 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Nemotron-Math: Efficient Long-Context Distillation of Mathematical Reasoning from Multi-Mode Supervision
Dec 17, 2025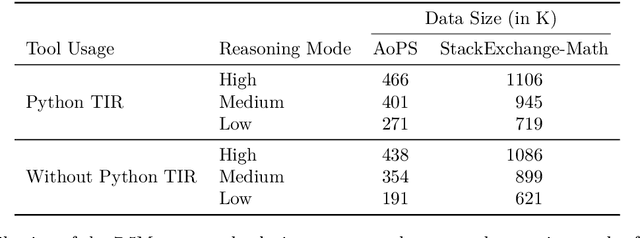
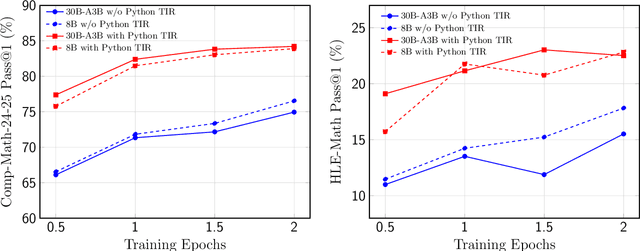

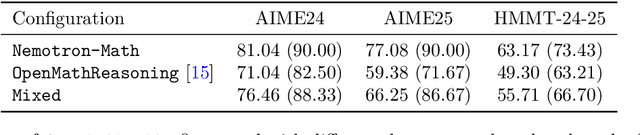
High-quality mathematical reasoning supervision requires diverse reasoning styles, long-form traces, and effective tool integration, capabilities that existing datasets provide only in limited form. Leveraging the multi-mode generation ability of gpt-oss-120b, we introduce Nemotron-Math, a large-scale mathematical reasoning dataset containing 7.5M solution traces across high, medium, and low reasoning modes, each available both with and without Python tool-integrated reasoning (TIR). The dataset integrates 85K curated AoPS problems with 262K community-sourced StackExchange-Math problems, combining structured competition tasks with diverse real-world mathematical queries. We conduct controlled evaluations to assess the dataset quality. Nemotron-Math consistently outperforms the original OpenMathReasoning on matched AoPS problems. Incorporating StackExchange-Math substantially improves robustness and generalization, especially on HLE-Math, while preserving accuracy on math competition benchmarks. To support efficient long-context training, we develop a sequential bucketed strategy that accelerates 128K context-length fine-tuning by 2--3$\times$ without significant accuracy loss. Overall, Nemotron-Math enables state-of-the-art performance, including 100\% maj@16 accuracy on AIME 2024 and 2025 with Python TIR.
Online Control of Unknown Time-Varying Dynamical Systems
Feb 16, 2022We study online control of time-varying linear systems with unknown dynamics in the nonstochastic control model. At a high level, we demonstrate that this setting is \emph{qualitatively harder} than that of either unknown time-invariant or known time-varying dynamics, and complement our negative results with algorithmic upper bounds in regimes where sublinear regret is possible. More specifically, we study regret bounds with respect to common classes of policies: Disturbance Action (SLS), Disturbance Response (Youla), and linear feedback policies. While these three classes are essentially equivalent for LTI systems, we demonstrate that these equivalences break down for time-varying systems. We prove a lower bound that no algorithm can obtain sublinear regret with respect to the first two classes unless a certain measure of system variability also scales sublinearly in the horizon. Furthermore, we show that offline planning over the state linear feedback policies is NP-hard, suggesting hardness of the online learning problem. On the positive side, we give an efficient algorithm that attains a sublinear regret bound against the class of Disturbance Response policies up to the aforementioned system variability term. In fact, our algorithm enjoys sublinear \emph{adaptive} regret bounds, which is a strictly stronger metric than standard regret and is more appropriate for time-varying systems. We sketch extensions to Disturbance Action policies and partial observation, and propose an inefficient algorithm for regret against linear state feedback policies.
Machine Learning for Mechanical Ventilation Control (Extended Abstract)
Nov 23, 2021Mechanical ventilation is one of the most widely used therapies in the ICU. However, despite broad application from anaesthesia to COVID-related life support, many injurious challenges remain. We frame these as a control problem: ventilators must let air in and out of the patient's lungs according to a prescribed trajectory of airway pressure. Industry-standard controllers, based on the PID method, are neither optimal nor robust. Our data-driven approach learns to control an invasive ventilator by training on a simulator itself trained on data collected from the ventilator. This method outperforms popular reinforcement learning algorithms and even controls the physical ventilator more accurately and robustly than PID. These results underscore how effective data-driven methodologies can be for invasive ventilation and suggest that more general forms of ventilation (e.g., non-invasive, adaptive) may also be amenable.
Provable Regret Bounds for Deep Online Learning and Control
Oct 20, 2021The use of deep neural networks has been highly successful in reinforcement learning and control, although few theoretical guarantees for deep learning exist for these problems. There are two main challenges for deriving performance guarantees: a) control has state information and thus is inherently online and b) deep networks are non-convex predictors for which online learning cannot provide provable guarantees in general. Building on the linearization technique for overparameterized neural networks, we derive provable regret bounds for efficient online learning with deep neural networks. Specifically, we show that over any sequence of convex loss functions, any low-regret algorithm can be adapted to optimize the parameters of a neural network such that it competes with the best net in hindsight. As an application of these results in the online setting, we obtain provable bounds for online episodic control with deep neural network controllers.
Machine Learning for Mechanical Ventilation Control
Feb 26, 2021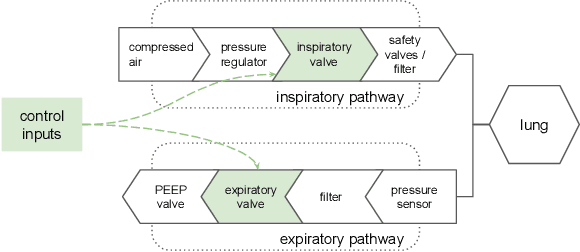
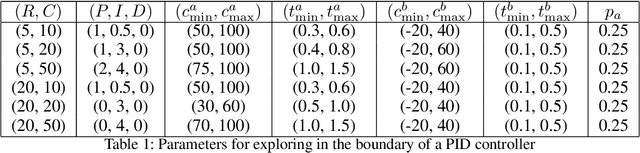
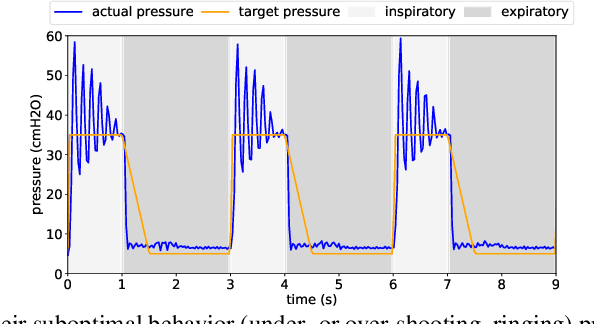
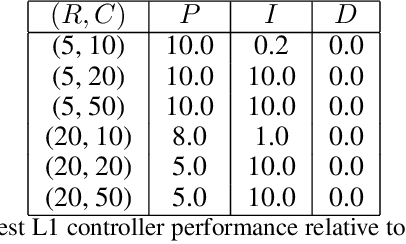
We consider the problem of controlling an invasive mechanical ventilator for pressure-controlled ventilation: a controller must let air in and out of a sedated patient's lungs according to a trajectory of airway pressures specified by a clinician. Hand-tuned PID controllers and similar variants have comprised the industry standard for decades, yet can behave poorly by over- or under-shooting their target or oscillating rapidly. We consider a data-driven machine learning approach: First, we train a simulator based on data we collect from an artificial lung. Then, we train deep neural network controllers on these simulators.We show that our controllers are able to track target pressure waveforms significantly better than PID controllers. We further show that a learned controller generalizes across lungs with varying characteristics much more readily than PID controllers do.
Adaptive Regret for Control of Time-Varying Dynamics
Jul 16, 2020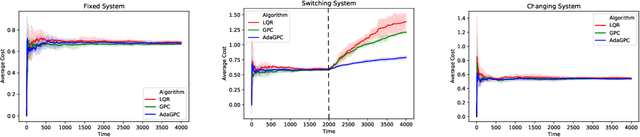
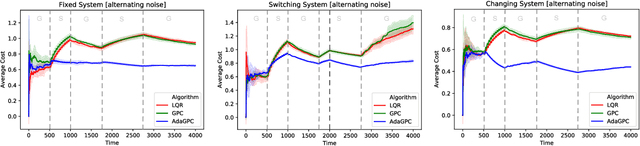
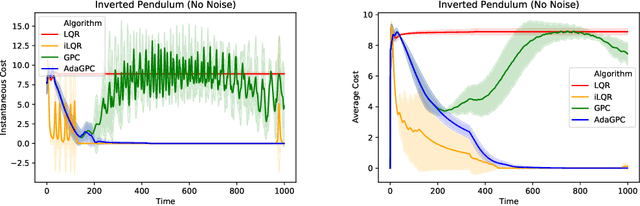
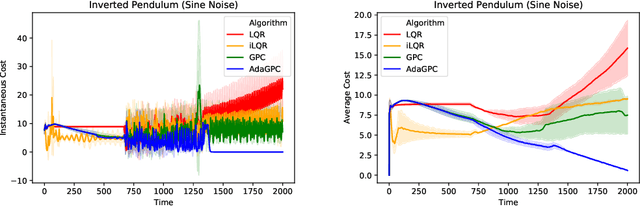
We consider regret minimization for online control with time-varying linear dynamical systems. The metric of performance we study is adaptive policy regret, or regret compared to the best policy on {\it any interval in time}. We give an efficient algorithm that attains first-order adaptive regret guarantees for the setting of online convex optimization with memory. We also show that these first-order bounds are nearly tight. This algorithm is then used to derive a controller with adaptive regret guarantees that provably competes with the best linear dynamical controller on any interval in time. We validate these theoretical findings experimentally on (1) simulations of time-varying linear dynamics and disturbances, and (2) the non-linear inverted pendulum benchmark.
Faster Projection-free Online Learning
Feb 14, 2020
In many online learning problems the computational bottleneck for gradient-based methods is the projection operation. For this reason, in many problems the most efficient algorithms are based on the Frank-Wolfe method, which replaces projections by linear optimization. In the general case, however, online projection-free methods require more iterations than projection-based methods: the best known regret bound scales as $T^{3/4}$. Despite significant work on various variants of the Frank-Wolfe method, this bound has remained unchanged for a decade. In this paper we give an efficient projection-free algorithm that guarantees $T^{2/3}$ regret for general online convex optimization with smooth cost functions and one linear optimization computation per iteration. As opposed to previous Frank-Wolfe approaches, our algorithm is derived using the Follow-the-Perturbed-Leader method and is analyzed using an online primal-dual framework.