 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning-based Mixture of Vision Transformers for Video Violence Recognition
Oct 04, 2023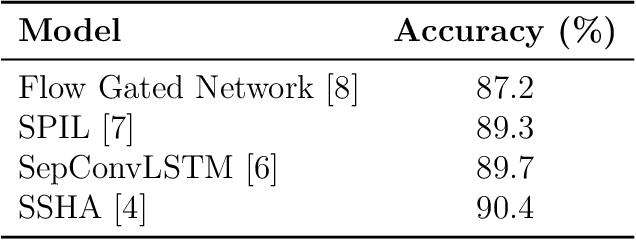
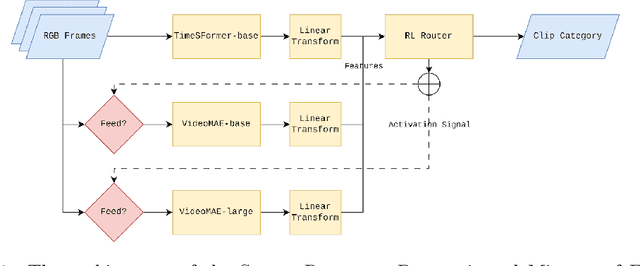
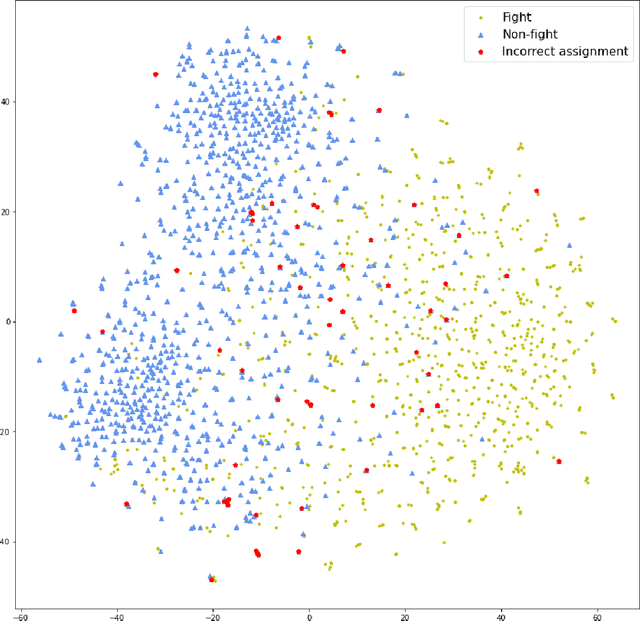
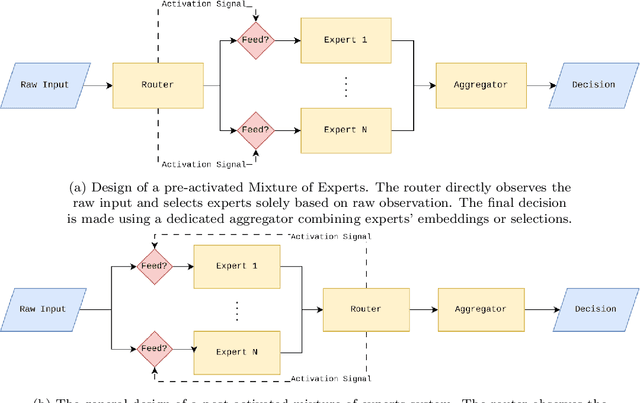
Video violence recognition based on deep learning concerns accurate yet scalable human violence recognition. Currently, most state-of-the-art video violence recognition studies use CNN-based models to represent and categorize videos. However, recent studies suggest that pre-trained transformers are more accurate than CNN-based models on various video analysis benchmarks. Yet these models are not thoroughly evaluated for video violence recognition. This paper introduces a novel transformer-based Mixture of Experts (MoE) video violence recognition system. Through an intelligent combination of large vision transformers and efficient transformer architectures, the proposed system not only takes advantage of the vision transformer architecture but also reduces the cost of utilizing large vision transformers. The proposed architecture maximizes violence recognition system accuracy while actively reducing computational costs through a reinforcement learning-based router. The empirical results show the proposed MoE architecture's superiority over CNN-based models by achieving 92.4% accuracy on the RWF dataset.
Using Active Learning Methods to Strategically Select Essays for Automated Scoring
Jan 02, 2023

Research on automated essay scoring has become increasing important because it serves as a method for evaluating students' written-responses at scale. Scalable methods for scoring written responses are needed as students migrate to online learning environments resulting in the need to evaluate large numbers of written-response assessments. The purpose of this study is to describe and evaluate three active learning methods than can be used to minimize the number of essays that must be scored by human raters while still providing the data needed to train a modern automated essay scoring system. The three active learning methods are the uncertainty-based, the topological-based, and the hybrid method. These three methods were used to select essays included as part of the Automated Student Assessment Prize competition that were then classified using a scoring model that was training with the bidirectional encoder representations from transformer language model. All three active learning methods produced strong results, with the topological-based method producing the most efficient classification. Growth rate accuracy was also evaluated. The active learning methods produced different levels of efficiency under different sample size allocations but, overall, all three methods were highly efficient and produced classifications that were similar to one another.
Video Violence Recognition and Localization using a Semi-Supervised Hard-Attention Model
Feb 04, 2022


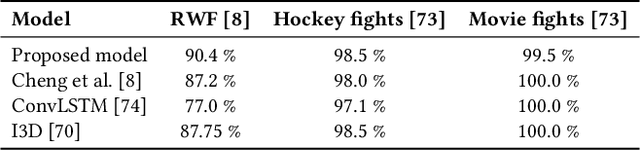
Empowering automated violence monitoring and surveillance systems amid the growing social violence and extremist activities worldwide could keep communities safe and save lives. The questionable reliability of human monitoring personnel and the increasing number of surveillance cameras makes automated artificial intelligence-based solutions compelling. Improving the current state-of-the-art deep learning approaches to video violence recognition to higher levels of accuracy and performance could enable surveillance systems to be more reliable and scalable. The main contribution of the proposed deep reinforcement learning method is to achieve state-of-the-art accuracy on RWF, Hockey, and Movies datasets while removing some of the computationally expensive processes and input features used in the previous solutions. The implementation of hard attention using a semi-supervised learning method made the proposed method capable of rough violence localization and added increased agent interpretability to the violence detection system.
Text as Environment: A Deep Reinforcement Learning Text Readability Assessment Model
Dec 15, 2019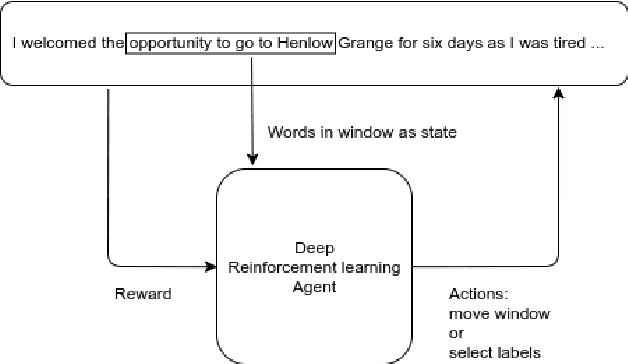
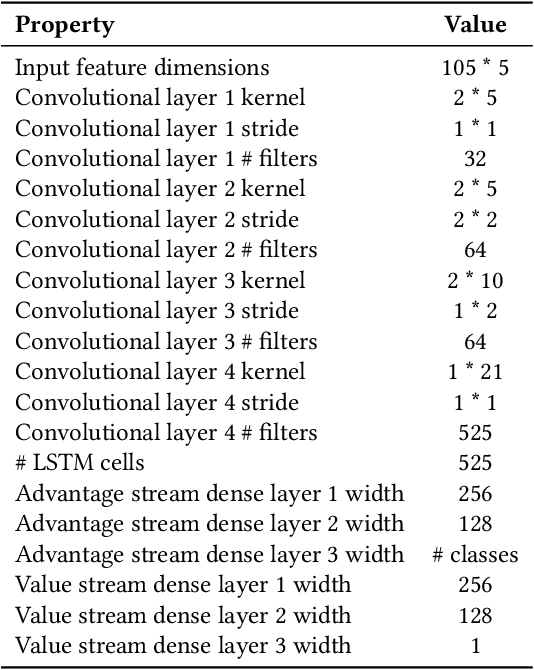
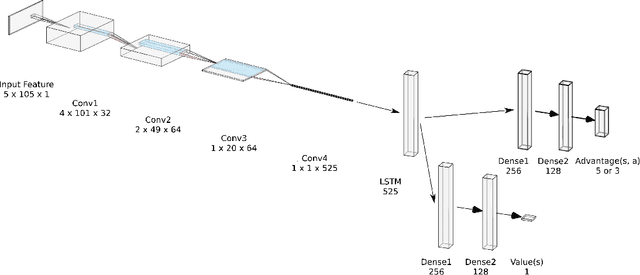
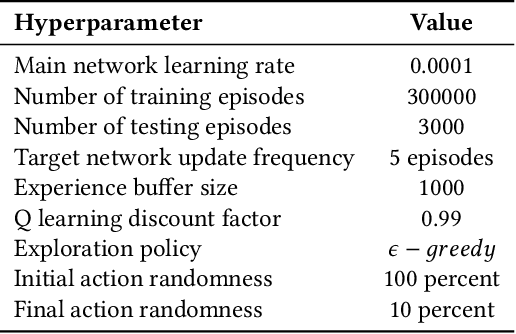
Evaluating the readability of a text can significantly facilitate the precise expression of information in a written form. The formulation of text readability assessment demands the identification of meaningful properties of the text and correct conversion of features to the right readability level. Sophisticated features and models are being used to evaluate the comprehensibility of texts accurately. Still, these models are challenging to implement, heavily language-dependent, and do not perform well on short texts. Deep reinforcement learning models are demonstrated to be helpful in further improvement of state-of-the-art text readability assessment models. The main contributions of the proposed approach are the automation of feature extraction, loosening the tight language dependency of text readability assessment task, and efficient use of text by finding the minimum portion of a text required to assess its readability. The experiments on Weebit, Cambridge Exams, and Persian readability datasets display the model's state-of-the-art precision, efficiency, and the capability to be applied to other languages.
A Machine Learning Approach to Persian Text Readability Assessment Using a Crowdsourced Dataset
Oct 19, 2018


An automated approach to text readability assessment is essential to a language and can be a powerful tool for improving the understandability of texts written and published in that language. However, the Persian language, which is spoken by over 110 million speakers, lacks such a system. Unlike other languages such as English, French, and Chinese, very limited research studies have been carried out to build an accurate and reliable text readability assessment system for the Persian language. In the present research, the first Persian dataset for text readability assessment was gathered and the first model for Persian text readability assessment using machine learning was introduced. The experiments showed that this model was accurate and could assess the readability of Persian texts with a high degree of confidence. The results of this study can be used in a number of applications such as medical and educational text readability evaluation and have the potential to be the cornerstone of future studies in Persian text readability assessment.