 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDACov: A Deeper Analysis of Data Augmentation on the Computed Tomography Segmentation Problem
Mar 10, 2023Due to the COVID-19 global pandemic, computer-assisted diagnoses of medical images have gained much attention, and robust methods of semantic segmentation of Computed Tomography (CT) images have become highly desirable. In this work, we present a deeper analysis of how data augmentation techniques improve segmentation performance on this problem. We evaluate 20 traditional augmentation techniques on five public datasets. Six different probabilities of applying each augmentation technique on an image were evaluated. We also assess a different training methodology where the training subsets are combined into a single larger set. All networks were evaluated through a 5-fold cross-validation strategy, resulting in over 4,600 experiments. We also propose a novel data augmentation technique based on Generative Adversarial Networks (GANs) to create new healthy and unhealthy lung CT images, evaluating four variations of our approach with the same six probabilities of the traditional methods. Our findings show that GAN-based techniques and spatial-level transformations are the most promising for improving the learning of deep models on this problem, with the StarGANv2 + F with a probability of 0.3 achieving the highest F-score value on the Ricord1a dataset in the unified training strategy. Our code is publicly available at https://github.com/VRI-UFPR/DACov2022
Light In The Black: An Evaluation of Data Augmentation Techniques for COVID-19 CT's Semantic Segmentation
May 19, 2022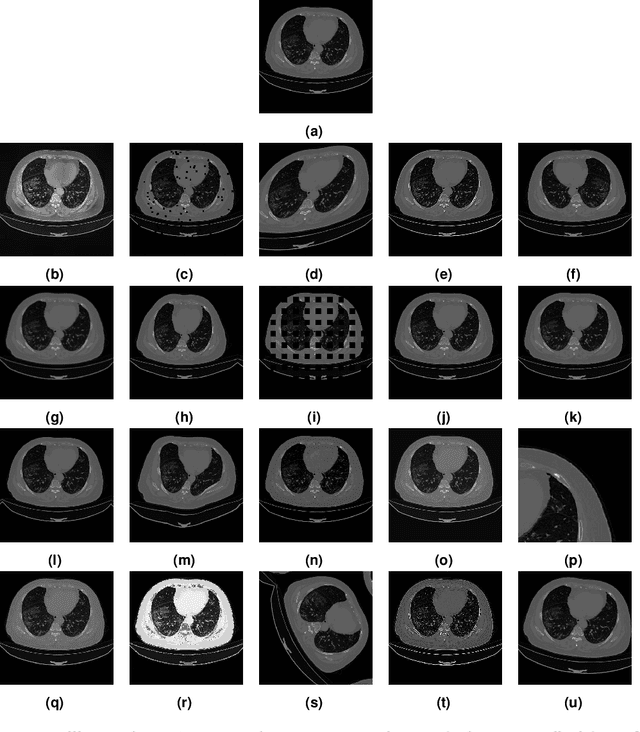


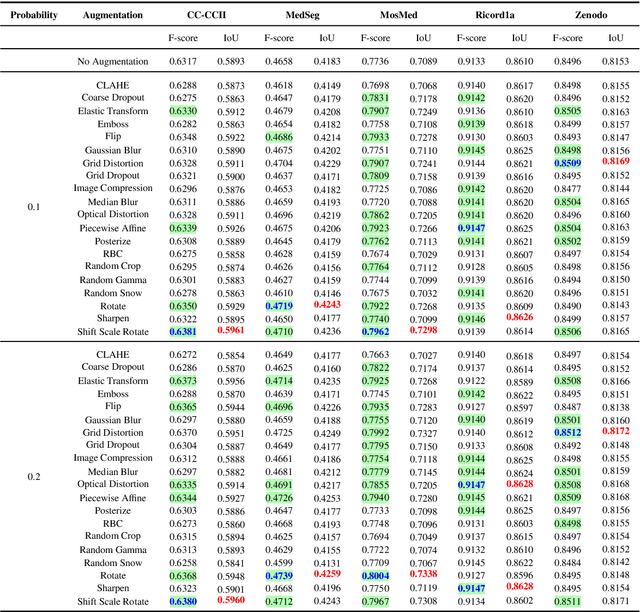
With the COVID-19 global pandemic, computer-assisted diagnoses of medical images have gained much attention, and robust methods of Semantic Segmentation of Computed Tomography (CT) became highly desirable. Semantic Segmentation of CT is one of many research fields of automatic detection of COVID-19 and has been widely explored since the COVID-19 outbreak. In this work, we propose an extensive analysis of how different data augmentation techniques improve the training of encoder-decoder neural networks on this problem. Twenty different data augmentation techniques were evaluated on five different datasets. Each dataset was validated through a five-fold cross-validation strategy, thus resulting in over 3,000 experiments. Our findings show that spatial level transformations are the most promising to improve the learning of neural networks on this problem.
Spark in the Dark: Evaluating Encoder-Decoder Pairs for COVID-19 CT's Semantic Segmentation
Sep 30, 2021


With the COVID-19 global pandemic, computerassisted diagnoses of medical images have gained a lot of attention, and robust methods of Semantic Segmentation of Computed Tomography (CT) turned highly desirable. Semantic Segmentation of CT is one of many research fields of automatic detection of Covid-19 and was widely explored since the Covid19 outbreak. In the robotic field, Semantic Segmentation of organs and CTs are widely used in robots developed for surgery tasks. As new methods and new datasets are proposed quickly, it becomes apparent the necessity of providing an extensive evaluation of those methods. To provide a standardized comparison of different architectures across multiple recently proposed datasets, we propose in this paper an extensive benchmark of multiple encoders and decoders with a total of 120 architectures evaluated in five datasets, with each dataset being validated through a five-fold cross-validation strategy, totaling 3.000 experiments. To the best of our knowledge, this is the largest evaluation in number of encoders, decoders, and datasets proposed in the field of Covid-19 CT segmentation.
IDA: Improved Data Augmentation Applied to Salient Object Detection
Sep 18, 2020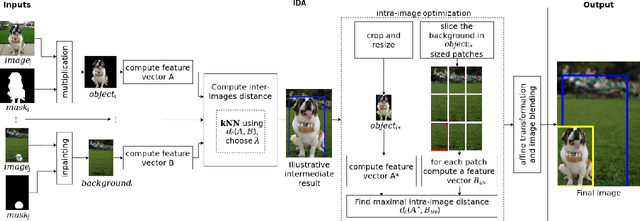



In this paper, we present an Improved Data Augmentation (IDA) technique focused on Salient Object Detection (SOD). Standard data augmentation techniques proposed in the literature, such as image cropping, rotation, flipping, and resizing, only generate variations of the existing examples, providing a limited generalization. Our method combines image inpainting, affine transformations, and the linear combination of different generated background images with salient objects extracted from labeled data. Our proposed technique enables more precise control of the object's position and size while preserving background information. The background choice is based on an inter-image optimization, while object size follows a uniform random distribution within a specified interval, and the object position is intra-image optimal. We show that our method improves the segmentation quality when used for training state-of-the-art neural networks on several famous datasets of the SOD field. Combining our method with others surpasses traditional techniques such as horizontal-flip in 0.52% for F-measure and 1.19% for Precision. We also provide an evaluation in 7 different SOD datasets, with 9 distinct evaluation metrics and an average ranking of the evaluated methods.
ANDA: A Novel Data Augmentation Technique Applied to Salient Object Detection
Oct 03, 2019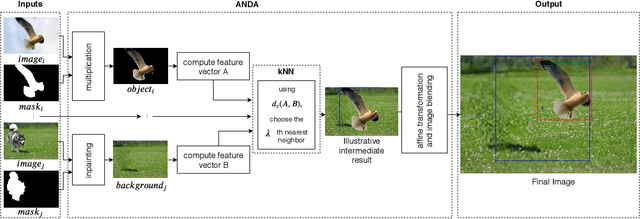

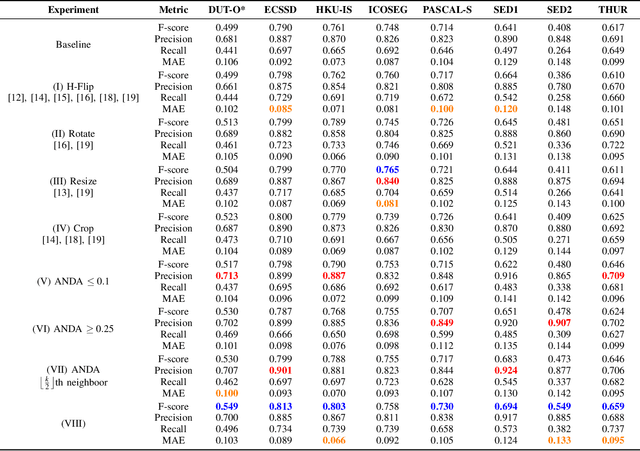
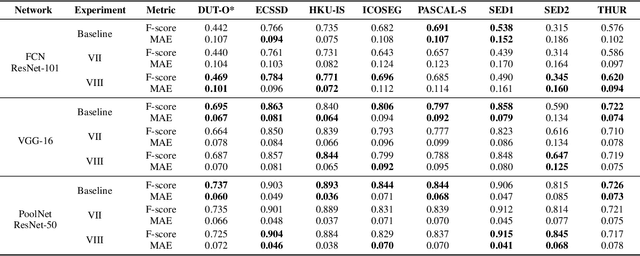
In this paper, we propose a novel data augmentation technique (ANDA) applied to the Salient Object Detection (SOD) context. Standard data augmentation techniques proposed in the literature, such as image cropping, rotation, flipping, and resizing, only generate variations of the existing examples, providing a limited generalization. Our method has the novelty of creating new images, by combining an object with a new background while retaining part of its salience in this new context; To do so, the ANDA technique relies on the linear combination between labeled salient objects and new backgrounds, generated by removing the original salient object in a process known as image inpainting. Our proposed technique allows for more precise control of the object's position and size while preserving background information. Aiming to evaluate our proposed method, we trained multiple deep neural networks and compared the effect that our technique has in each one. We also compared our method with other data augmentation techniques. Our findings show that depending on the network improvement can be up to 14.1% in the F-measure and decay of up to 2.6% in the Mean Absolute Error.
Masking Salient Object Detection, a Mask Region-based Convolutional Neural Network Analysis for Segmentation of Salient Objects
Sep 17, 2019


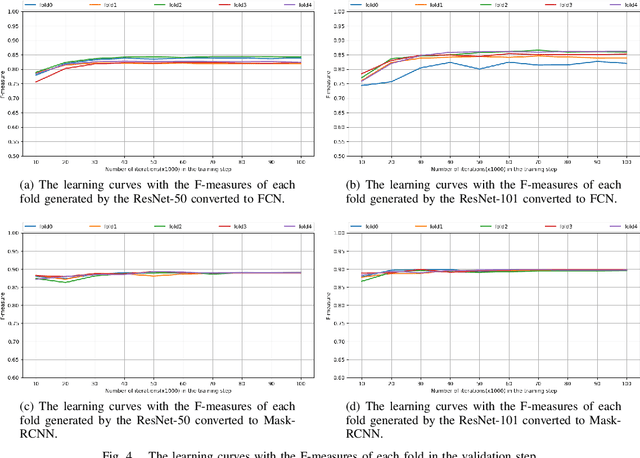
In this paper, we propose a broad comparison between Fully Convolutional Networks (FCNs) and Mask Region-based Convolutional Neural Networks (Mask-RCNNs) applied in the Salient Object Detection (SOD) context. Studies in the SOD literature usually explore architectures based in FCNs to detect salient regions and objects in visual scenes. However, besides the promising results achieved, FCNs showed issues in some challenging scenarios. Fairly recently studies in the SOD literature proposed the use of a Mask-RCNN approach to overcome such issues. However, there is no extensive comparison between the two networks in the SOD literature endorsing the effectiveness of Mask-RCNNs over FCN when segmenting salient objects. Aiming to effectively show the superiority of Mask-RCNNs over FCNs in the SOD context, we compare two variations of Mask-RCNNs with two variations of FCNs in eight datasets widely used in the literature and in four metrics. Our findings show that in this context Mask-RCNNs achieved an improvement on the F-measure up to 47% over FCNs.