 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexel Splatting: Perspective-Stable 3D Pixel Art
Mar 15, 2026Rendering 3D scenes as pixel art requires that discrete pixels remain stable as the camera moves. Existing methods snap the camera to a grid. Under orthographic projection, this works: every pixel shifts by the same amount, and a single snap corrects all of them. Perspective breaks this. Pixels at different depths drift at different rates, and no single snap corrects all depths. Texel splatting avoids this entirely. Scene geometry is rendered into a cubemap from a fixed point in the world, and each texel is splatted to the screen as a world-space quad. Cubemap indexing gives rotation invariance. Grid-snapping the origin gives translation invariance. The primary limitation is that a fixed origin cannot see all geometry; disocclusion at probe boundaries remains an open tradeoff.
3D Arena: An Open Platform for Generative 3D Evaluation
Jun 23, 2025Evaluating Generative 3D models remains challenging due to misalignment between automated metrics and human perception of quality. Current benchmarks rely on image-based metrics that ignore 3D structure or geometric measures that fail to capture perceptual appeal and real-world utility. To address this gap, we present 3D Arena, an open platform for evaluating image-to-3D generation models through large-scale human preference collection using pairwise comparisons. Since launching in June 2024, the platform has collected 123,243 votes from 8,096 users across 19 state-of-the-art models, establishing the largest human preference evaluation for Generative 3D. We contribute the iso3d dataset of 100 evaluation prompts and demonstrate quality control achieving 99.75% user authenticity through statistical fraud detection. Our ELO-based ranking system provides reliable model assessment, with the platform becoming an established evaluation resource. Through analysis of this preference data, we present insights into human preference patterns. Our findings reveal preferences for visual presentation features, with Gaussian splat outputs achieving a 16.6 ELO advantage over meshes and textured models receiving a 144.1 ELO advantage over untextured models. We provide recommendations for improving evaluation methods, including multi-criteria assessment, task-oriented evaluation, and format-aware comparison. The platform's community engagement establishes 3D Arena as a benchmark for the field while advancing understanding of human-centered evaluation in Generative 3D.
Pretraining on Interactions for Learning Grounded Affordance Representations
Jul 05, 2022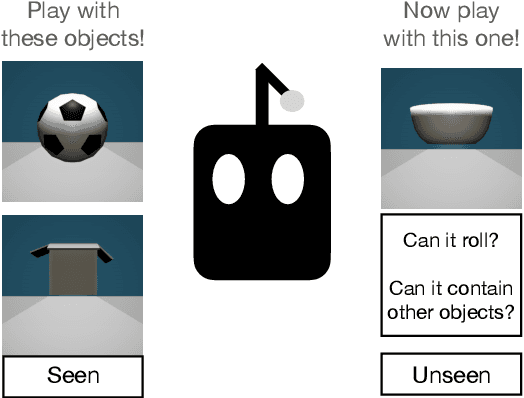
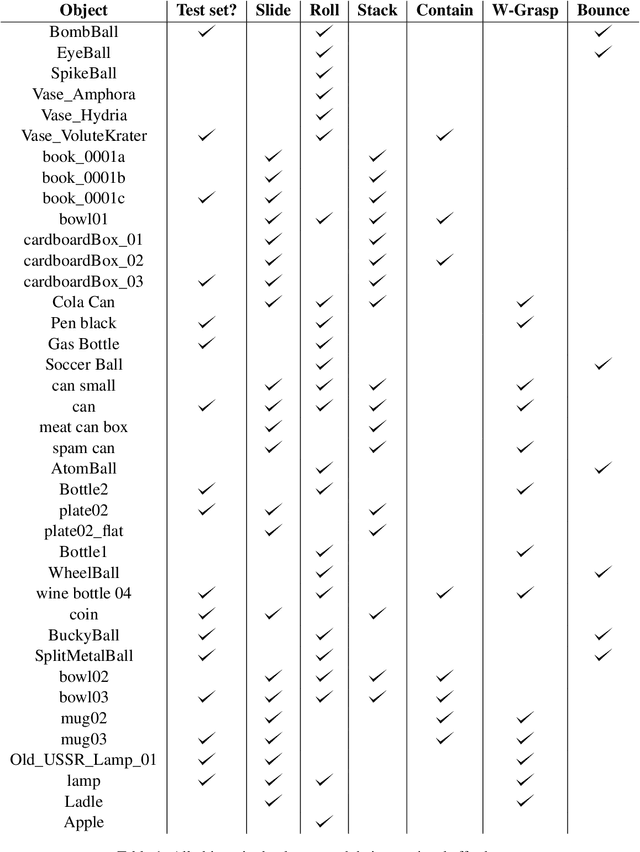

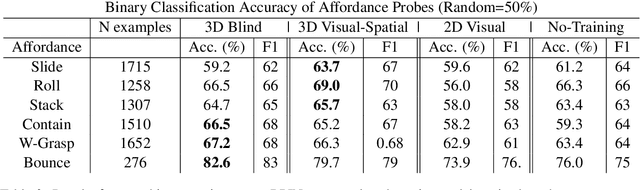
Lexical semantics and cognitive science point to affordances (i.e. the actions that objects support) as critical for understanding and representing nouns and verbs. However, study of these semantic features has not yet been integrated with the "foundation" models that currently dominate language representation research. We hypothesize that predictive modeling of object state over time will result in representations that encode object affordance information "for free". We train a neural network to predict objects' trajectories in a simulated interaction and show that our network's latent representations differentiate between both observed and unobserved affordances. We find that models trained using 3D simulations from our SPATIAL dataset outperform conventional 2D computer vision models trained on a similar task, and, on initial inspection, that differences between concepts correspond to expected features (e.g., roll entails rotation). Our results suggest a way in which modern deep learning approaches to grounded language learning can be integrated with traditional formal semantic notions of lexical representations.
Do Trajectories Encode Verb Meaning?
Jun 23, 2022


Distributional models learn representations of words from text, but are criticized for their lack of grounding, or the linking of text to the non-linguistic world. Grounded language models have had success in learning to connect concrete categories like nouns and adjectives to the world via images and videos, but can struggle to isolate the meaning of the verbs themselves from the context in which they typically occur. In this paper, we investigate the extent to which trajectories (i.e. the position and rotation of objects over time) naturally encode verb semantics. We build a procedurally generated agent-object-interaction dataset, obtain human annotations for the verbs that occur in this data, and compare several methods for representation learning given the trajectories. We find that trajectories correlate as-is with some verbs (e.g., fall), and that additional abstraction via self-supervised pretraining can further capture nuanced differences in verb meaning (e.g., roll vs. slide).
A Visuospatial Dataset for Naturalistic Verb Learning
Oct 28, 2020

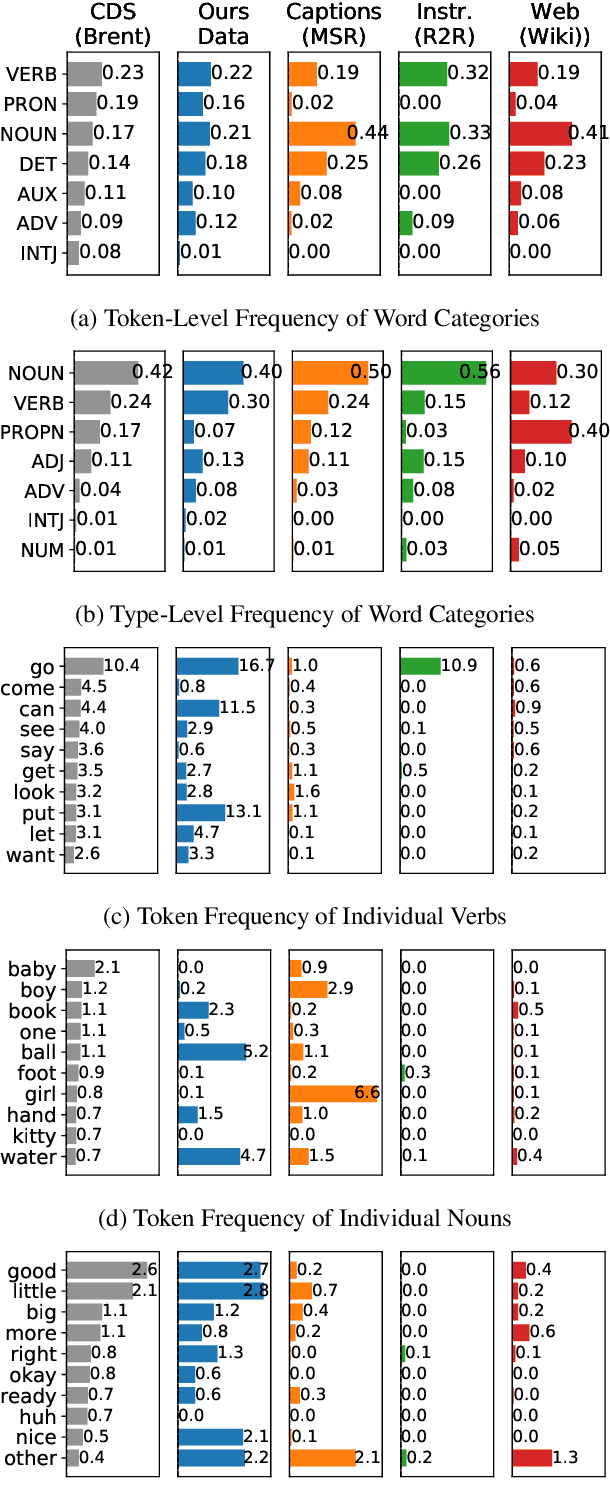
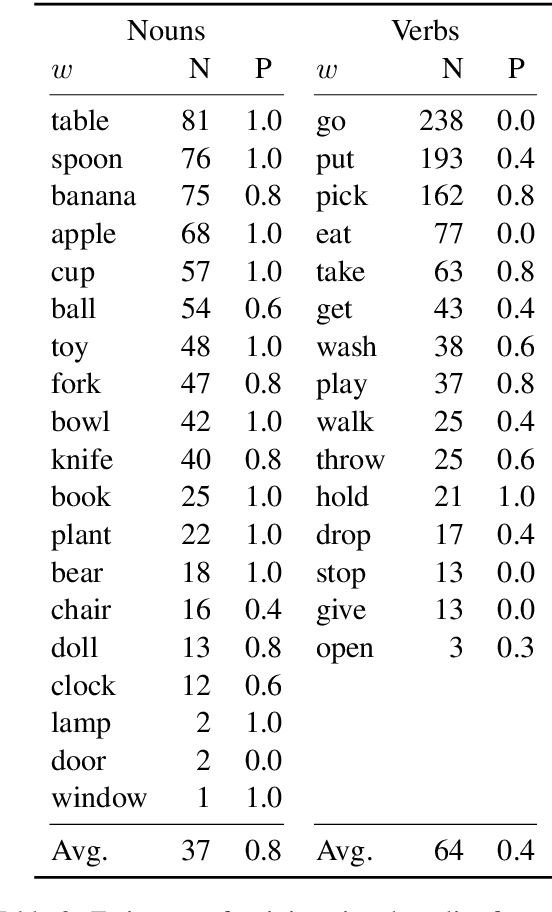
We introduce a new dataset for training and evaluating grounded language models. Our data is collected within a virtual reality environment and is designed to emulate the quality of language data to which a pre-verbal child is likely to have access: That is, naturalistic, spontaneous speech paired with richly grounded visuospatial context. We use the collected data to compare several distributional semantics models for verb learning. We evaluate neural models based on 2D (pixel) features as well as feature-engineered models based on 3D (symbolic, spatial) features, and show that neither modeling approach achieves satisfactory performance. Our results are consistent with evidence from child language acquisition that emphasizes the difficulty of learning verbs from naive distributional data. We discuss avenues for future work on cognitively-inspired grounded language learning, and release our corpus with the intent of facilitating research on the topic.
Improving the Accuracy of the CogniLearn System for Cognitive Behavior Assessment
Mar 25, 2017
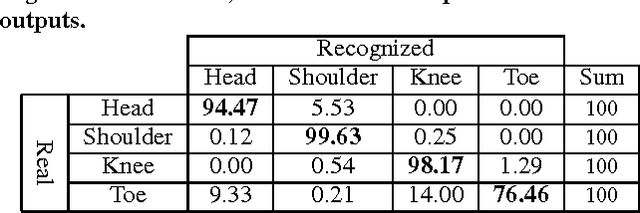
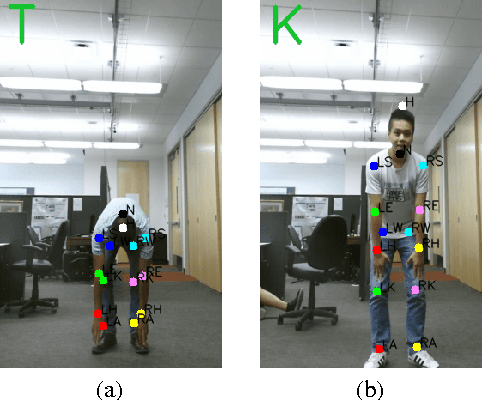
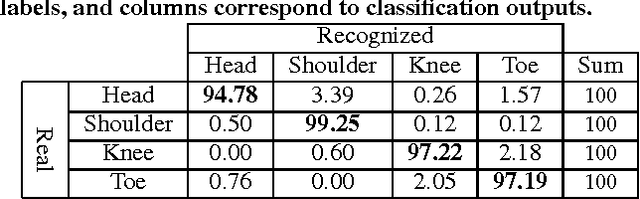
HTKS is a game-like cognitive assessment method, designed for children between four and eight years of age. During the HTKS assessment, a child responds to a sequence of requests, such as "touch your head" or "touch your toes". The cognitive challenge stems from the fact that the children are instructed to interpret these requests not literally, but by touching a different body part than the one stated. In prior work, we have developed the CogniLearn system, that captures data from subjects performing the HTKS game, and analyzes the motion of the subjects. In this paper we propose some specific improvements that make the motion analysis module more accurate. As a result of these improvements, the accuracy in recognizing cases where subjects touch their toes has gone from 76.46% in our previous work to 97.19% in this paper.
Enhanced Facial Recognition Framework based on Skin Tone and False Alarm Rejection
Feb 14, 2017
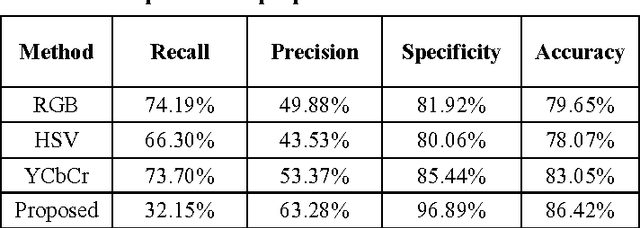

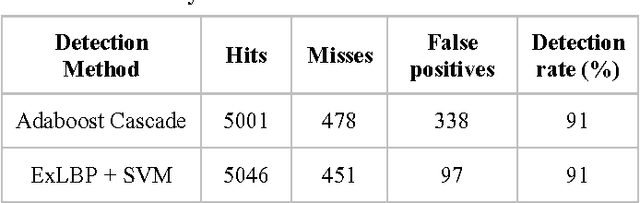
Face detection is one of the challenging tasks in computer vision. Human face detection plays an essential role in the first stage of face processing applications such as face recognition, face tracking, image database management, etc. In these applications, face objects often come from an inconsequential part of images that contain variations, namely different illumination, poses, and occlusion. These variations can decrease face detection rate noticeably. Most existing face detection approaches are not accurate, as they have not been able to resolve unstructured images due to large appearance variations and can only detect human faces under one particular variation. Existing frameworks of face detection need enhancements to detect human faces under the stated variations to improve detection rate and reduce detection time. In this study, an enhanced face detection framework is proposed to improve detection rate based on skin color and provide a validation process. A preliminary segmentation of the input images based on skin color can significantly reduce search space and accelerate the process of human face detection. The primary detection is based on Haar-like features and the Adaboost algorithm. A validation process is introduced to reject non-face objects, which might occur during the face detection process. The validation process is based on two-stage Extended Local Binary Patterns. The experimental results on the CMU-MIT and Caltech 10000 datasets over a wide range of facial variations in different colors, positions, scales, and lighting conditions indicated a successful face detection rate.