 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Online Learning with Changing Action Sets: Efficient Algorithms with Approximate Regret Bounds
Paper and Code
Mar 07, 2020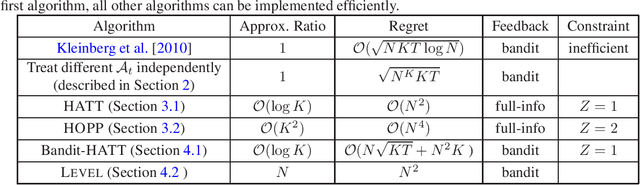
We revisit the problem of online learning with sleeping experts/bandits: in each time step, only a subset of the actions are available for the algorithm to choose from (and learn about). The work of Kleinberg et al. [2010] showed that there exist no-regret algorithms which perform no worse than the best ranking of actions asymptotically. Unfortunately, achieving this regret bound appears computationally hard: Kanade and Steinke [2014] showed that achieving this no-regret performance is at least as hard as PAC-learning DNFs, a notoriously difficult problem. In the present work, we relax the original problem and study computationally efficient no-approximate-regret algorithms: such algorithms may exceed the optimal cost by a multiplicative constant in addition to the additive regret. We give an algorithm that provides a no-approximate-regret guarantee for the general sleeping expert/bandit problems. For several canonical special cases of the problem, we give algorithms with significantly better approximation ratios; these algorithms also illustrate different techniques for achieving no-approximate-regret guarantees.