 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Trajectories Encode Verb Meaning?
Paper and Code



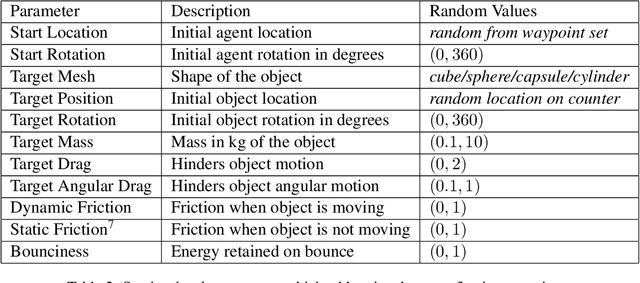
Distributional models learn representations of words from text, but are criticized for their lack of grounding, or the linking of text to the non-linguistic world. Grounded language models have had success in learning to connect concrete categories like nouns and adjectives to the world via images and videos, but can struggle to isolate the meaning of the verbs themselves from the context in which they typically occur. In this paper, we investigate the extent to which trajectories (i.e. the position and rotation of objects over time) naturally encode verb semantics. We build a procedurally generated agent-object-interaction dataset, obtain human annotations for the verbs that occur in this data, and compare several methods for representation learning given the trajectories. We find that trajectories correlate as-is with some verbs (e.g., fall), and that additional abstraction via self-supervised pretraining can further capture nuanced differences in verb meaning (e.g., roll vs. slide).