 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegLoc: Visual Self-supervised Learning Scheme for Dense Prediction Tasks of Security Inspection X-ray Images
Paper and Code
Oct 21, 2023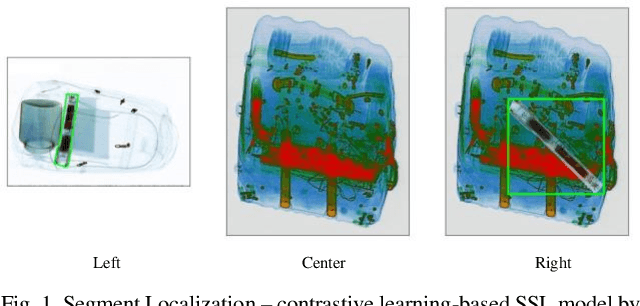

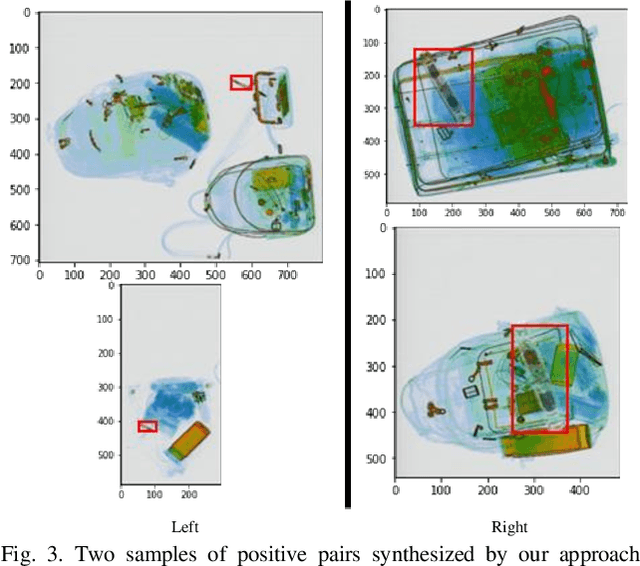
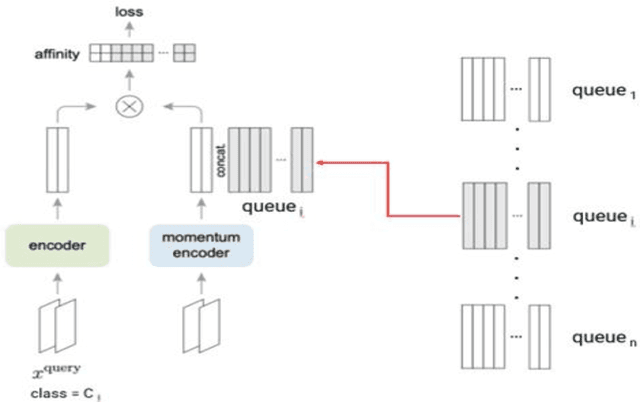
Lately, remarkable advancements of artificial intelligence have been attributed to the integration of self-supervised learning (SSL) scheme. Despite impressive achievements within natural language processing (NLP), SSL in computer vision has not been able to stay on track comparatively. Recently, integration of contrastive learning on top of existing visual SSL models has established considerable progress, thereby being able to outperform supervised counterparts. Nevertheless, the improvements were mostly limited to classification tasks; moreover, few studies have evaluated visual SSL models in real-world scenarios, while the majority considered datasets containing class-wise portrait images, notably ImageNet. Thus, here, we have considered dense prediction tasks on security inspection x-ray images to evaluate our proposed model Segmentation Localization (SegLoc). Based upon the model Instance Localization (InsLoc), our model has managed to address one of the most challenging downsides of contrastive learning, i.e., false negative pairs of query embeddings. To do so, our pre-training dataset is synthesized by cutting, transforming, then pasting labeled segments, as foregrounds, from an already existing labeled dataset (PIDray) onto instances, as backgrounds, of an unlabeled dataset (SIXray;) further, we fully harness the labels through integration of the notion, one queue per class, into MoCo-v2 memory bank, avoiding false negative pairs. Regarding the task in question, our approach has outperformed random initialization method by 3% to 6%, while having underperformed supervised initialization, in AR and AP metrics at different IoU values for 20 to 30 pre-training epochs.