 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Annotation Quality Prediction for Semi-Supervised Learning with Ensembles
Paper and Code

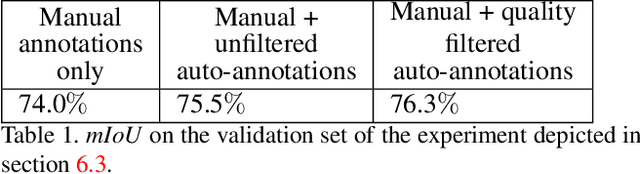


Auto-annotation by ensemble of models is an efficient method of learning on unlabeled data. Wrong or inaccurate annotations generated by the ensemble may lead to performance degradation of the trained model. To deal with this problem we propose filtering the auto-labeled data using a trained model that predicts the quality of the annotation from the degree of consensus between ensemble models. Using semantic segmentation as an example, we show the advantage of the proposed auto-annotation filtering over training on data contaminated with inaccurate labels. Moreover, our experimental results show that in the case of semantic segmentation, the performance of a state-of-the-art model can be achieved by training it with only a fraction (30$\%$) of the original manually labeled data set, and replacing the rest with the auto-annotated, quality filtered labels.