 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Deep Distribution Network for Bid Shading in First-Price Auctions
Jul 15, 2021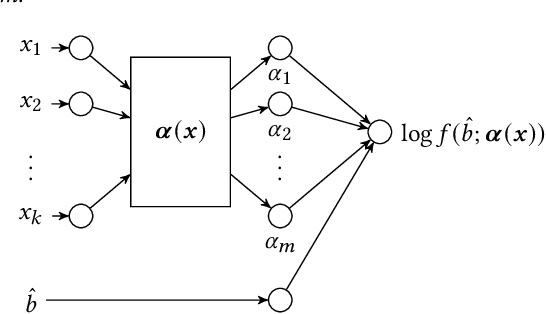
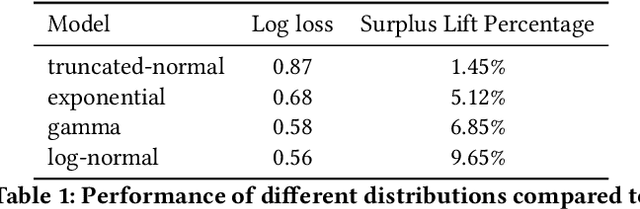
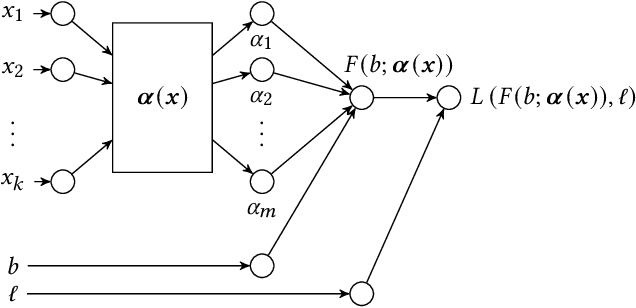
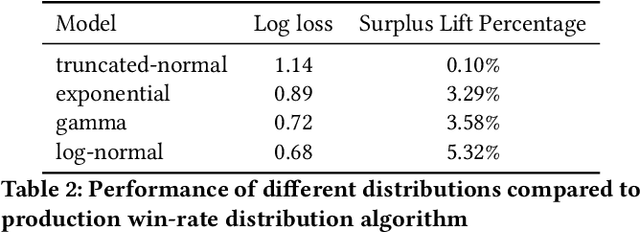
Since 2019, most ad exchanges and sell-side platforms (SSPs), in the online advertising industry, shifted from second to first price auctions. Due to the fundamental difference between these auctions, demand-side platforms (DSPs) have had to update their bidding strategies to avoid bidding unnecessarily high and hence overpaying. Bid shading was proposed to adjust the bid price intended for second-price auctions, in order to balance cost and winning probability in a first-price auction setup. In this study, we introduce a novel deep distribution network for optimal bidding in both open (non-censored) and closed (censored) online first-price auctions. Offline and online A/B testing results show that our algorithm outperforms previous state-of-art algorithms in terms of both surplus and effective cost per action (eCPX) metrics. Furthermore, the algorithm is optimized in run-time and has been deployed into VerizonMedia DSP as production algorithm, serving hundreds of billions of bid requests per day. Online A/B test shows that advertiser's ROI are improved by +2.4%, +2.4%, and +8.6% for impression based (CPM), click based (CPC), and conversion based (CPA) campaigns respectively.
Bid Shading by Win-Rate Estimation and Surplus Maximization
Sep 19, 2020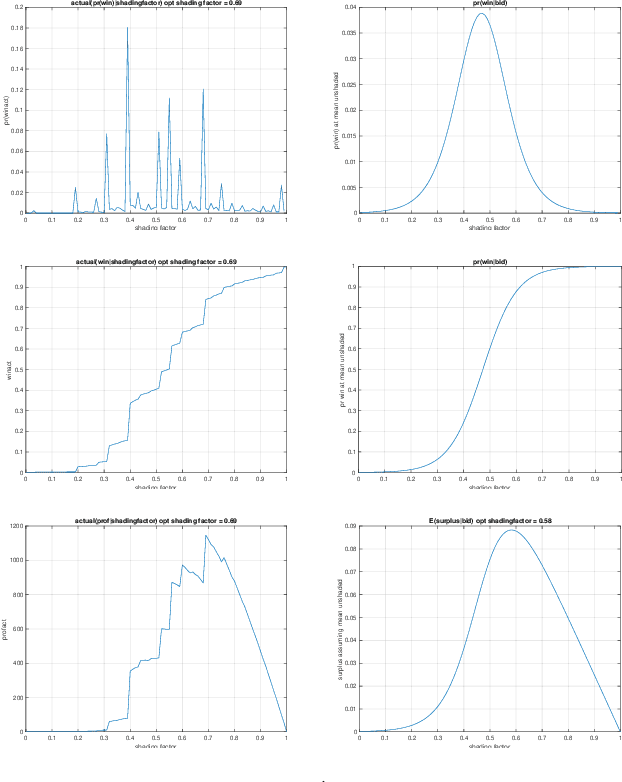
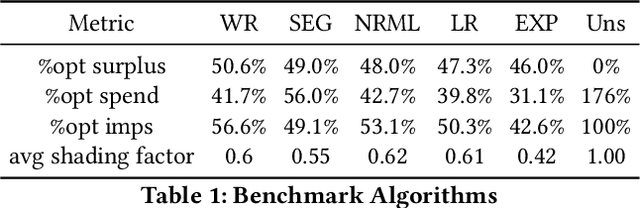
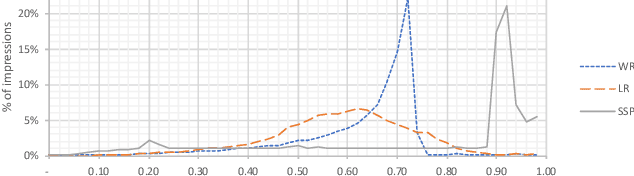
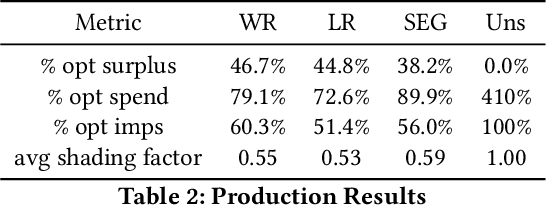
This paper describes a new win-rate based bid shading algorithm (WR) that does not rely on the minimum-bid-to-win feedback from a Sell-Side Platform (SSP). The method uses a modified logistic regression to predict the profit from each possible shaded bid price. The function form allows fast maximization at run-time, a key requirement for Real-Time Bidding (RTB) systems. We report production results from this method along with several other algorithms. We found that bid shading, in general, can deliver significant value to advertisers, reducing price per impression to about 55% of the unshaded cost. Further, the particular approach described in this paper captures 7% more profit for advertisers, than do benchmark methods of just bidding the most probable winning price. We also report 4.3% higher surplus than an industry Sell-Side Platform shading service. Furthermore, we observed 3% - 7% lower eCPM, eCPC and eCPA when the algorithm was integrated with budget controllers. We attribute the gains above as being mainly due to the explicit maximization of the surplus function, and note that other algorithms can take advantage of this same approach.
Bid Shading in The Brave New World of First-Price Auctions
Sep 02, 2020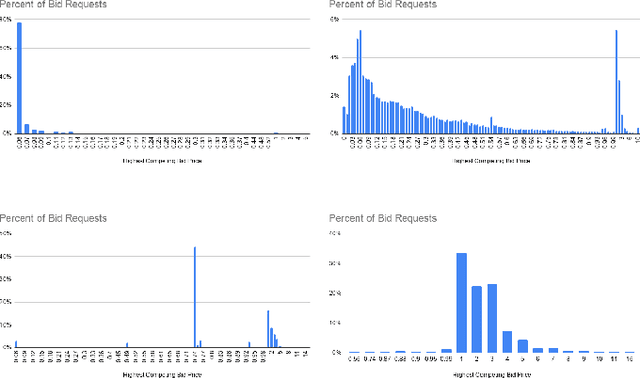

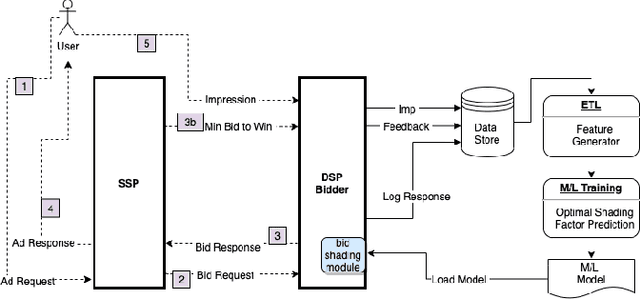
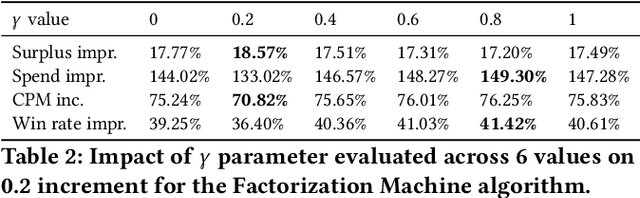
Online auctions play a central role in online advertising, and are one of the main reasons for the industry's scalability and growth. With great changes in how auctions are being organized, such as changing the second- to first-price auction type, advertisers and demand platforms are compelled to adapt to a new volatile environment. Bid shading is a known technique for preventing overpaying in auction systems that can help maintain the strategy equilibrium in first-price auctions, tackling one of its greatest drawbacks. In this study, we propose a machine learning approach of modeling optimal bid shading for non-censored online first-price ad auctions. We clearly motivate the approach and extensively evaluate it in both offline and online settings on a major demand side platform. The results demonstrate the superiority and robustness of the new approach as compared to the existing approaches across a range of performance metrics.
Time-Aware Prospective Modeling of Users for Online Display Advertising
Nov 12, 2019



Prospective display advertising poses a great challenge for large advertising platforms as the strongest predictive signals of users are not eligible to be used in the conversion prediction systems. To that end efforts are made to collect as much information as possible about each user from various data sources and to design powerful models that can capture weaker signals ultimately obtaining good quality of conversion prediction probability estimates. In this study we propose a novel time-aware approach to model heterogeneous sequences of users' activities and capture implicit signals of users' conversion intents. On two real-world datasets we show that our approach outperforms other, previously proposed approaches, while providing interpretability of signal impact to conversion probability.
Modeling Customer Engagement from Partial Observations
Mar 28, 2018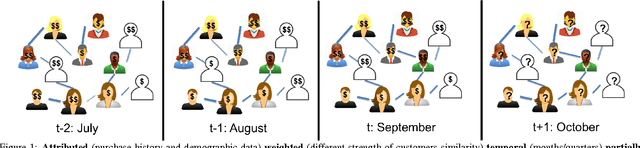
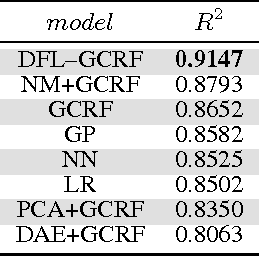
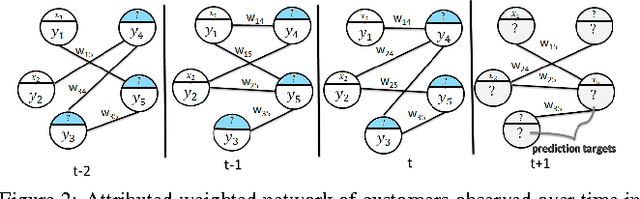
It is of high interest for a company to identify customers expected to bring the largest profit in the upcoming period. Knowing as much as possible about each customer is crucial for such predictions. However, their demographic data, preferences, and other information that might be useful for building loyalty programs is often missing. Additionally, modeling relations among different customers as a network can be beneficial for predictions at an individual level, as similar customers tend to have similar purchasing patterns. We address this problem by proposing a robust framework for structured regression on deficient data in evolving networks with a supervised representation learning based on neural features embedding. The new method is compared to several unstructured and structured alternatives for predicting customer behavior (e.g. purchasing frequency and customer ticket) on user networks generated from customer databases of two companies from different industries. The obtained results show $4\%$ to $130\%$ improvement in accuracy over alternatives when all customer information is known. Additionally, the robustness of our method is demonstrated when up to $80\%$ of demographic information was missing where it was up to several folds more accurate as compared to alternatives that are either ignoring cases with missing values or learn their feature representation in an unsupervised manner.
Semi-supervised learning for structured regression on partially observed attributed graphs
Mar 28, 2018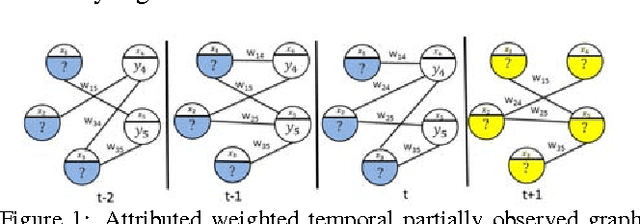
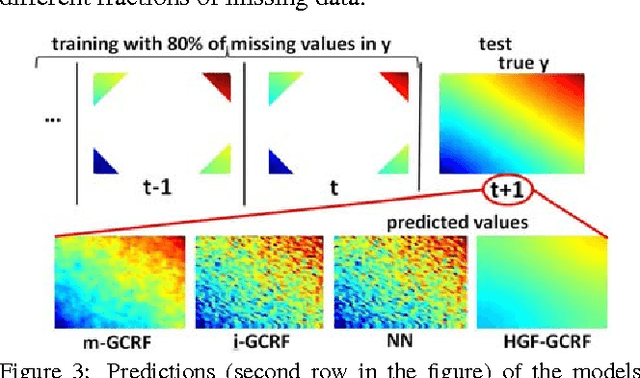
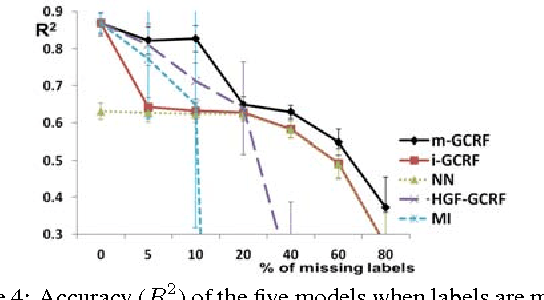
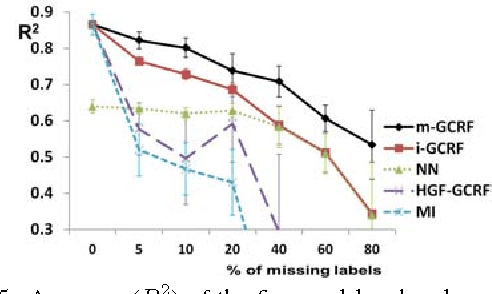
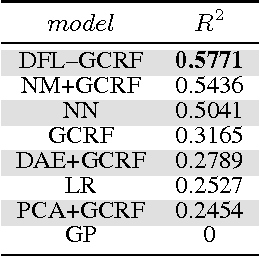
Conditional probabilistic graphical models provide a powerful framework for structured regression in spatio-temporal datasets with complex correlation patterns. However, in real-life applications a large fraction of observations is often missing, which can severely limit the representational power of these models. In this paper we propose a Marginalized Gaussian Conditional Random Fields (m-GCRF) structured regression model for dealing with missing labels in partially observed temporal attributed graphs. This method is aimed at learning with both labeled and unlabeled parts and effectively predicting future values in a graph. The method is even capable of learning from nodes for which the response variable is never observed in history, which poses problems for many state-of-the-art models that can handle missing data. The proposed model is characterized for various missingness mechanisms on 500 synthetic graphs. The benefits of the new method are also demonstrated on a challenging application for predicting precipitation based on partial observations of climate variables in a temporal graph that spans the entire continental US. We also show that the method can be useful for optimizing the costs of data collection in climate applications via active reduction of the number of weather stations to consider. In experiments on these real-world and synthetic datasets we show that the proposed model is consistently more accurate than alternative semi-supervised structured models, as well as models that either use imputation to deal with missing values or simply ignore them altogether.
Deep Attention Model for Triage of Emergency Department Patients
Mar 28, 2018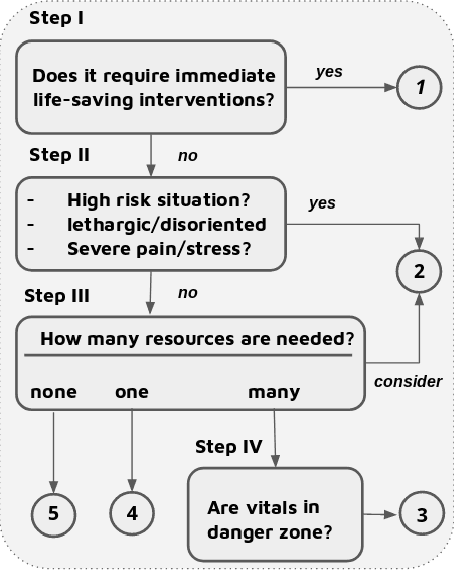
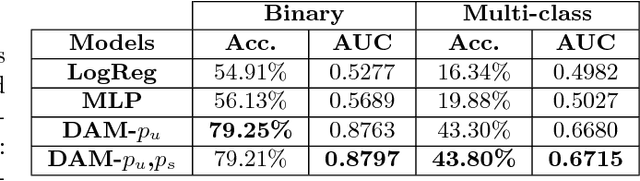
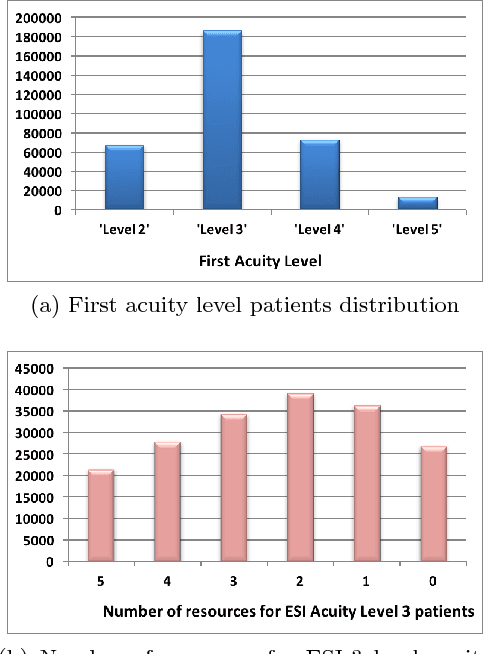
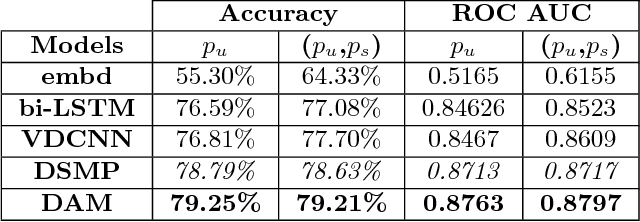
Optimization of patient throughput and wait time in emergency departments (ED) is an important task for hospital systems. For that reason, Emergency Severity Index (ESI) system for patient triage was introduced to help guide manual estimation of acuity levels, which is used by nurses to rank the patients and organize hospital resources. However, despite improvements that it brought to managing medical resources, such triage system greatly depends on nurse's subjective judgment and is thus prone to human errors. Here, we propose a novel deep model based on the word attention mechanism designed for predicting a number of resources an ED patient would need. Our approach incorporates routinely available continuous and nominal (structured) data with medical text (unstructured) data, including patient's chief complaint, past medical history, medication list, and nurse assessment collected for 338,500 ED visits over three years in a large urban hospital. Using both structured and unstructured data, the proposed approach achieves the AUC of $\sim 88\%$ for the task of identifying resource intensive patients (binary classification), and the accuracy of $\sim 44\%$ for predicting exact category of number of resources (multi-class classification task), giving an estimated lift over nurses' performance by 16\% in accuracy. Furthermore, the attention mechanism of the proposed model provides interpretability by assigning attention scores for nurses' notes which is crucial for decision making and implementation of such approaches in the real systems working on human health.
Improving confidence while predicting trends in temporal disease networks
Mar 28, 2018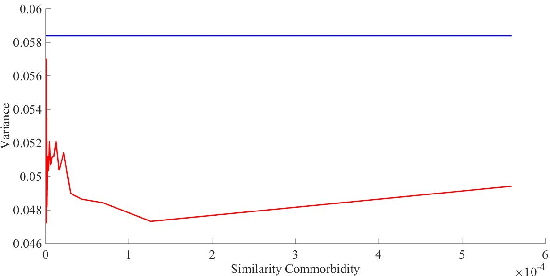
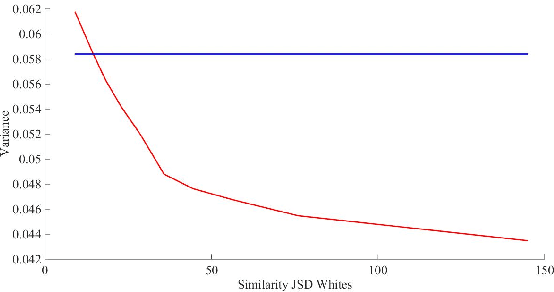
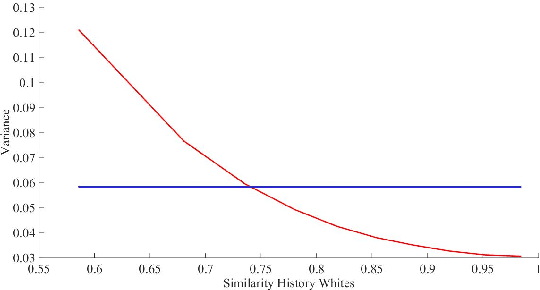
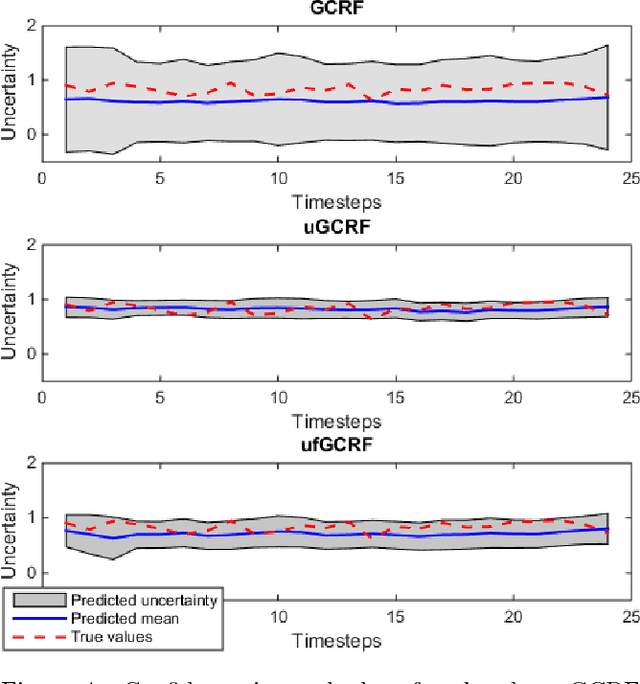
For highly sensitive real-world predictive analytic applications such as healthcare and medicine, having good prediction accuracy alone is often not enough. These kinds of applications require a decision making process which uses uncertainty estimation as input whenever possible. Quality of uncertainty estimation is a subject of over or under confident prediction, which is often not addressed in many models. In this paper we show several extensions to the Gaussian Conditional Random Fields model, which aim to provide higher quality uncertainty estimation. These extensions are applied to the temporal disease graph built from the State Inpatient Database (SID) of California, acquired from the HCUP. Our experiments demonstrate benefits of using graph information in modeling temporal disease properties as well as improvements in uncertainty estimation provided by given extensions of the Gaussian Conditional Random Fields method.