 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText as Environment: A Deep Reinforcement Learning Text Readability Assessment Model
Paper and Code
Dec 15, 2019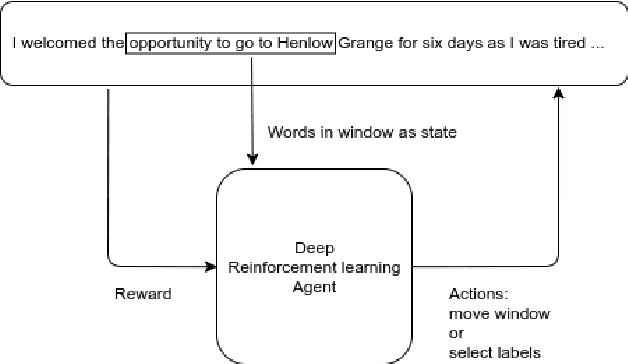
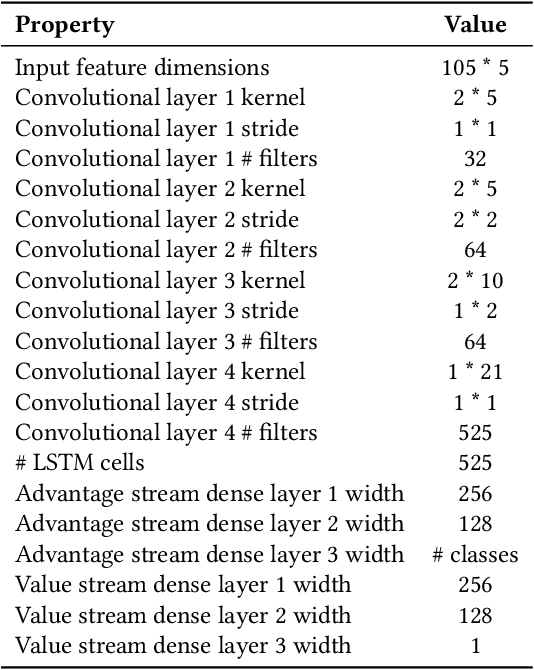
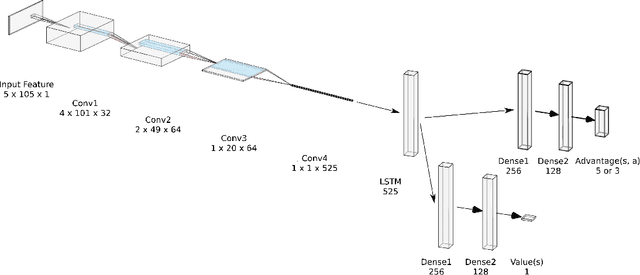
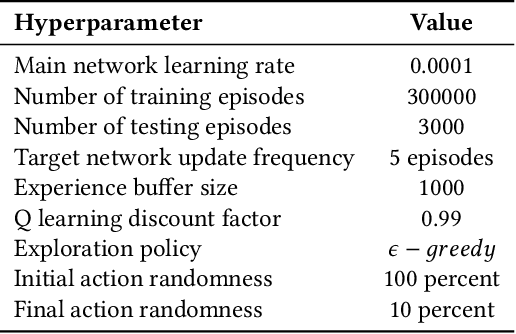
Evaluating the readability of a text can significantly facilitate the precise expression of information in a written form. The formulation of text readability assessment demands the identification of meaningful properties of the text and correct conversion of features to the right readability level. Sophisticated features and models are being used to evaluate the comprehensibility of texts accurately. Still, these models are challenging to implement, heavily language-dependent, and do not perform well on short texts. Deep reinforcement learning models are demonstrated to be helpful in further improvement of state-of-the-art text readability assessment models. The main contributions of the proposed approach are the automation of feature extraction, loosening the tight language dependency of text readability assessment task, and efficient use of text by finding the minimum portion of a text required to assess its readability. The experiments on Weebit, Cambridge Exams, and Persian readability datasets display the model's state-of-the-art precision, efficiency, and the capability to be applied to other languages.