 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning-based Mixture of Vision Transformers for Video Violence Recognition
Paper and Code
Oct 04, 2023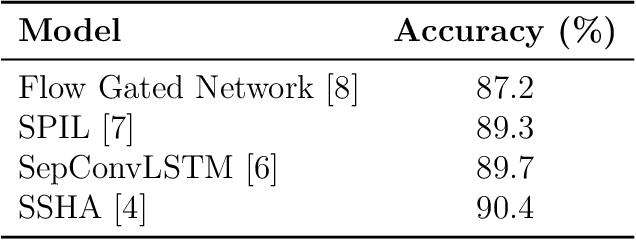
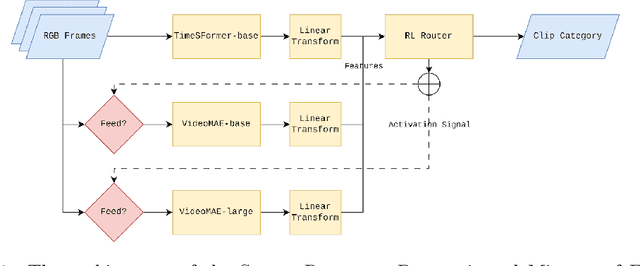
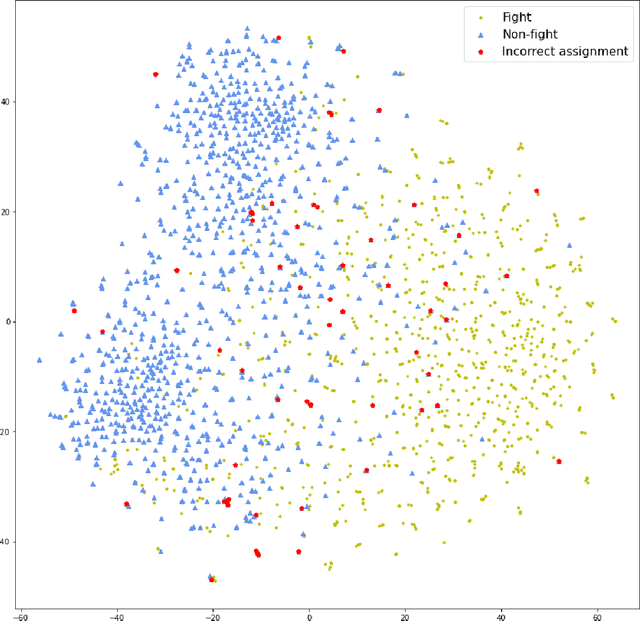
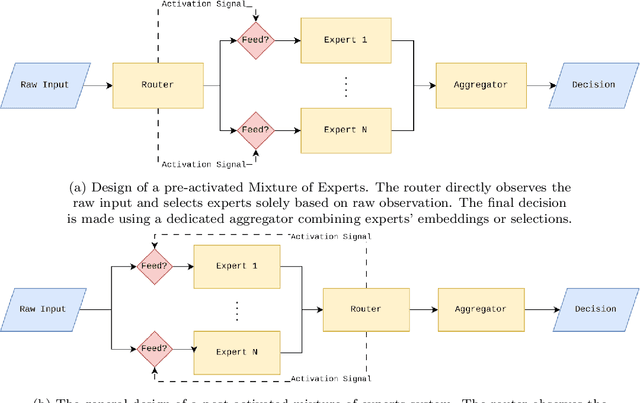
Video violence recognition based on deep learning concerns accurate yet scalable human violence recognition. Currently, most state-of-the-art video violence recognition studies use CNN-based models to represent and categorize videos. However, recent studies suggest that pre-trained transformers are more accurate than CNN-based models on various video analysis benchmarks. Yet these models are not thoroughly evaluated for video violence recognition. This paper introduces a novel transformer-based Mixture of Experts (MoE) video violence recognition system. Through an intelligent combination of large vision transformers and efficient transformer architectures, the proposed system not only takes advantage of the vision transformer architecture but also reduces the cost of utilizing large vision transformers. The proposed architecture maximizes violence recognition system accuracy while actively reducing computational costs through a reinforcement learning-based router. The empirical results show the proposed MoE architecture's superiority over CNN-based models by achieving 92.4% accuracy on the RWF dataset.