 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Greedy Method (LGM): A Novel Neural Architecture for Sparse Coding and Beyond
Oct 20, 2020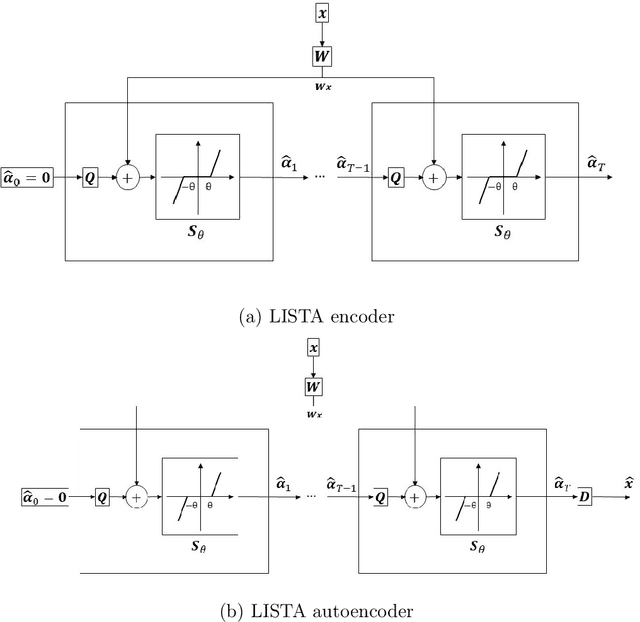
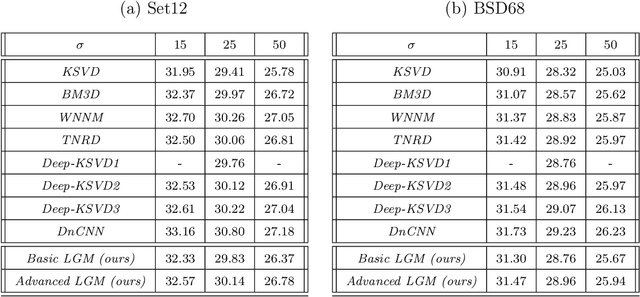
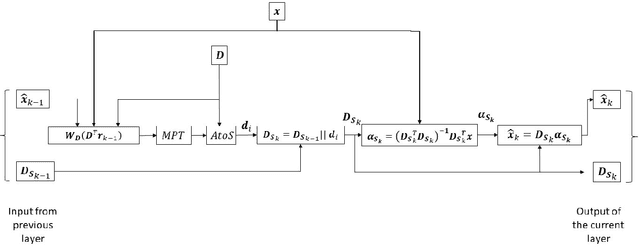
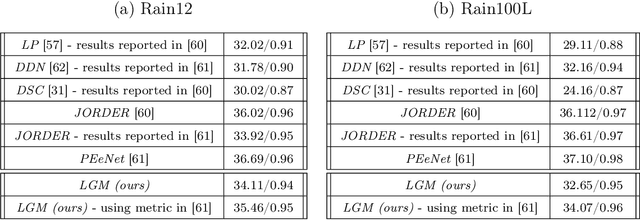
The fields of signal and image processing have been deeply influenced by the introduction of deep neural networks. These are successfully deployed in a wide range of real-world applications, obtaining state of the art results and surpassing well-known and well-established classical methods. Despite their impressive success, the architectures used in many of these neural networks come with no clear justification. As such, these are usually treated as "black box" machines that lack any kind of interpretability. A constructive remedy to this drawback is a systematic design of such networks by unfolding well-understood iterative algorithms. A popular representative of this approach is the Iterative Shrinkage-Thresholding Algorithm (ISTA) and its learned version -- LISTA, aiming for the sparse representations of the processed signals. In this paper we revisit this sparse coding task and propose an unfolded version of a greedy pursuit algorithm for the same goal. More specifically, we concentrate on the well-known Orthogonal-Matching-Pursuit (OMP) algorithm, and introduce its unfolded and learned version. Key features of our Learned Greedy Method (LGM) are the ability to accommodate a dynamic number of unfolded layers, and a stopping mechanism based on representation error, both adapted to the input. We develop several variants of the proposed LGM architecture and test some of them in various experiments, demonstrating their flexibility and efficiency.
When and How Can Deep Generative Models be Inverted?
Jun 28, 2020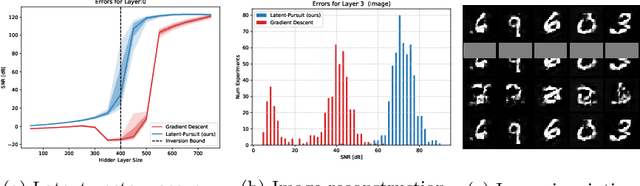


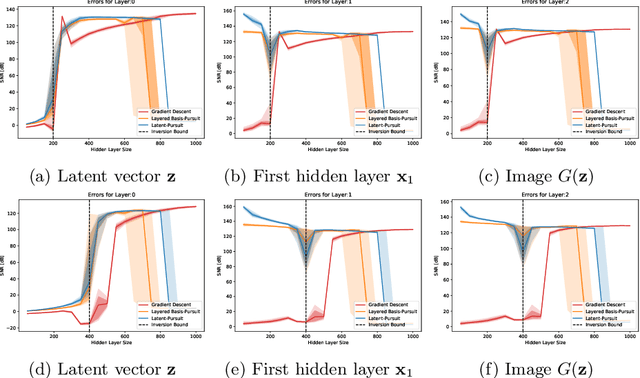
Deep generative models (e.g. GANs and VAEs) have been developed quite extensively in recent years. Lately, there has been an increased interest in the inversion of such a model, i.e. given a (possibly corrupted) signal, we wish to recover the latent vector that generated it. Building upon sparse representation theory, we define conditions that are applicable to any inversion algorithm (gradient descent, deep encoder, etc.), under which such generative models are invertible with a unique solution. Importantly, the proposed analysis is applicable to any trained model, and does not depend on Gaussian i.i.d. weights. Furthermore, we introduce two layer-wise inversion pursuit algorithms for trained generative networks of arbitrary depth, and accompany these with recovery guarantees. Finally, we validate our theoretical results numerically and show that our method outperforms gradient descent when inverting such generators, both for clean and corrupted signals.
Barycenters of Natural Images -- Constrained Wasserstein Barycenters for Image Morphing
Dec 24, 2019

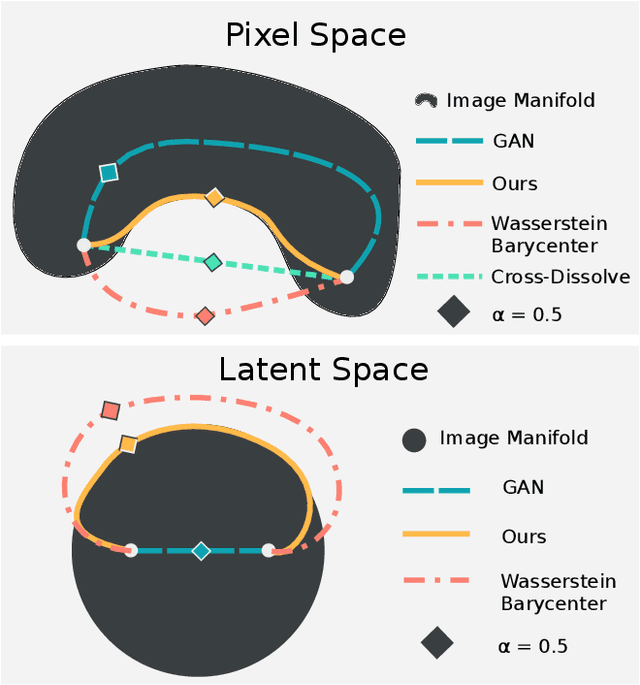

Image interpolation, or image morphing, refers to a visual transition between two (or more) input images. For such a transition to look visually appealing, its desirable properties are (i) to be smooth; (ii) to apply the minimal required change in the image; and (iii) to seem "real", avoiding unnatural artifacts in each image in the transition. To obtain a smooth and straightforward transition, one may adopt the well-known Wasserstein Barycenter Problem (WBP). While this approach guarantees minimal changes under the Wasserstein metric, the resulting images might seem unnatural. In this work, we propose a novel approach for image morphing that possesses all three desired properties. To this end, we define a constrained variant of the WBP that enforces the intermediate images to satisfy an image prior. We describe an algorithm that solves this problem and demonstrate it using the sparse prior and generative adversarial networks.
Auto-Annotation Quality Prediction for Semi-Supervised Learning with Ensembles
Oct 30, 2019
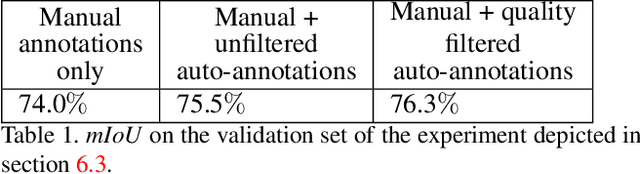


Auto-annotation by ensemble of models is an efficient method of learning on unlabeled data. Wrong or inaccurate annotations generated by the ensemble may lead to performance degradation of the trained model. To deal with this problem we propose filtering the auto-labeled data using a trained model that predicts the quality of the annotation from the degree of consensus between ensemble models. Using semantic segmentation as an example, we show the advantage of the proposed auto-annotation filtering over training on data contaminated with inaccurate labels. Moreover, our experimental results show that in the case of semantic segmentation, the performance of a state-of-the-art model can be achieved by training it with only a fraction (30$\%$) of the original manually labeled data set, and replacing the rest with the auto-annotated, quality filtered labels.
Rethinking the CSC Model for Natural Images
Sep 12, 2019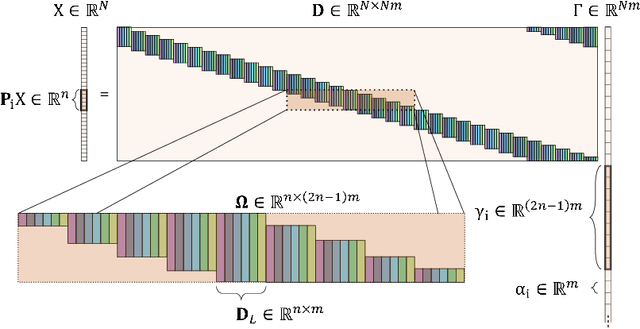
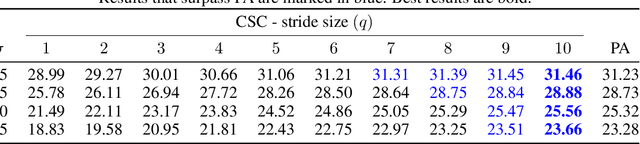
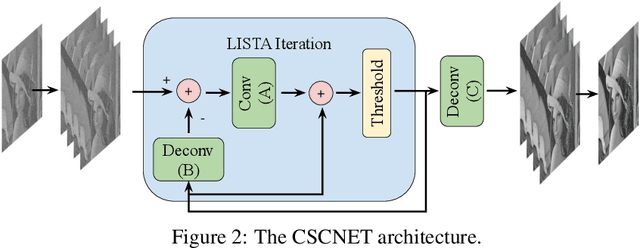
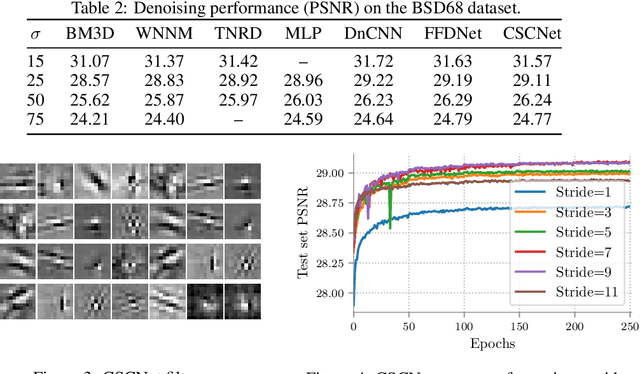
Sparse representation with respect to an overcomplete dictionary is often used when regularizing inverse problems in signal and image processing. In recent years, the Convolutional Sparse Coding (CSC) model, in which the dictionary consists of shift-invariant filters, has gained renewed interest. While this model has been successfully used in some image processing problems, it still falls behind traditional patch-based methods on simple tasks such as denoising. In this work we provide new insights regarding the CSC model and its capability to represent natural images, and suggest a Bayesian connection between this model and its patch-based ancestor. Armed with these observations, we suggest a novel feed-forward network that follows an MMSE approximation process to the CSC model, using strided convolutions. The performance of this supervised architecture is shown to be on par with state of the art methods while using much fewer parameters.
MMSE Approximation For Sparse Coding Algorithms Using Stochastic Resonance
Oct 22, 2018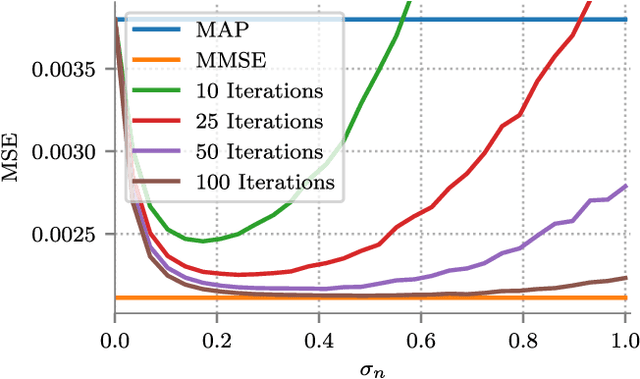

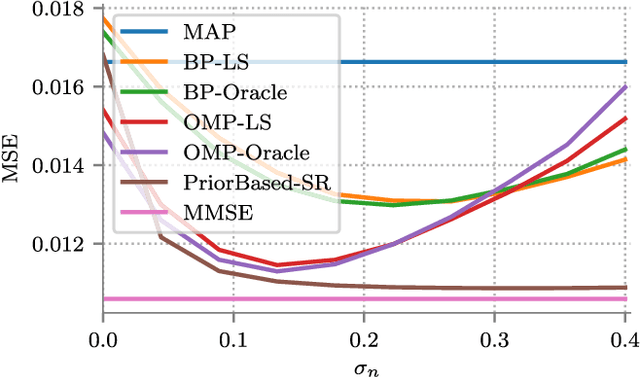
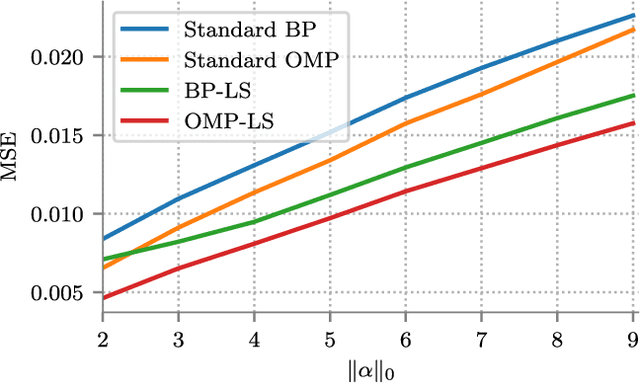
Sparse coding refers to the pursuit of the sparsest representation of a signal in a typically overcomplete dictionary. From a Bayesian perspective, sparse coding provides a Maximum a Posteriori (MAP) estimate of the unknown vector under a sparse prior. Various nonlinear algorithms are available to approximate the solution of such problems. In this work, we suggest enhancing the performance of sparse coding algorithms by a deliberate and controlled contamination of the input with random noise, a phenomenon known as stochastic resonance. This not only allows for increased performance, but also provides a computationally efficient approximation to the Minimum Mean Square Error (MMSE) estimator, which is ordinarily intractable to compute. We demonstrate our findings empirically and provide a theoretical analysis of our method under several different cases.