 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDACov: A Deeper Analysis of Data Augmentation on the Computed Tomography Segmentation Problem
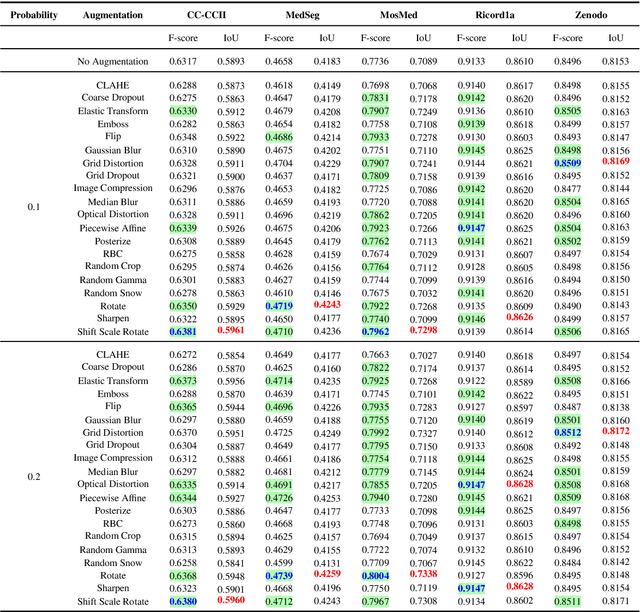
Mar 10, 2023Due to the COVID-19 global pandemic, computer-assisted diagnoses of medical images have gained much attention, and robust methods of semantic segmentation of Computed Tomography (CT) images have become highly desirable. In this work, we present a deeper analysis of how data augmentation techniques improve segmentation performance on this problem. We evaluate 20 traditional augmentation techniques on five public datasets. Six different probabilities of applying each augmentation technique on an image were evaluated. We also assess a different training methodology where the training subsets are combined into a single larger set. All networks were evaluated through a 5-fold cross-validation strategy, resulting in over 4,600 experiments. We also propose a novel data augmentation technique based on Generative Adversarial Networks (GANs) to create new healthy and unhealthy lung CT images, evaluating four variations of our approach with the same six probabilities of the traditional methods. Our findings show that GAN-based techniques and spatial-level transformations are the most promising for improving the learning of deep models on this problem, with the StarGANv2 + F with a probability of 0.3 achieving the highest F-score value on the Ricord1a dataset in the unified training strategy. Our code is publicly available at https://github.com/VRI-UFPR/DACov2022
Light In The Black: An Evaluation of Data Augmentation Techniques for COVID-19 CT's Semantic Segmentation
May 19, 2022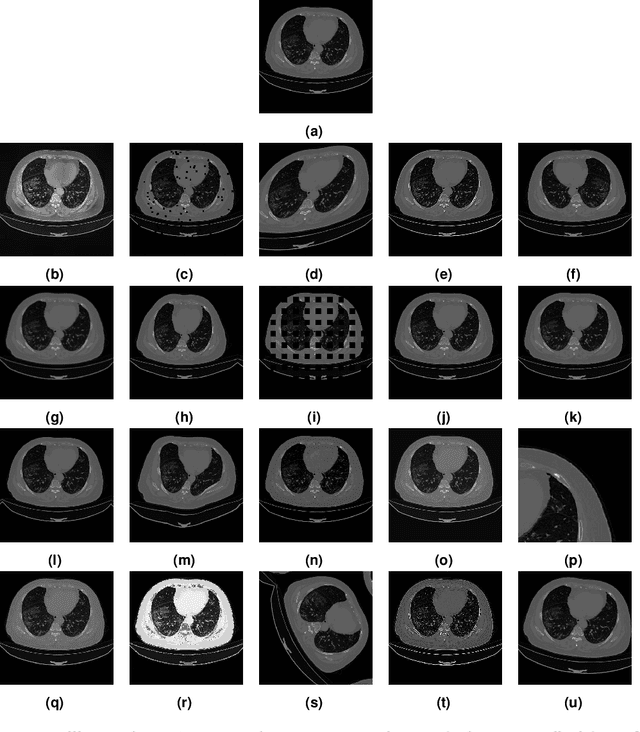


With the COVID-19 global pandemic, computer-assisted diagnoses of medical images have gained much attention, and robust methods of Semantic Segmentation of Computed Tomography (CT) became highly desirable. Semantic Segmentation of CT is one of many research fields of automatic detection of COVID-19 and has been widely explored since the COVID-19 outbreak. In this work, we propose an extensive analysis of how different data augmentation techniques improve the training of encoder-decoder neural networks on this problem. Twenty different data augmentation techniques were evaluated on five different datasets. Each dataset was validated through a five-fold cross-validation strategy, thus resulting in over 3,000 experiments. Our findings show that spatial level transformations are the most promising to improve the learning of neural networks on this problem.
Spark in the Dark: Evaluating Encoder-Decoder Pairs for COVID-19 CT's Semantic Segmentation
Sep 30, 2021


With the COVID-19 global pandemic, computerassisted diagnoses of medical images have gained a lot of attention, and robust methods of Semantic Segmentation of Computed Tomography (CT) turned highly desirable. Semantic Segmentation of CT is one of many research fields of automatic detection of Covid-19 and was widely explored since the Covid19 outbreak. In the robotic field, Semantic Segmentation of organs and CTs are widely used in robots developed for surgery tasks. As new methods and new datasets are proposed quickly, it becomes apparent the necessity of providing an extensive evaluation of those methods. To provide a standardized comparison of different architectures across multiple recently proposed datasets, we propose in this paper an extensive benchmark of multiple encoders and decoders with a total of 120 architectures evaluated in five datasets, with each dataset being validated through a five-fold cross-validation strategy, totaling 3.000 experiments. To the best of our knowledge, this is the largest evaluation in number of encoders, decoders, and datasets proposed in the field of Covid-19 CT segmentation.
BEyond observation: an approach for ObjectNav
Jun 21, 2021

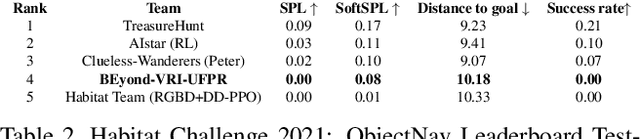
With the rise of automation, unmanned vehicles became a hot topic both as commercial products and as a scientific research topic. It composes a multi-disciplinary field of robotics that encompasses embedded systems, control theory, path planning, Simultaneous Localization and Mapping (SLAM), scene reconstruction, and pattern recognition. In this work, we present our exploratory research of how sensor data fusion and state-of-the-art machine learning algorithms can perform the Embodied Artificial Intelligence (E-AI) task called Visual Semantic Navigation. This task, a.k.a Object-Goal Navigation (ObjectNav) consists of autonomous navigation using egocentric visual observations to reach an object belonging to the target semantic class without prior knowledge of the environment. Our method reached fourth place on the Habitat Challenge 2021 ObjectNav on the Minival phase and the Test-Standard Phase.
IDA: Improved Data Augmentation Applied to Salient Object Detection
Sep 18, 2020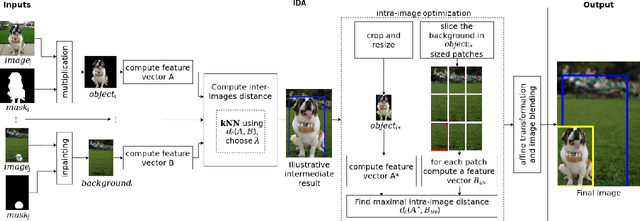



In this paper, we present an Improved Data Augmentation (IDA) technique focused on Salient Object Detection (SOD). Standard data augmentation techniques proposed in the literature, such as image cropping, rotation, flipping, and resizing, only generate variations of the existing examples, providing a limited generalization. Our method combines image inpainting, affine transformations, and the linear combination of different generated background images with salient objects extracted from labeled data. Our proposed technique enables more precise control of the object's position and size while preserving background information. The background choice is based on an inter-image optimization, while object size follows a uniform random distribution within a specified interval, and the object position is intra-image optimal. We show that our method improves the segmentation quality when used for training state-of-the-art neural networks on several famous datasets of the SOD field. Combining our method with others surpasses traditional techniques such as horizontal-flip in 0.52% for F-measure and 1.19% for Precision. We also provide an evaluation in 7 different SOD datasets, with 9 distinct evaluation metrics and an average ranking of the evaluated methods.
For the Thrill of it All: A bridge among Linux, Robot Operating System, Android and Unmanned Aerial Vehicles
Jun 20, 2020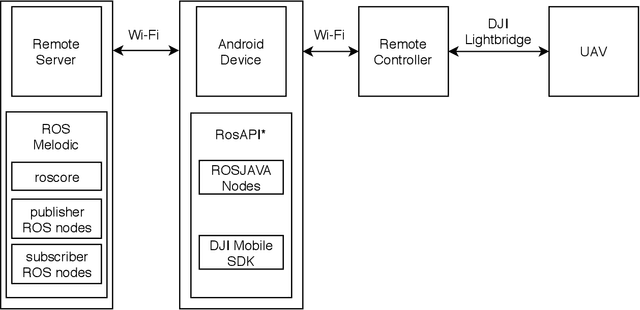
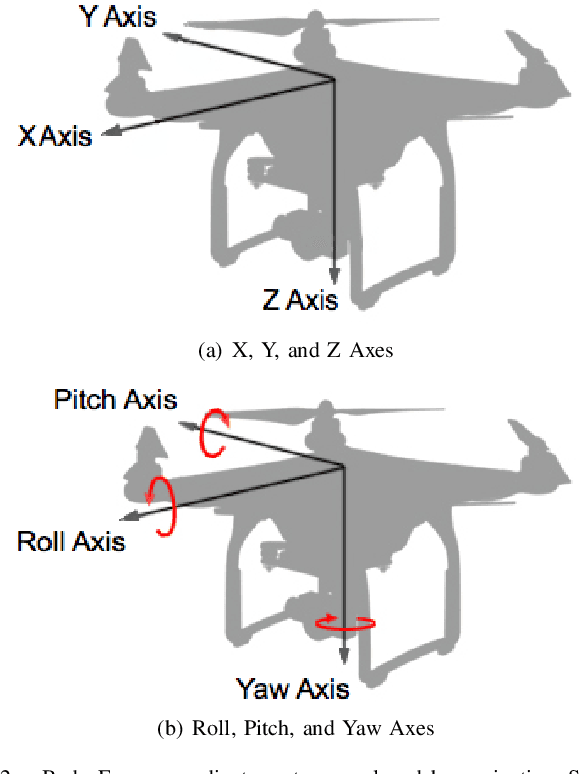

Civilian Unmanned Aerial Vehicles (UAVs) are becoming more accessible for domestic use. Currently, UAV manufacturer DJI dominates the market, and their drones have been used for a wide range of applications. Model lines such as the Phantom can be applied for autonomous navigation where Global Positioning System (GPS) signals are not reliable, with the aid of Simultaneous Localization and Mapping (SLAM), such as monocular Visual SLAM. In this work, we propose a bridge among different systems, such as Linux, Robot Operating System (ROS), Android, and UAVs as an open-source framework, where the gimbal camera recording can be streamed to a remote server, supporting the implementation of an autopilot. Finally, we present some experimental results showing the performance of the video streaming validating the framework.
Can Giraffes Become Birds? An Evaluation of Image-to-image Translation for Data Generation
Jan 10, 2020
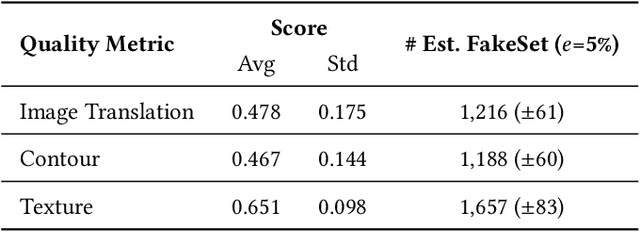

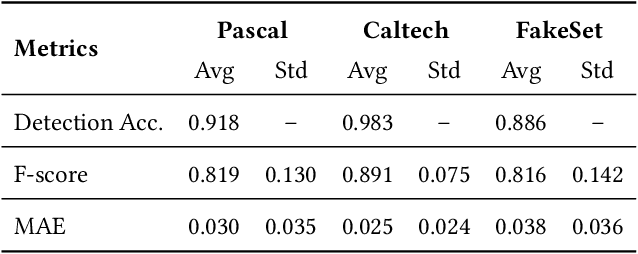
There is an increasing interest in image-to-image translation with applications ranging from generating maps from satellite images to creating entire clothes' images from only contours. In the present work, we investigate image-to-image translation using Generative Adversarial Networks (GANs) for generating new data, taking as a case study the morphing of giraffes images into bird images. Morphing a giraffe into a bird is a challenging task, as they have different scales, textures, and morphology. An unsupervised cross-domain translator entitled InstaGAN was trained on giraffes and birds, along with their respective masks, to learn translation between both domains. A dataset of synthetic bird images was generated using translation from originally giraffe images while preserving the original spatial arrangement and background. It is important to stress that the generated birds do not exist, being only the result of a latent representation learned by InstaGAN. Two subsets of common literature datasets were used for training the GAN and generating the translated images: COCO and Caltech-UCSD Birds 200-2011. To evaluate the realness and quality of the generated images and masks, qualitative and quantitative analyses were made. For the quantitative analysis, a pre-trained Mask R-CNN was used for the detection and segmentation of birds on Pascal VOC, Caltech-UCSD Birds 200-2011, and our new dataset entitled FakeSet. The generated dataset achieved detection and segmentation results close to the real datasets, suggesting that the generated images are realistic enough to be detected and segmented by a state-of-the-art deep neural network.
ANDA: A Novel Data Augmentation Technique Applied to Salient Object Detection
Oct 03, 2019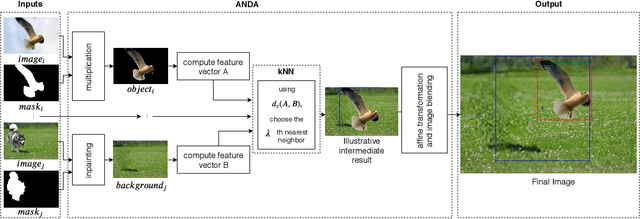

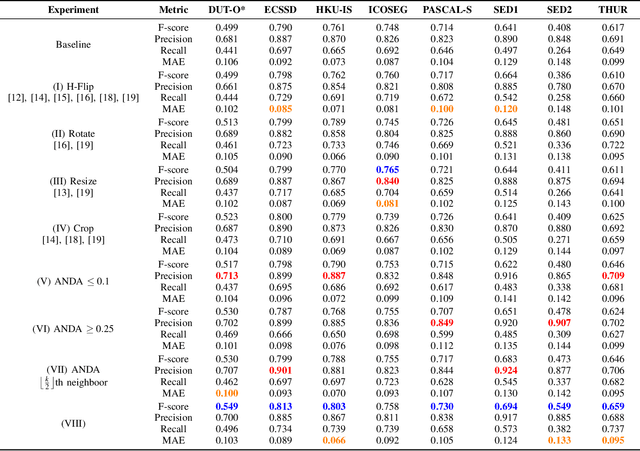
In this paper, we propose a novel data augmentation technique (ANDA) applied to the Salient Object Detection (SOD) context. Standard data augmentation techniques proposed in the literature, such as image cropping, rotation, flipping, and resizing, only generate variations of the existing examples, providing a limited generalization. Our method has the novelty of creating new images, by combining an object with a new background while retaining part of its salience in this new context; To do so, the ANDA technique relies on the linear combination between labeled salient objects and new backgrounds, generated by removing the original salient object in a process known as image inpainting. Our proposed technique allows for more precise control of the object's position and size while preserving background information. Aiming to evaluate our proposed method, we trained multiple deep neural networks and compared the effect that our technique has in each one. We also compared our method with other data augmentation techniques. Our findings show that depending on the network improvement can be up to 14.1% in the F-measure and decay of up to 2.6% in the Mean Absolute Error.
Masking Salient Object Detection, a Mask Region-based Convolutional Neural Network Analysis for Segmentation of Salient Objects
Sep 17, 2019


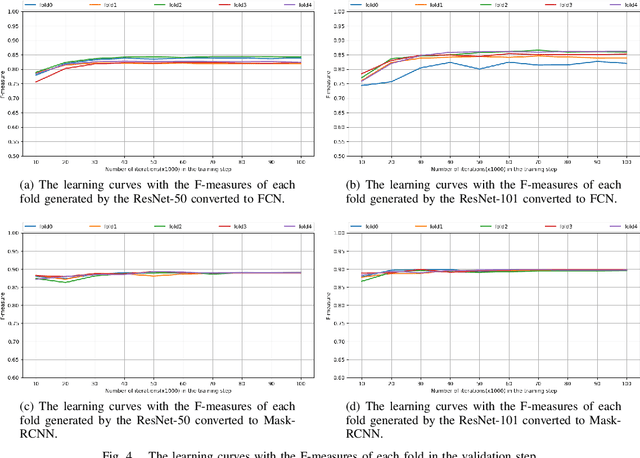
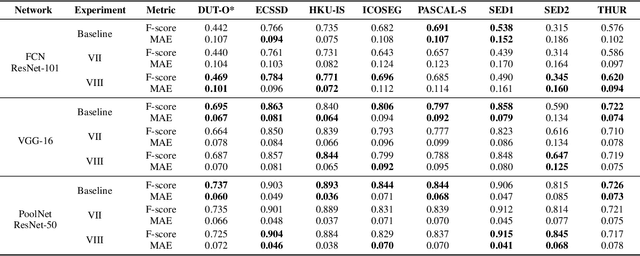
In this paper, we propose a broad comparison between Fully Convolutional Networks (FCNs) and Mask Region-based Convolutional Neural Networks (Mask-RCNNs) applied in the Salient Object Detection (SOD) context. Studies in the SOD literature usually explore architectures based in FCNs to detect salient regions and objects in visual scenes. However, besides the promising results achieved, FCNs showed issues in some challenging scenarios. Fairly recently studies in the SOD literature proposed the use of a Mask-RCNN approach to overcome such issues. However, there is no extensive comparison between the two networks in the SOD literature endorsing the effectiveness of Mask-RCNNs over FCN when segmenting salient objects. Aiming to effectively show the superiority of Mask-RCNNs over FCNs in the SOD context, we compare two variations of Mask-RCNNs with two variations of FCNs in eight datasets widely used in the literature and in four metrics. Our findings show that in this context Mask-RCNNs achieved an improvement on the F-measure up to 47% over FCNs.
An Efficient and Layout-Independent Automatic License Plate Recognition System Based on the YOLO detector
Sep 05, 2019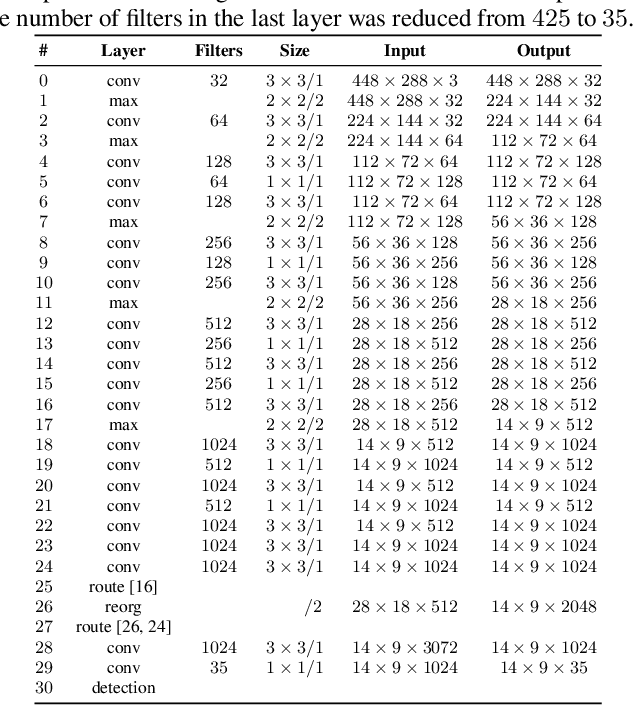

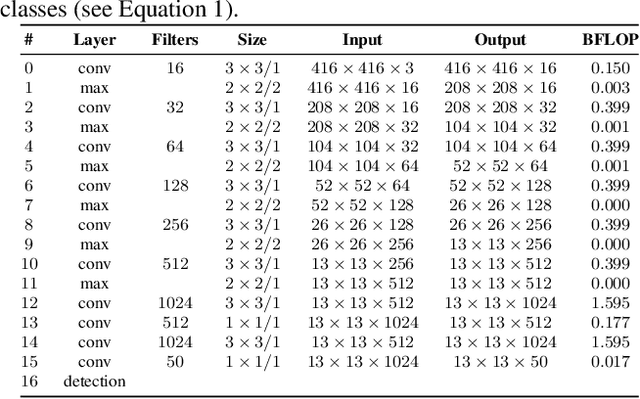

In this paper, we present an efficient and layout-independent Automatic License Plate Recognition (ALPR) system based on the state-of-the-art YOLO object detector that contains a unified approach for license plate (LP) detection and layout classification to improve the recognition results using post-processing rules. The system is conceived by evaluating and optimizing different models with various modifications, aiming at achieving the best speed/accuracy trade-off at each stage. The networks are trained using images from several datasets, with the addition of various data augmentation techniques, so that they are robust under different conditions. The proposed system achieved an average end-to-end recognition rate of 96.8% across eight public datasets (from five different regions) used in the experiments, outperforming both previous works and commercial systems in the ChineseLP, OpenALPR-EU, SSIG-SegPlate and UFPR-ALPR datasets. In the other datasets, the proposed approach achieved competitive results to those attained by the baselines. Our system also achieved impressive frames per second (FPS) rates on a high-end GPU, being able to perform in real time even when there are four vehicles in the scene. An additional contribution is that we manually labeled 38,334 bounding boxes on 6,237 images from public datasets and made the annotations publicly available to the research community.