 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHATNet: An End-to-End Holistic Attention Network for Diagnosis of Breast Biopsy Images
Jul 25, 2020
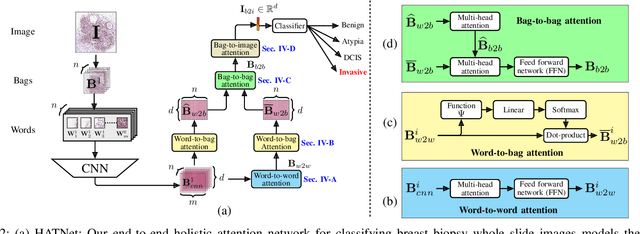
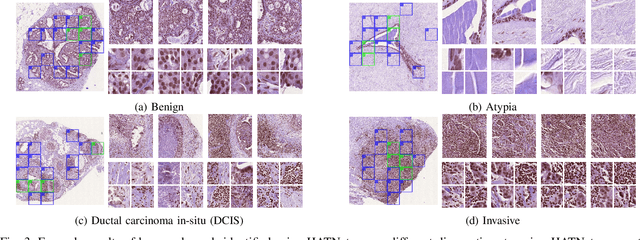
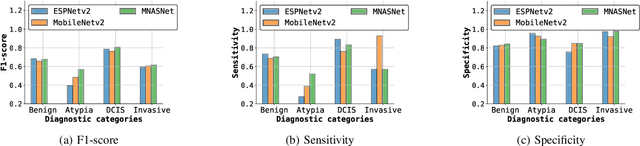
Training end-to-end networks for classifying gigapixel size histopathological images is computationally intractable. Most approaches are patch-based and first learn local representations (patch-wise) before combining these local representations to produce image-level decisions. However, dividing large tissue structures into patches limits the context available to these networks, which may reduce their ability to learn representations from clinically relevant structures. In this paper, we introduce a novel attention-based network, the Holistic ATtention Network (HATNet) to classify breast biopsy images. We streamline the histopathological image classification pipeline and show how to learn representations from gigapixel size images end-to-end. HATNet extends the bag-of-words approach and uses self-attention to encode global information, allowing it to learn representations from clinically relevant tissue structures without any explicit supervision. It outperforms the previous best network Y-Net, which uses supervision in the form of tissue-level segmentation masks, by 8%. Importantly, our analysis reveals that HATNet learns representations from clinically relevant structures, and it matches the classification accuracy of human pathologists for this challenging test set. Our source code is available at \url{https://github.com/sacmehta/HATNet}
Learning to Segment Breast Biopsy Whole Slide Images
Oct 10, 2017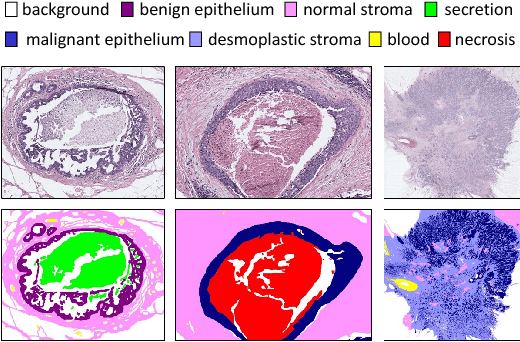
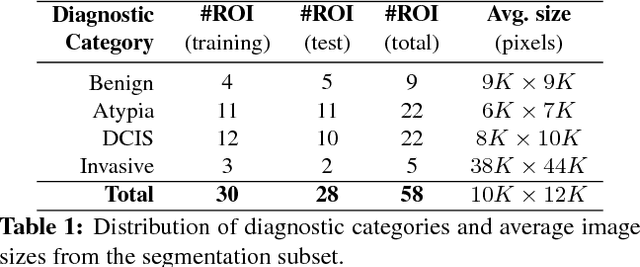
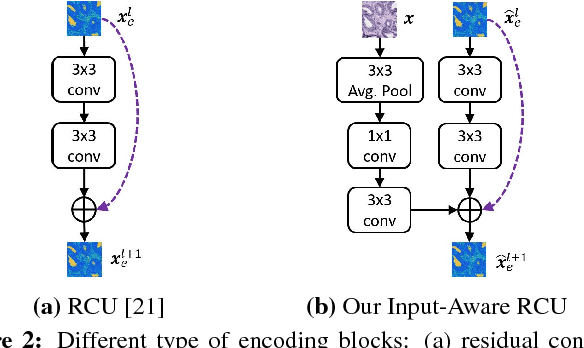
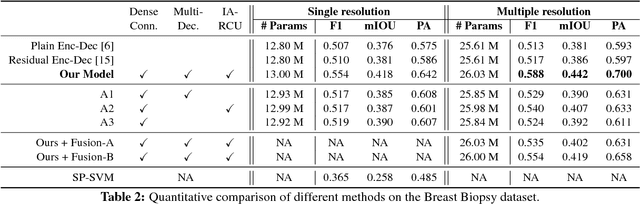
We trained and applied an encoder-decoder model to semantically segment breast biopsy images into biologically meaningful tissue labels. Since conventional encoder-decoder networks cannot be applied directly on large biopsy images and the different sized structures in biopsies present novel challenges, we propose four modifications: (1) an input-aware encoding block to compensate for information loss, (2) a new dense connection pattern between encoder and decoder, (3) dense and sparse decoders to combine multi-level features, (4) a multi-resolution network that fuses the results of encoder-decoders run on different resolutions. Our model outperforms a feature-based approach and conventional encoder-decoders from the literature. We use semantic segmentations produced with our model in an automated diagnosis task and obtain higher accuracies than a baseline approach that employs an SVM for feature-based segmentation, both using the same segmentation-based diagnostic features.