 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvShareViT: Enhancing Vision Transformers with Convolutional Attention Mechanisms for Free-Space Optical Accelerators
Apr 15, 2025This paper introduces ConvShareViT, a novel deep learning architecture that adapts Vision Transformers (ViTs) to the 4f free-space optical system. ConvShareViT replaces linear layers in multi-head self-attention (MHSA) and Multilayer Perceptrons (MLPs) with a depthwise convolutional layer with shared weights across input channels. Through the development of ConvShareViT, the behaviour of convolutions within MHSA and their effectiveness in learning the attention mechanism were analysed systematically. Experimental results demonstrate that certain configurations, particularly those using valid-padded shared convolutions, can successfully learn attention, achieving comparable attention scores to those obtained with standard ViTs. However, other configurations, such as those using same-padded convolutions, show limitations in attention learning and operate like regular CNNs rather than transformer models. ConvShareViT architectures are specifically optimised for the 4f optical system, which takes advantage of the parallelism and high-resolution capabilities of optical systems. Results demonstrate that ConvShareViT can theoretically achieve up to 3.04 times faster inference than GPU-based systems. This potential acceleration makes ConvShareViT an attractive candidate for future optical deep learning applications and proves that our ViT (ConvShareViT) can be employed using only the convolution operation, via the necessary optimisation of the ViT to balance performance and complexity.
FatNet: High Resolution Kernels for Classification Using Fully Convolutional Optical Neural Networks
Oct 30, 2022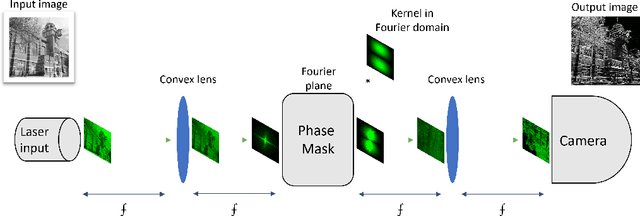



This paper describes the transformation of a traditional in-silico classification network into an optical fully convolutional neural network with high-resolution feature maps and kernels. When using the free-space 4f system to accelerate the inference speed of neural networks, higher resolutions of feature maps and kernels can be used without the loss in frame rate. We present FatNet for the classification of images, which is more compatible with free-space acceleration than standard convolutional classifiers. It neglects the standard combination of convolutional feature extraction and classifier dense layers by performing both in one fully convolutional network. This approach takes full advantage of the parallelism in the 4f free-space system and performs fewer conversions between electronics and optics by reducing the number of channels and increasing the resolution, making the network faster in optics than off-the-shelf networks. To demonstrate the capabilities of FatNet, it trained with the CIFAR100 dataset on GPU and the simulator of the 4f system, then compared the results against ResNet-18. The results show 8.2 times fewer convolution operations at the cost of only 6% lower accuracy compared to the original network. These are promising results for the approach of training deep learning with high-resolution kernels in the direction towards the upcoming optics era.
Contrastive Counterfactual Visual Explanations With Overdetermination
Jun 28, 2021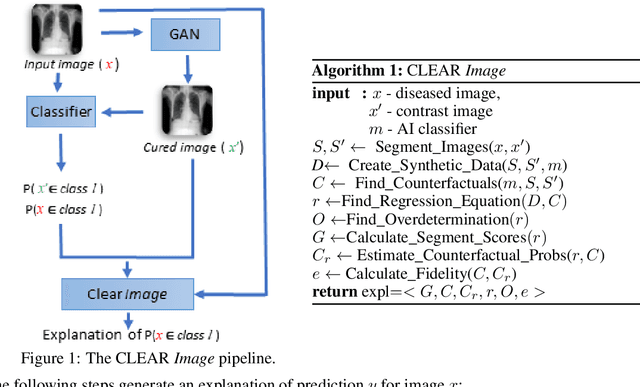
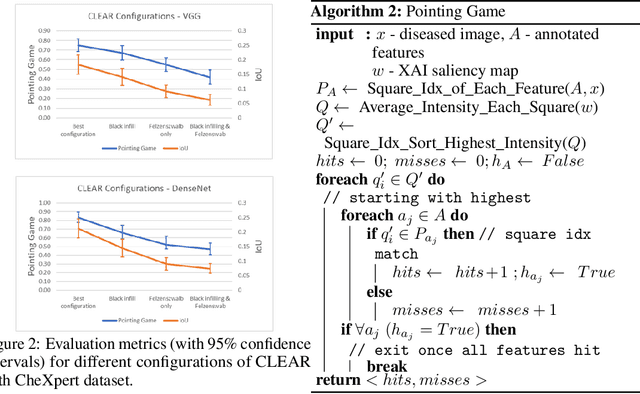

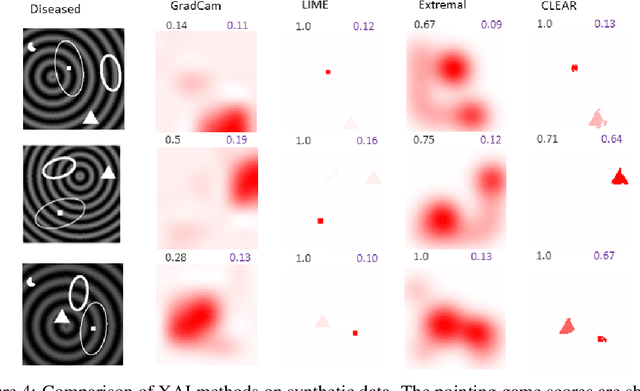
A novel explainable AI method called CLEAR Image is introduced in this paper. CLEAR Image is based on the view that a satisfactory explanation should be contrastive, counterfactual and measurable. CLEAR Image explains an image's classification probability by contrasting the image with a corresponding image generated automatically via adversarial learning. This enables both salient segmentation and perturbations that faithfully determine each segment's importance. CLEAR Image was successfully applied to a medical imaging case study where it outperformed methods such as Grad-CAM and LIME by an average of 27% using a novel pointing game metric. CLEAR Image excels in identifying cases of "causal overdetermination" where there are multiple patches in an image, any one of which is sufficient by itself to cause the classification probability to be close to one.
The relationship between Fully Connected Layers and number of classes for the analysis of retinal images
Apr 14, 2020



This paper experiments with the number of fully-connected layers in a deep convolutional neural network as applied to the classification of fundus retinal images. The images analysed corresponded to the ODIR 2019 (Peking University International Competition on Ocular Disease Intelligent Recognition) [9], which included images of various eye diseases (cataract, glaucoma, myopia, diabetic retinopathy, age-related macular degeneration (AMD), hypertension) as well as normal cases. This work focused on the classification of Normal, Cataract, AMD and Myopia. The feature extraction (convolutional) part of the neural network is kept the same while the feature mapping (linear) part of the network is changed. Different data sets are also explored on these neural nets. Each data set differs from another by the number of classes it has. This paper hence aims to find the relationship between number of classes and number of fully-connected layers. It was found out that the effect of increasing the number of fully-connected layers of a neural networks depends on the type of data set being used. For simple, linearly separable data sets, addition of fully-connected layer is something that should be explored and that could result in better training accuracy, but a direct correlation was not found. However as complexity of the data set goes up(more overlapping classes), increasing the number of fully-connected layers causes the neural network to stop learning. This phenomenon happens quicker the more complex the data set is.
Detection of Pitt-Hopkins Syndrome based on morphological facial features
Mar 19, 2020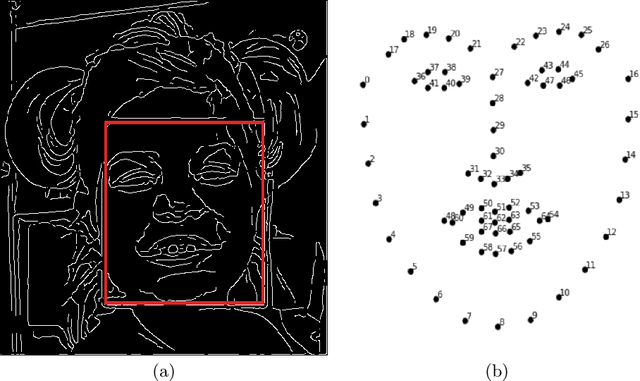
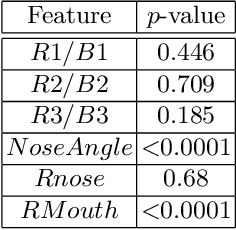
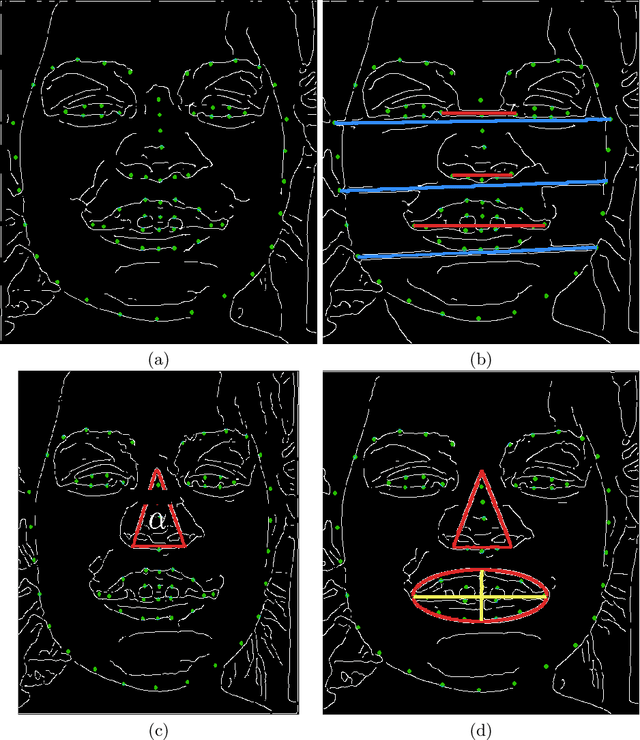
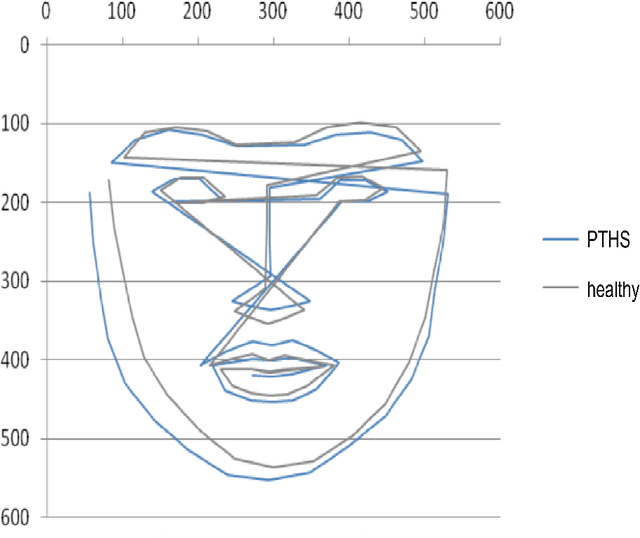
This work describes an automatic methodology to discriminate between individuals with the genetic disorder Pitt-Hopkins syndrome (PTHS), and healthy individuals. As input data, the methodology accepts unconstrained frontal facial photographs, from which faces are located with Histograms of Oriented Gradients features descriptors. Pre-processing steps of the methodology consist of colour normalisation, scaling down, rotation, and cropping in order to produce a series of images of faces with consistent dimensions. Sixty eight facial landmarks are automatically located on each face through a cascade of regression functions learnt via gradient boosting to estimate the shape from an initial approximation. The intensities of a sparse set of pixels indexed relative to this initial estimate are used to determine the landmarks. A set of carefully selected geometric features, for example, relative width of the mouth, or angle of the nose, are extracted from the landmarks. The features are used to investigate the statistical differences between the two populations of PTHS and healthy controls. The methodology was tested on 71 individuals with PTHS and 55 healthy controls. Two geometric features related to the nose and mouth showed statistical difference between the two populations.
Generating Magnetic Resonance Spectroscopy Imaging Data of Brain Tumours from Linear, Non-Linear and Deep Learning Models
Aug 23, 2018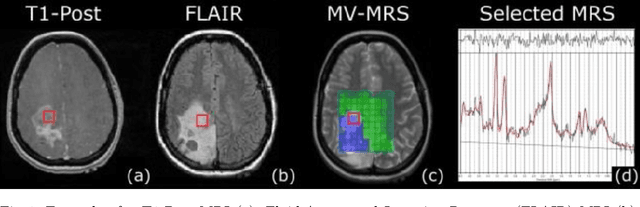


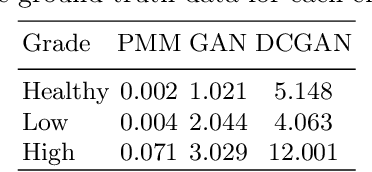
Magnetic Resonance Spectroscopy (MRS) provides valuable information to help with the identification and understanding of brain tumors, yet MRS is not a widely available medical imaging modality. Aiming to counter this issue, this research draws on the advancements in machine learning techniques in other fields for the generation of artificial data. The generated methods were tested through the evaluation of their output against that of a real-world labelled MRS brain tumor data-set. Furthermore the resultant output from the generative techniques were each used to train separate traditional classifiers which were tested on a subset of the real MRS brain tumor dataset. The results suggest that there exist methods capable of producing accurate, ground truth based MRS voxels. These findings indicate that through generative techniques, large datasets can be made available for training deep, learning models for the use in brain tumor diagnosis.