 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient and Layout-Independent Automatic License Plate Recognition System Based on the YOLO detector
Sep 05, 2019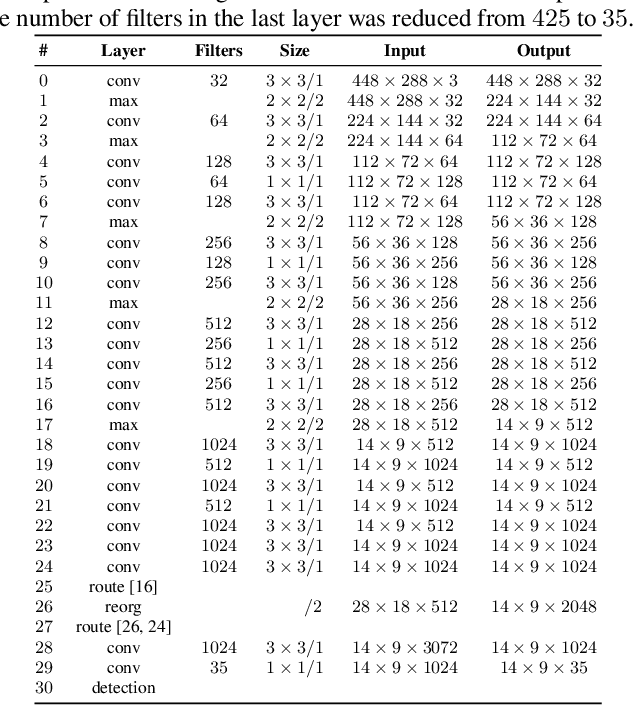


In this paper, we present an efficient and layout-independent Automatic License Plate Recognition (ALPR) system based on the state-of-the-art YOLO object detector that contains a unified approach for license plate (LP) detection and layout classification to improve the recognition results using post-processing rules. The system is conceived by evaluating and optimizing different models with various modifications, aiming at achieving the best speed/accuracy trade-off at each stage. The networks are trained using images from several datasets, with the addition of various data augmentation techniques, so that they are robust under different conditions. The proposed system achieved an average end-to-end recognition rate of 96.8% across eight public datasets (from five different regions) used in the experiments, outperforming both previous works and commercial systems in the ChineseLP, OpenALPR-EU, SSIG-SegPlate and UFPR-ALPR datasets. In the other datasets, the proposed approach achieved competitive results to those attained by the baselines. Our system also achieved impressive frames per second (FPS) rates on a high-end GPU, being able to perform in real time even when there are four vehicles in the scene. An additional contribution is that we manually labeled 38,334 bounding boxes on 6,237 images from public datasets and made the annotations publicly available to the research community.
Convolutional Neural Networks for Automatic Meter Reading
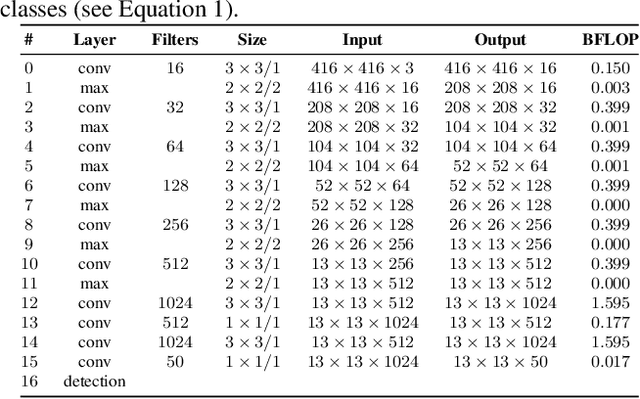
Feb 25, 2019In this paper, we tackle Automatic Meter Reading (AMR) by leveraging the high capability of Convolutional Neural Networks (CNNs). We design a two-stage approach that employs the Fast-YOLO object detector for counter detection and evaluates three different CNN-based approaches for counter recognition. In the AMR literature, most datasets are not available to the research community since the images belong to a service company. In this sense, we introduce a new public dataset, called UFPR-AMR dataset, with 2,000 fully and manually annotated images. This dataset is, to the best of our knowledge, three times larger than the largest public dataset found in the literature and contains a well-defined evaluation protocol to assist the development and evaluation of AMR methods. Furthermore, we propose the use of a data augmentation technique to generate a balanced training set with many more examples to train the CNN models for counter recognition. In the proposed dataset, impressive results were obtained and a detailed speed/accuracy trade-off evaluation of each model was performed. In a public dataset, state-of-the-art results were achieved using less than 200 images for training.