 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Visuospatial Dataset for Naturalistic Verb Learning
Paper and Code


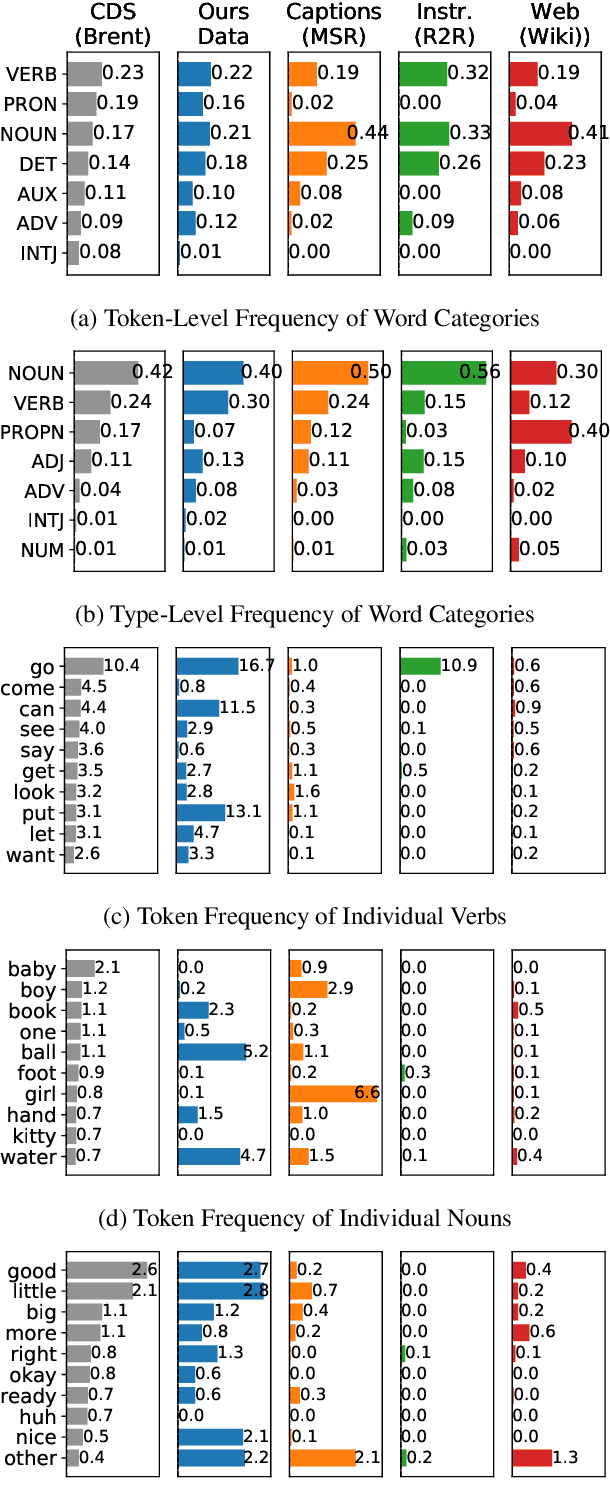
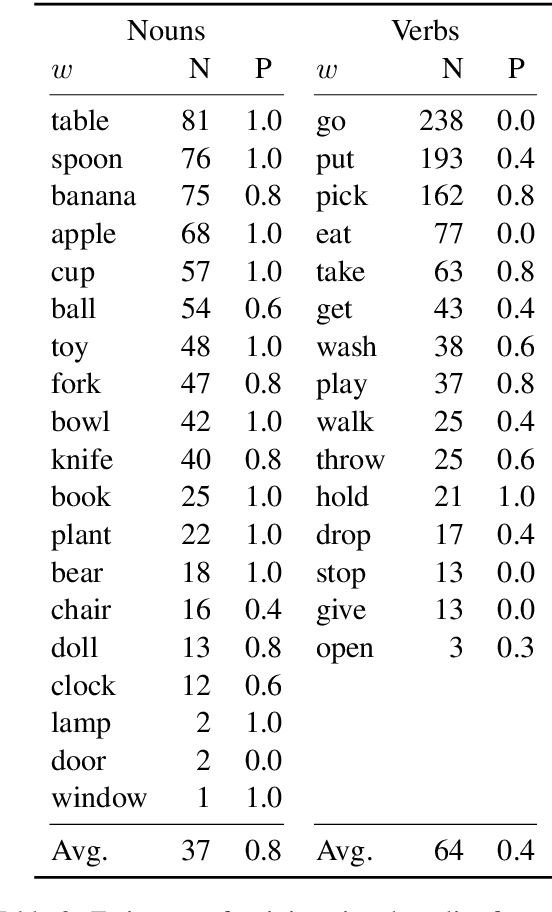
We introduce a new dataset for training and evaluating grounded language models. Our data is collected within a virtual reality environment and is designed to emulate the quality of language data to which a pre-verbal child is likely to have access: That is, naturalistic, spontaneous speech paired with richly grounded visuospatial context. We use the collected data to compare several distributional semantics models for verb learning. We evaluate neural models based on 2D (pixel) features as well as feature-engineered models based on 3D (symbolic, spatial) features, and show that neither modeling approach achieves satisfactory performance. Our results are consistent with evidence from child language acquisition that emphasizes the difficulty of learning verbs from naive distributional data. We discuss avenues for future work on cognitively-inspired grounded language learning, and release our corpus with the intent of facilitating research on the topic.