 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Non-Parametric Choice Models
Aug 05, 2022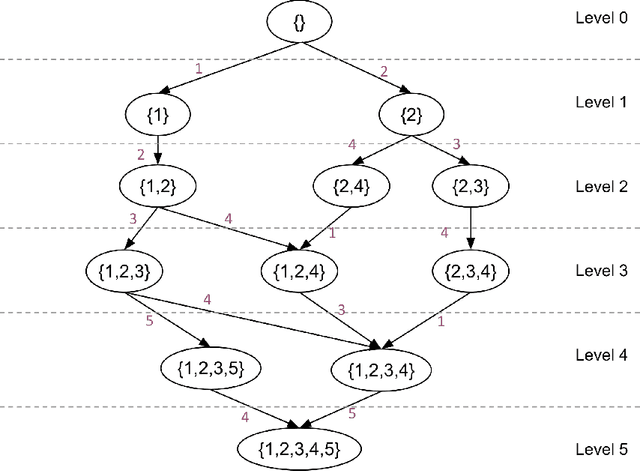


We study the problem of actively learning a non-parametric choice model based on consumers' decisions. We present a negative result showing that such choice models may not be identifiable. To overcome the identifiability problem, we introduce a directed acyclic graph (DAG) representation of the choice model, which in a sense captures as much information about the choice model as could information-theoretically be identified. We then consider the problem of learning an approximation to this DAG representation in an active-learning setting. We design an efficient active-learning algorithm to estimate the DAG representation of the non-parametric choice model, which runs in polynomial time when the set of frequent rankings is drawn uniformly at random. Our algorithm learns the distribution over the most popular items of frequent preferences by actively and repeatedly offering assortments of items and observing the item chosen. We show that our algorithm can better recover a set of frequent preferences on both a synthetic and publicly available dataset on consumers' preferences, compared to the corresponding non-active learning estimation algorithms. This demonstrates the value of our algorithm and active-learning approaches more generally.
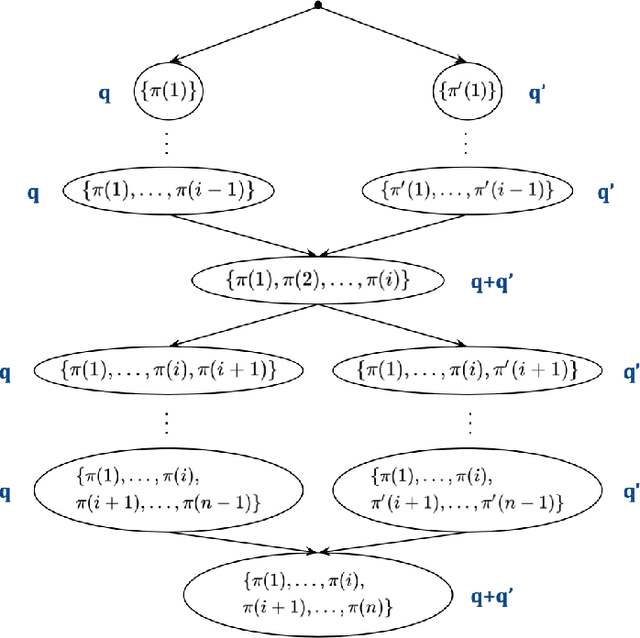
Adversarial Online Learning with Changing Action Sets: Efficient Algorithms with Approximate Regret Bounds
Mar 07, 2020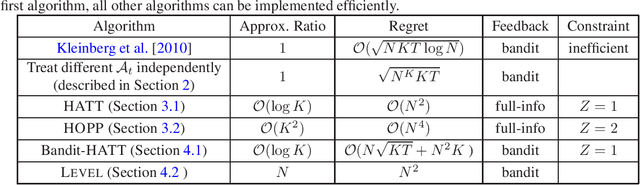
We revisit the problem of online learning with sleeping experts/bandits: in each time step, only a subset of the actions are available for the algorithm to choose from (and learn about). The work of Kleinberg et al. [2010] showed that there exist no-regret algorithms which perform no worse than the best ranking of actions asymptotically. Unfortunately, achieving this regret bound appears computationally hard: Kanade and Steinke [2014] showed that achieving this no-regret performance is at least as hard as PAC-learning DNFs, a notoriously difficult problem. In the present work, we relax the original problem and study computationally efficient no-approximate-regret algorithms: such algorithms may exceed the optimal cost by a multiplicative constant in addition to the additive regret. We give an algorithm that provides a no-approximate-regret guarantee for the general sleeping expert/bandit problems. For several canonical special cases of the problem, we give algorithms with significantly better approximation ratios; these algorithms also illustrate different techniques for achieving no-approximate-regret guarantees.
The Complexity of Interactively Learning a Stable Matching by Trial and Error
Feb 18, 2020In a stable matching setting, we consider a query model that allows for an interactive learning algorithm to make precisely one type of query: proposing a matching, the response to which is either that the proposed matching is stable, or a blocking pair (chosen adversarially) indicating that this matching is unstable. For one-to-one matching markets, our main result is an essentially tight upper bound of $O(n^2\log n)$ on the deterministic query complexity of interactively learning a stable matching in this coarse query model, along with an efficient randomized algorithm that achieves this query complexity with high probability. For many-to-many matching markets in which participants have responsive preferences, we first give an interactive learning algorithm whose query complexity and running time are polynomial in the size of the market if the maximum quota of each agent is bounded; our main result for many-to-many markets is that the deterministic query complexity can be made polynomial (more specifically, $O(n^3 \log n)$) in the size of the market even for arbitrary (e.g., linear in the market size) quotas.
A General Framework for Robust Interactive Learning
Oct 16, 2017We propose a general framework for interactively learning models, such as (binary or non-binary) classifiers, orderings/rankings of items, or clusterings of data points. Our framework is based on a generalization of Angluin's equivalence query model and Littlestone's online learning model: in each iteration, the algorithm proposes a model, and the user either accepts it or reveals a specific mistake in the proposal. The feedback is correct only with probability $p > 1/2$ (and adversarially incorrect with probability $1 - p$), i.e., the algorithm must be able to learn in the presence of arbitrary noise. The algorithm's goal is to learn the ground truth model using few iterations. Our general framework is based on a graph representation of the models and user feedback. To be able to learn efficiently, it is sufficient that there be a graph $G$ whose nodes are the models and (weighted) edges capture the user feedback, with the property that if $s, s^*$ are the proposed and target models, respectively, then any (correct) user feedback $s'$ must lie on a shortest $s$-$s^*$ path in $G$. Under this one assumption, there is a natural algorithm reminiscent of the Multiplicative Weights Update algorithm, which will efficiently learn $s^*$ even in the presence of noise in the user's feedback. From this general result, we rederive with barely any extra effort classic results on learning of classifiers and a recent result on interactive clustering; in addition, we easily obtain new interactive learning algorithms for ordering/ranking.