 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Where to Deploy: Metric RGB-Based Traversability Analysis for Aerial-to-Ground Hidden Space Inspection
Mar 15, 2026Inspection of confined infrastructure such as culverts often requires accessing hidden spaces whose entrances are reachable primarily from elevated viewpoints. Aerial-ground cooperation enables a UAV to deploy a compact UGV for interior exploration, but selecting a suitable deployment region from aerial observations requires metric terrain reasoning involving scale ambiguity, reconstruction uncertainty, and terrain semantics. We present a metric RGB-based geometric-semantic reconstruction and traversability analysis framework for aerial-to-ground hidden space inspection. A feed-forward multi-view RGB reconstruction backbone produces dense geometry, while temporally consistent semantic segmentation yields a 3D semantic map. To enable deployment-relevant measurements without LiDAR-based dense mapping, we introduce an embodied motion prior that recovers metric scale by enforcing consistency between predicted camera motion and onboard platform egomotion. From the metrically grounded reconstruction, we construct a confidence-aware geometric-semantic traversability map and evaluate candidate deployment zones under explicit reachability constraints. Experiments on a tethered UAV-UGV platform demonstrate reliable deployment-zone identification in hidden space scenarios.
LPV-MPC for Lateral Control in Full-Scale Autonomous Racing
Mar 14, 2026Autonomous racing has attracted significant attention recently, presenting challenges in selecting an optimal controller that operates within the onboard system's computational limits and meets operational constraints such as limited track time and high costs. This paper introduces a Linear Parameter-Varying Model Predictive Controller (LPV-MPC) for lateral control. Implemented on an IAC AV-24, the controller achieved stable performance at speeds exceeding 160 mph (71.5 m/s). We detail the controller design, the methodology for extracting model parameters, and key system-level and implementation considerations. Additionally, we report results from our final race run, providing a comprehensive analysis of both vehicle dynamics and controller performance. A Python implementation of the framework is available at: https://tinyurl.com/LPV-MPC-acados
MiniUGV$_2$: A Compact UAV-Deployable Tracked Ground Vehicle with Manipulation Capabilities
Mar 01, 2026Exploring and inspecting \emph{Hidden Spaces}, defined as environments whose entrances are accessible only to aerial robots but remain unexplored due to geometric constraints, limited flight time, and communication loss, remains a major challenge. We present miniUGV$_2$, a compact UAV-deployable tracked ground vehicle that extends UAV capabilities into confined environments. The system introduces dual articulated arms, integrated LiDAR and depth sensing, and modular electronics for enhanced autonomy. A novel tether module with an electro-permanent magnetic head enables safe deployment, retrieval, and optional detachment, thereby overcoming prior entanglement issues. Experiments demonstrate robust terrain navigation, self-righting, and manipulation of objects up to 3.5 kg, validating miniUGV$_2$ as a versatile platform for hybrid aerial-ground robotics.
Navigating the Wild: Pareto-Optimal Visual Decision-Making in Image Space
Nov 11, 2025Navigating complex real-world environments requires semantic understanding and adaptive decision-making. Traditional reactive methods without maps often fail in cluttered settings, map-based approaches demand heavy mapping effort, and learning-based solutions rely on large datasets with limited generalization. To address these challenges, we present Pareto-Optimal Visual Navigation, a lightweight image-space framework that combines data-driven semantics, Pareto-optimal decision-making, and visual servoing for real-time navigation.
AFRDA: Attentive Feature Refinement for Domain Adaptive Semantic Segmentation
Jul 23, 2025In Unsupervised Domain Adaptive Semantic Segmentation (UDA-SS), a model is trained on labeled source domain data (e.g., synthetic images) and adapted to an unlabeled target domain (e.g., real-world images) without access to target annotations. Existing UDA-SS methods often struggle to balance fine-grained local details with global contextual information, leading to segmentation errors in complex regions. To address this, we introduce the Adaptive Feature Refinement (AFR) module, which enhances segmentation accuracy by refining highresolution features using semantic priors from low-resolution logits. AFR also integrates high-frequency components, which capture fine-grained structures and provide crucial boundary information, improving object delineation. Additionally, AFR adaptively balances local and global information through uncertaintydriven attention, reducing misclassifications. Its lightweight design allows seamless integration into HRDA-based UDA methods, leading to state-of-the-art segmentation performance. Our approach improves existing UDA-SS methods by 1.05% mIoU on GTA V --> Cityscapes and 1.04% mIoU on Synthia-->Cityscapes. The implementation of our framework is available at: https://github.com/Masrur02/AFRDA
Context-Generative Default Policy for Bounded Rational Agent
Sep 17, 2024Bounded rational agents often make decisions by evaluating a finite selection of choices, typically derived from a reference point termed the $`$default policy,' based on previous experience. However, the inherent rigidity of the static default policy presents significant challenges for agents when operating in unknown environment, that are not included in agent's prior knowledge. In this work, we introduce a context-generative default policy that leverages the region observed by the robot to predict unobserved part of the environment, thereby enabling the robot to adaptively adjust its default policy based on both the actual observed map and the $\textit{imagined}$ unobserved map. Furthermore, the adaptive nature of the bounded rationality framework enables the robot to manage unreliable or incorrect imaginations by selectively sampling a few trajectories in the vicinity of the default policy. Our approach utilizes a diffusion model for map prediction and a sampling-based planning with B-spline trajectory optimization to generate the default policy. Extensive evaluations reveal that the context-generative policy outperforms the baseline methods in identifying and avoiding unseen obstacles. Additionally, real-world experiments conducted with the Crazyflie drones demonstrate the adaptability of our proposed method, even when acting in environments outside the domain of the training distribution.
POVNav: A Pareto-Optimal Mapless Visual Navigator
Oct 21, 2023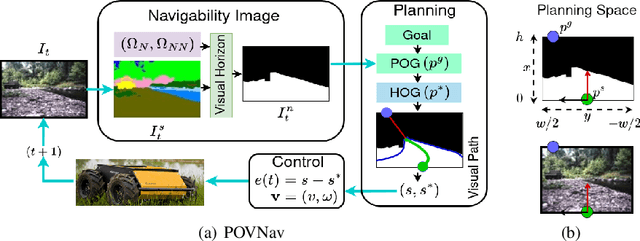
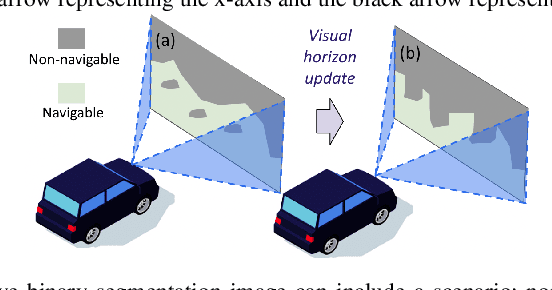
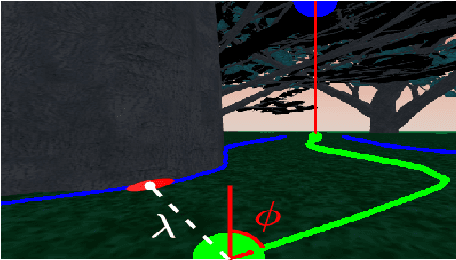
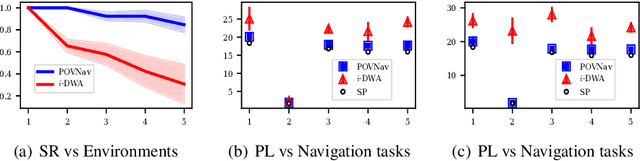
Mapless navigation has emerged as a promising approach for enabling autonomous robots to navigate in environments where pre-existing maps may be inaccurate, outdated, or unavailable. In this work, we propose an image-based local representation of the environment immediately around a robot to parse navigability. We further develop a local planning and control framework, a Pareto-optimal mapless visual navigator (POVNav), to use this representation and enable autonomous navigation in various challenging and real-world environments. In POVNav, we choose a Pareto-optimal sub-goal in the image by evaluating all the navigable pixels, finding a safe visual path, and generating actions to follow the path using visual servo control. In addition to providing collision-free motion, our approach enables selective navigation behavior, such as restricting navigation to select terrain types, by only changing the navigability definition in the local representation. The ability of POVNav to navigate a robot to the goal using only a monocular camera without relying on a map makes it computationally light and easy to implement on various robotic platforms. Real-world experiments in diverse challenging environments, ranging from structured indoor environments to unstructured outdoor environments such as forest trails and roads after a heavy snowfall, using various image segmentation techniques demonstrate the remarkable efficacy of our proposed framework.
Coordination of Bounded Rational Drones through Informed Prior Policy
Jul 28, 2023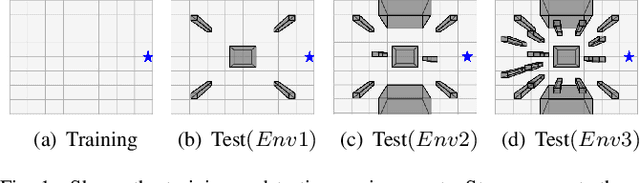
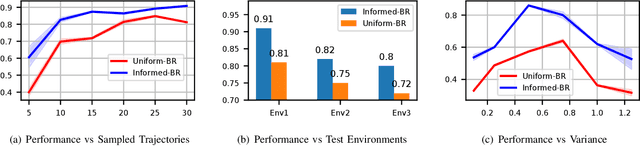
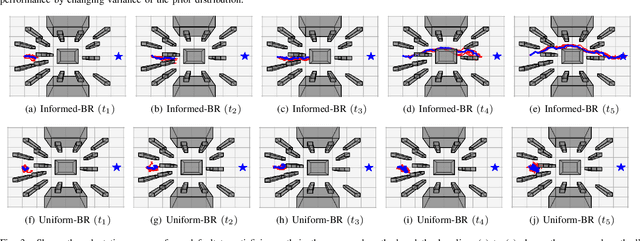
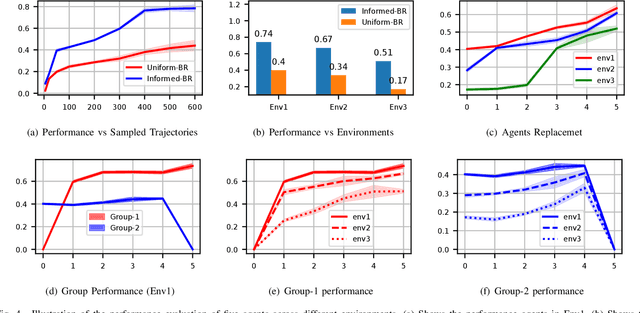
Biological agents, such as humans and animals, are capable of making decisions out of a very large number of choices in a limited time. They can do so because they use their prior knowledge to find a solution that is not necessarily optimal but good enough for the given task. In this work, we study the motion coordination of multiple drones under the above-mentioned paradigm, Bounded Rationality (BR), to achieve cooperative motion planning tasks. Specifically, we design a prior policy that provides useful goal-directed navigation heuristics in familiar environments and is adaptive in unfamiliar ones via Reinforcement Learning augmented with an environment-dependent exploration noise. Integrating this prior policy in the game-theoretic bounded rationality framework allows agents to quickly make decisions in a group considering other agents' computational constraints. Our investigation assures that agents with a well-informed prior policy increase the efficiency of the collective decision-making capability of the group. We have conducted rigorous experiments in simulation and in the real world to demonstrate that the ability of informed agents to navigate to the goal safely can guide the group to coordinate efficiently under the BR framework.
Pseudo-Trilateral Adversarial Training for Domain Adaptive Traversability Prediction
Jun 26, 2023Traversability prediction is a fundamental perception capability for autonomous navigation. Deep neural networks (DNNs) have been widely used to predict traversability during the last decade. The performance of DNNs is significantly boosted by exploiting a large amount of data. However, the diversity of data in different domains imposes significant gaps in the prediction performance. In this work, we make efforts to reduce the gaps by proposing a novel pseudo-trilateral adversarial model that adopts a coarse-to-fine alignment (CALI) to perform unsupervised domain adaptation (UDA). Our aim is to transfer the perception model with high data efficiency, eliminate the prohibitively expensive data labeling, and improve the generalization capability during the adaptation from easy-to-access source domains to various challenging target domains. Existing UDA methods usually adopt a bilateral zero-sum game structure. We prove that our CALI model -- a pseudo-trilateral game structure is advantageous over existing bilateral game structures. This proposed work bridges theoretical analyses and algorithm designs, leading to an efficient UDA model with easy and stable training. We further develop a variant of CALI -- Informed CALI (ICALI), which is inspired by the recent success of mixup data augmentation techniques and mixes informative regions based on the results of CALI. This mixture step provides an explicit bridging between the two domains and exposes underperforming classes more during training. We show the superiorities of our proposed models over multiple baselines in several challenging domain adaptation setups. To further validate the effectiveness of our proposed models, we then combine our perception model with a visual planner to build a navigation system and show the high reliability of our model in complex natural environments.
Decision-Making Among Bounded Rational Agents
Oct 17, 2022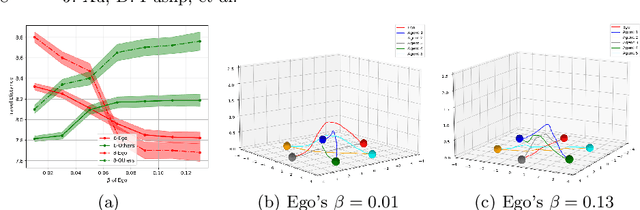
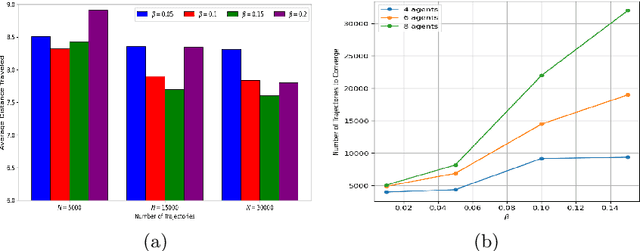
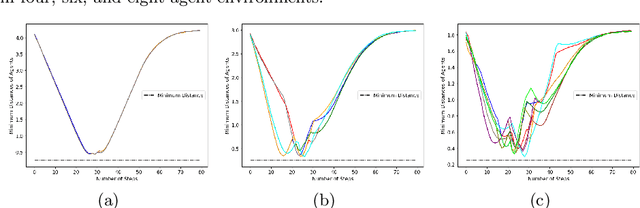
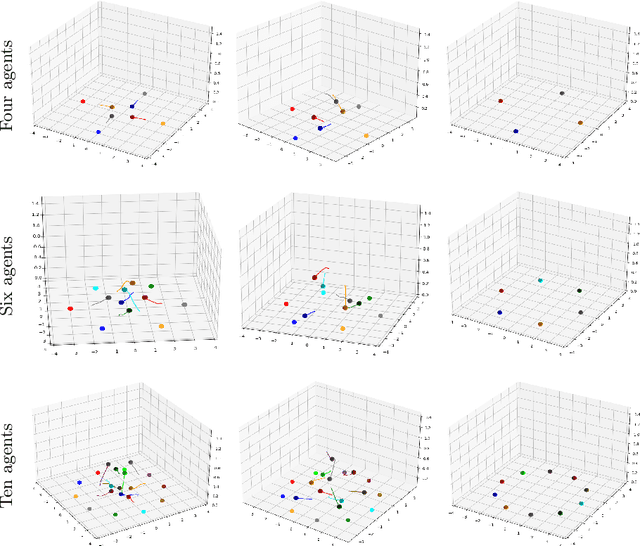
When robots share the same workspace with other intelligent agents (e.g., other robots or humans), they must be able to reason about the behaviors of their neighboring agents while accomplishing the designated tasks. In practice, frequently, agents do not exhibit absolutely rational behavior due to their limited computational resources. Thus, predicting the optimal agent behaviors is undesirable (because it demands prohibitive computational resources) and undesirable (because the prediction may be wrong). Motivated by this observation, we remove the assumption of perfectly rational agents and propose incorporating the concept of bounded rationality from an information-theoretic view into the game-theoretic framework. This allows the robots to reason other agents' sub-optimal behaviors and act accordingly under their computational constraints. Specifically, bounded rationality directly models the agent's information processing ability, which is represented as the KL-divergence between nominal and optimized stochastic policies, and the solution to the bounded-optimal policy can be obtained by an efficient importance sampling approach. Using both simulated and real-world experiments in multi-robot navigation tasks, we demonstrate that the resulting framework allows the robots to reason about different levels of rational behaviors of other agents and compute a reasonable strategy under its computational constraint.