 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA representational framework for learning and encoding structurally enriched trajectories in complex agent environments
Mar 17, 2025The ability of artificial intelligence agents to make optimal decisions and generalise them to different domains and tasks is compromised in complex scenarios. One way to address this issue has focused on learning efficient representations of the world and on how the actions of agents affect them, such as disentangled representations that exploit symmetries. Whereas such representations are procedurally efficient, they are based on the compression of low-level state-action transitions, which lack structural richness. To address this problem, we propose to enrich the agent's ontology and extend the traditional conceptualisation of trajectories to provide a more nuanced view of task execution. Structurally Enriched Trajectories (SETs) extend the encoding of sequences of states and their transitions by incorporating hierarchical relations between objects, interactions and affordances. SETs are built as multi-level graphs, providing a detailed representation of the agent dynamics and a transferable functional abstraction of the task. SETs are integrated into an architecture, Structurally Enriched Trajectory Learning and Encoding (SETLE), that employs a heterogeneous graph-based memory structure of multi-level relational dependencies essential for generalisation. Using reinforcement learning as a data generation tool, we demonstrate that SETLE can support downstream tasks, enabling agents to recognise task-relevant structural patterns across diverse environments.
Mutation-Bias Learning in Games
May 28, 2024We present two variants of a multi-agent reinforcement learning algorithm based on evolutionary game theoretic considerations. The intentional simplicity of one variant enables us to prove results on its relationship to a system of ordinary differential equations of replicator-mutator dynamics type, allowing us to present proofs on the algorithm's convergence conditions in various settings via its ODE counterpart. The more complicated variant enables comparisons to Q-learning based algorithms. We compare both variants experimentally to WoLF-PHC and frequency-adjusted Q-learning on a range of settings, illustrating cases of increasing dimensionality where our variants preserve convergence in contrast to more complicated algorithms. The availability of analytic results provides a degree of transferability of results as compared to purely empirical case studies, illustrating the general utility of a dynamical systems perspective on multi-agent reinforcement learning when addressing questions of convergence and reliable generalisation.
DiT-Head: High-Resolution Talking Head Synthesis using Diffusion Transformers
Dec 11, 2023We propose a novel talking head synthesis pipeline called "DiT-Head", which is based on diffusion transformers and uses audio as a condition to drive the denoising process of a diffusion model. Our method is scalable and can generalise to multiple identities while producing high-quality results. We train and evaluate our proposed approach and compare it against existing methods of talking head synthesis. We show that our model can compete with these methods in terms of visual quality and lip-sync accuracy. Our results highlight the potential of our proposed approach to be used for a wide range of applications, including virtual assistants, entertainment, and education. For a video demonstration of the results and our user study, please refer to our supplementary material.
Cognitively Inspired Components for Social Conversational Agents
Nov 09, 2023


Current conversational agents (CA) have seen improvement in conversational quality in recent years due to the influence of large language models (LLMs) like GPT3. However, two key categories of problem remain. Firstly there are the unique technical problems resulting from the approach taken in creating the CA, such as scope with retrieval agents and the often nonsensical answers of former generative agents. Secondly, humans perceive CAs as social actors, and as a result expect the CA to adhere to social convention. Failure on the part of the CA in this respect can lead to a poor interaction and even the perception of threat by the user. As such, this paper presents a survey highlighting a potential solution to both categories of problem through the introduction of cognitively inspired additions to the CA. Through computational facsimiles of semantic and episodic memory, emotion, working memory, and the ability to learn, it is possible to address both the technical and social problems encountered by CAs.
Algebras of actions in an agent's representations of the world
Oct 02, 2023In this paper, we propose a framework to extract the algebra of the transformations of worlds from the perspective of an agent. As a starting point, we use our framework to reproduce the symmetry-based representations from the symmetry-based disentangled representation learning (SBDRL) formalism proposed by [1]; only the algebra of transformations of worlds that form groups can be described using symmetry-based representations. We then study the algebras of the transformations of worlds with features that occur in simple reinforcement learning scenarios. Using computational methods, that we developed, we extract the algebras of the transformations of these worlds and classify them according to their properties. Finally, we generalise two important results of SBDRL - the equivariance condition and the disentangling definition - from only working with symmetry-based representations to working with representations capturing the transformation properties of worlds with transformations for any algebra. Finally, we combine our generalised equivariance condition and our generalised disentangling definition to show that disentangled sub-algebras can each have their own individual equivariance conditions, which can be treated independently.
Efficient entity-based reinforcement learning
Jun 06, 2022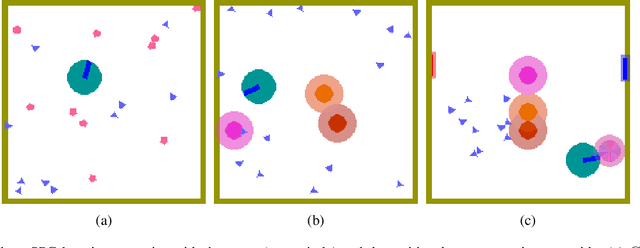
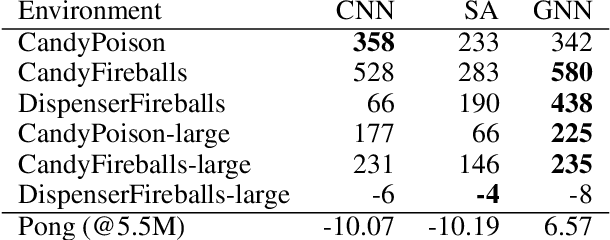
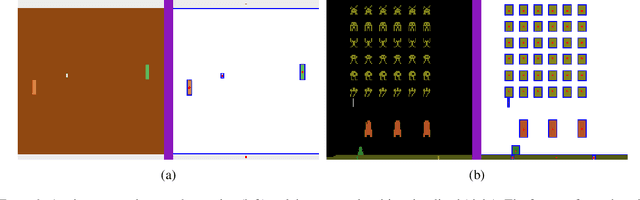
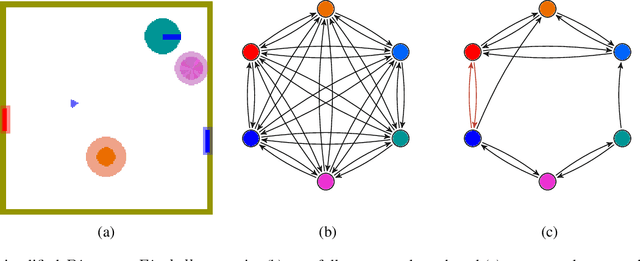
Recent deep reinforcement learning (DRL) successes rely on end-to-end learning from fixed-size observational inputs (e.g. image, state-variables). However, many challenging and interesting problems in decision making involve observations or intermediary representations which are best described as a set of entities: either the image-based approach would miss small but important details in the observations (e.g. ojects on a radar, vehicles on satellite images, etc.), the number of sensed objects is not fixed (e.g. robotic manipulation), or the problem simply cannot be represented in a meaningful way as an image (e.g. power grid control, or logistics). This type of structured representations is not directly compatible with current DRL architectures, however, there has been an increase in machine learning techniques directly targeting structured information, potentially addressing this issue. We propose to combine recent advances in set representations with slot attention and graph neural networks to process structured data, broadening the range of applications of DRL algorithms. This approach allows to address entity-based problems in an efficient and scalable way. We show that it can improve training time and robustness significantly, and demonstrate their potential to handle structured as well as purely visual domains, on multiple environments from the Atari Learning Environment and Simple Playgrounds.
AIGenC: AI generalisation via creativity
May 23, 2022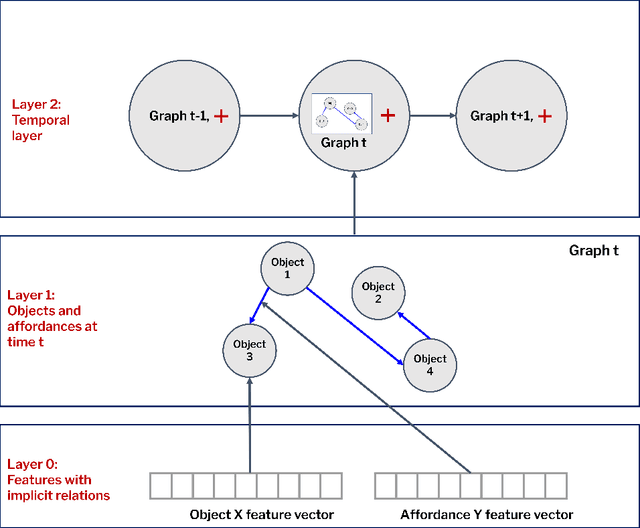
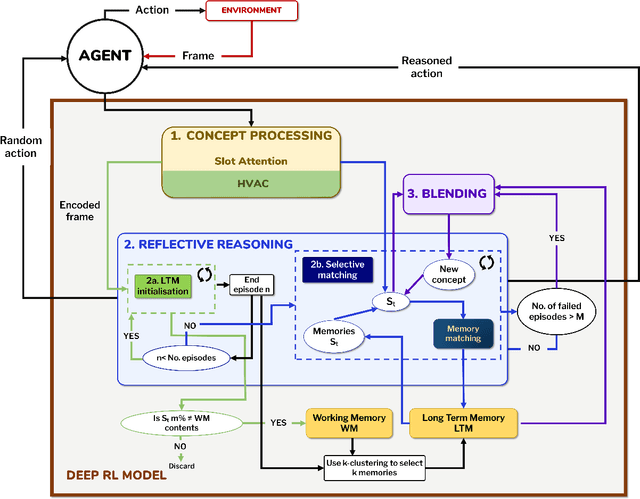
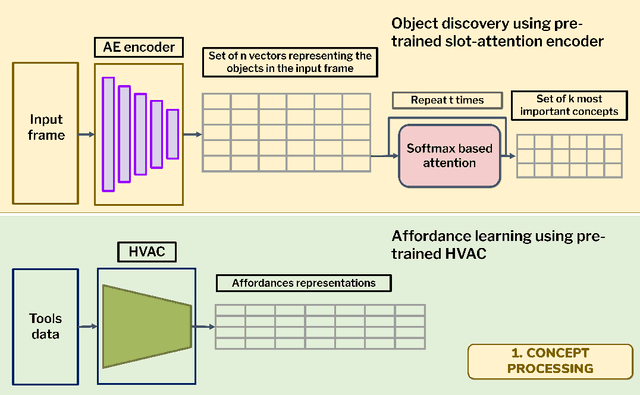
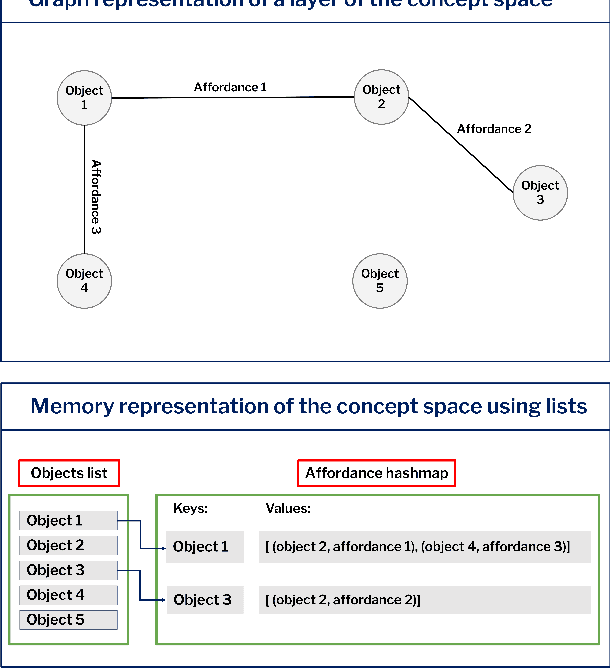
This paper introduces a computational model of creative problem solving in deep reinforcement learning agents, inspired by cognitive theories of creativity. The AIGenC model aims at enabling artificial agents to learn, use and generate transferable representations. AIGenC is embedded in a deep learning architecture that includes three main components: concept processing, reflective reasoning, and blending of concepts. The first component extracts objects and affordances from sensory input and encodes them in a concept space, represented as a hierarchical graph structure. Concept representations are stored in a dual memory system. Goal-directed and temporal information acquired by the agent during deep reinforcement learning enriches the representations creating a higher-level of abstraction in the concept space. In parallel, a process akin to reflective reasoning detects and recovers from memory concepts relevant to the task according to a matching process that calculates a similarity value between the current state and memory graph structures. Once an interaction is finalised, rewards and temporal information are added to the graph structure, creating a higher abstraction level. If reflective reasoning fails to offer a suitable solution, a blending process comes into place to create new concepts by combining past information. We discuss the model's capability to yield better out-of-distribution generalisation in artificial agents, thus advancing toward artificial general intelligence. To the best of our knowledge, this is the first computational model, beyond mere formal theories, that posits a solution to creative problem solving within a deep learning architecture.
Logo Generation Using Regional Features: A Faster R-CNN Approach to Generative Adversarial Networks
Oct 02, 2021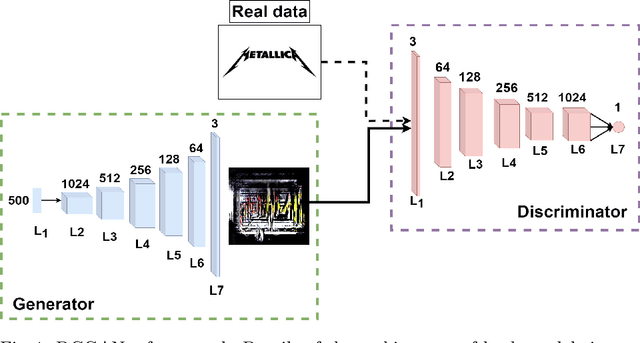
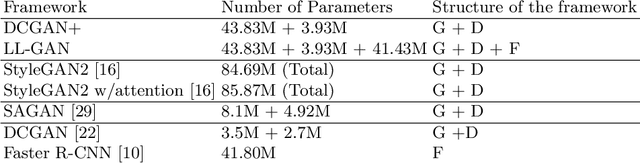
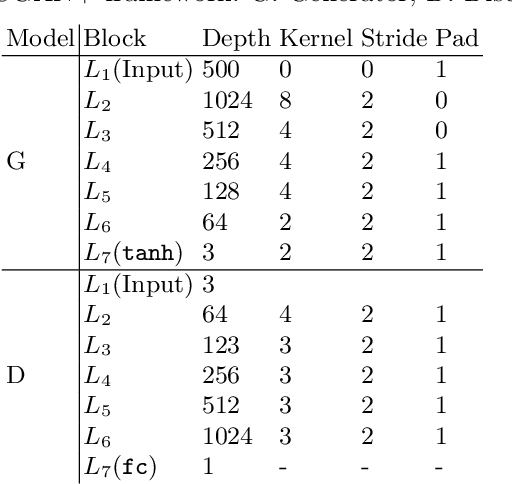
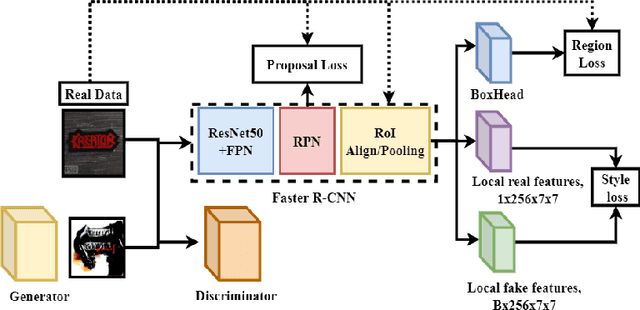
In this paper we introduce Local Logo Generative Adversarial Network (LL-GAN) that uses regional features extracted from Faster R-CNN for logo generation. We demonstrate the strength of this approach by training the framework on a small style-rich dataset of real heavy metal logos to generate new ones. LL-GAN achieves Inception Score of 5.29 and Frechet Inception Distance of 223.94, improving on state-of-the-art models StyleGAN2 and Self-Attention GAN.
Gaussian Process Regression for Probabilistic Short-term Solar Output Forecast
Feb 23, 2020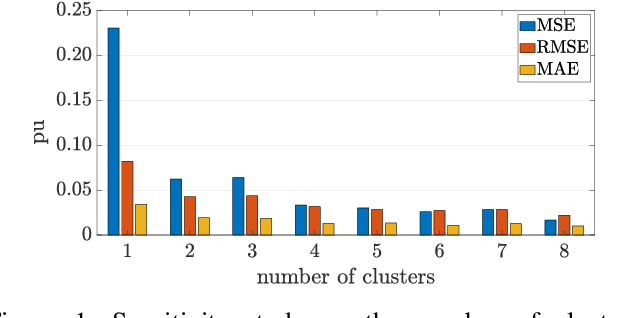


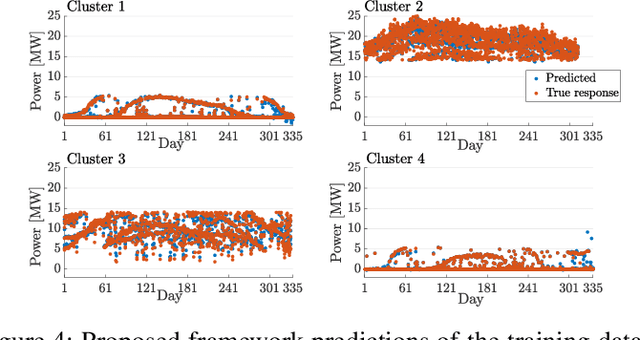
With increasing concerns of climate change, renewable resources such as photovoltaic (PV) have gained popularity as a means of energy generation. The smooth integration of such resources in power system operations is enabled by accurate forecasting mechanisms that address their inherent intermittency and variability. This paper proposes a probabilistic framework to predict short-term PV output taking into account the uncertainty of weather. To this end, we make use of datasets that comprise of power output and meteorological data such as irradiance, temperature, zenith, and azimuth. First, we categorise the data into four groups based on solar output and time by using k-means clustering. Next, a correlation study is performed to choose the weather features which affect solar output to a greater extent. Finally, we determine a function that relates the aforementioned selected features with solar output by using Gaussian Process Regression and Matern 5/2 as a kernel function. We validate our method with five solar generation plants in different locations and compare the results with existing methodologies. More specifically, in order to test the proposed model, two different methods are used: (i) 5-fold cross-validation; and (ii) holding out 30 random days as test data. To confirm the model accuracy, we apply our framework 30 independent times on each of the four clusters. The average error follows a normal distribution, and with 95% confidence level, it takes values between -1.6% to 1.4%.
Generating Magnetic Resonance Spectroscopy Imaging Data of Brain Tumours from Linear, Non-Linear and Deep Learning Models
Aug 23, 2018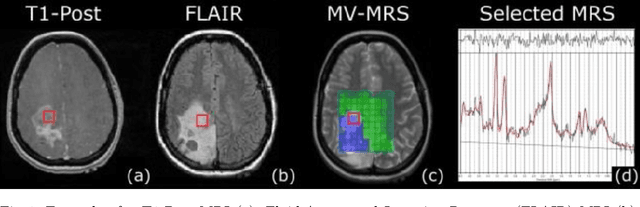


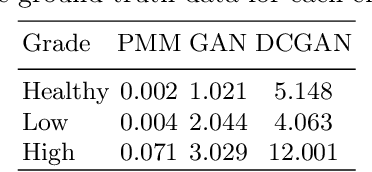
Magnetic Resonance Spectroscopy (MRS) provides valuable information to help with the identification and understanding of brain tumors, yet MRS is not a widely available medical imaging modality. Aiming to counter this issue, this research draws on the advancements in machine learning techniques in other fields for the generation of artificial data. The generated methods were tested through the evaluation of their output against that of a real-world labelled MRS brain tumor data-set. Furthermore the resultant output from the generative techniques were each used to train separate traditional classifiers which were tested on a subset of the real MRS brain tumor dataset. The results suggest that there exist methods capable of producing accurate, ground truth based MRS voxels. These findings indicate that through generative techniques, large datasets can be made available for training deep, learning models for the use in brain tumor diagnosis.