smart homes and health-related topics has been drawing more attention in the last decades. Training Human Activity Recognition (HAR) models -- as a major module -- requires a fair amount of labeled data. Despite training with large datasets, most of the existing models will face a dramatic performance drop when they are tested against unseen data from new users. Moreover, recording enough data for each new user is unviable due to the limitations and challenges of working with human users. Transfer learning techniques aim to transfer the knowledge which has been learned from the source domain (subject) to the target domain in order to decrease the models' performance loss in the target domain. This paper presents a novel method of adversarial knowledge transfer named SA-GAN stands for Subject Adaptor GAN which utilizes Generative Adversarial Network framework to perform cross-subject transfer learning in the domain of wearable sensor-based Human Activity Recognition. SA-GAN outperformed other state-of-the-art methods in more than 66% of experiments and showed the second best performance in the remaining 25% of experiments. In some cases, it reached up to 90% of the accuracy which can be obtained by supervised training over the same domain data.
Online Human Activity Recognition Employing Hierarchical Hidden Markov Models
Mar 12, 2019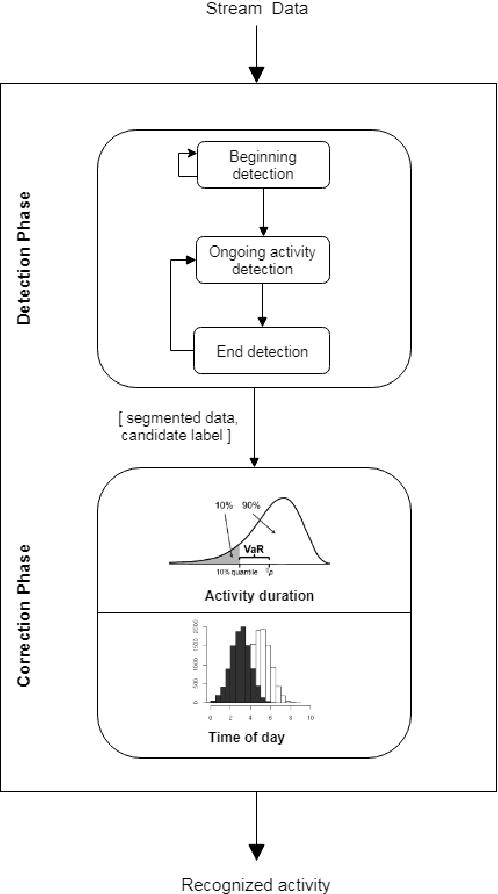
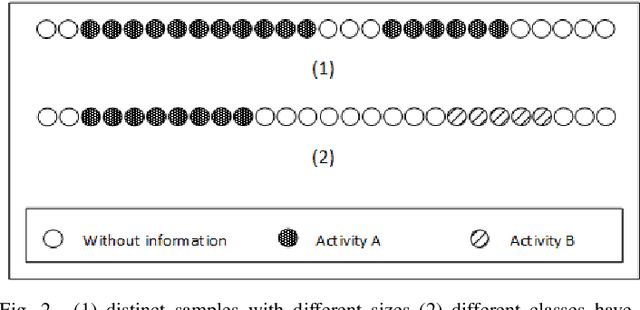
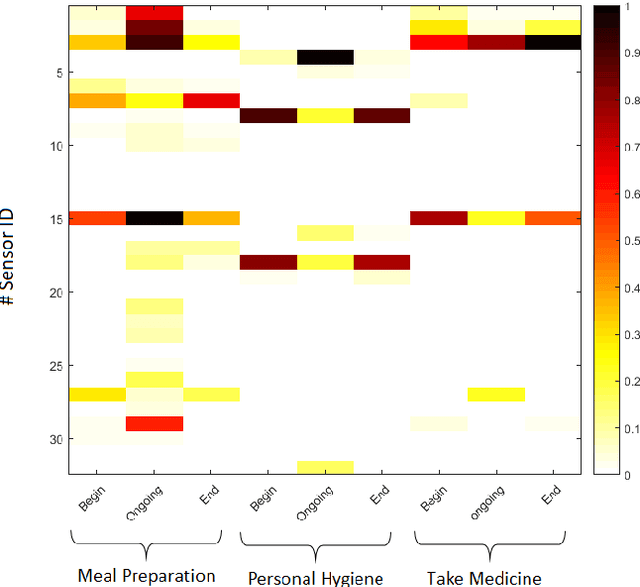
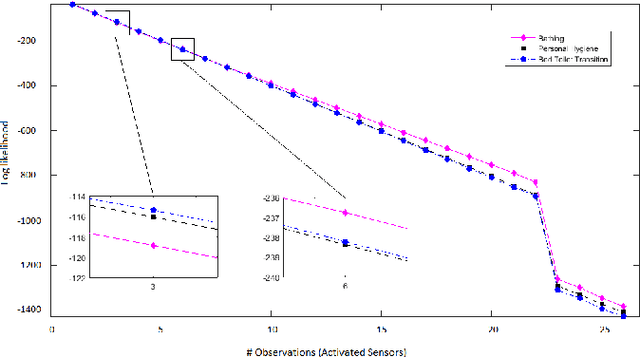
In the last few years there has been a growing interest in Human Activity Recognition~(HAR) topic. Sensor-based HAR approaches, in particular, has been gaining more popularity owing to their privacy preserving nature. Furthermore, due to the widespread accessibility of the internet, a broad range of streaming-based applications such as online HAR, has emerged over the past decades. However, proposing sufficiently robust online activity recognition approach in smart environment setting is still considered as a remarkable challenge. This paper presents a novel online application of Hierarchical Hidden Markov Model in order to detect the current activity on the live streaming of sensor events. Our method consists of two phases. In the first phase, data stream is segmented based on the beginning and ending of the activity patterns. Also, on-going activity is reported with every receiving observation. This phase is implemented using Hierarchical Hidden Markov models. The second phase is devoted to the correction of the provided label for the segmented data stream based on statistical features. The proposed model can also discover the activities that happen during another activity - so-called interrupted activities. After detecting the activity pane, the predicted label will be corrected utilizing statistical features such as time of day at which the activity happened and the duration of the activity. We validated our proposed method by testing it against two different smart home datasets and demonstrated its effectiveness, which is competing with the state-of-the-art methods.