 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Depth Estimation in Laparoscopic Image using 3D Geometric Consistency
Aug 17, 2022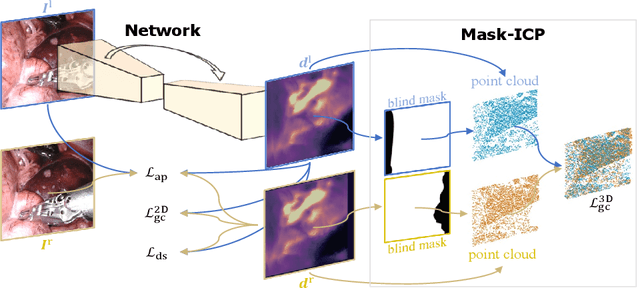
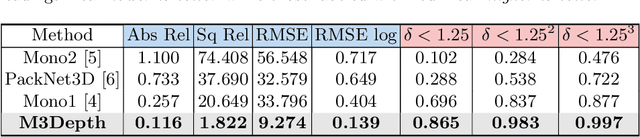
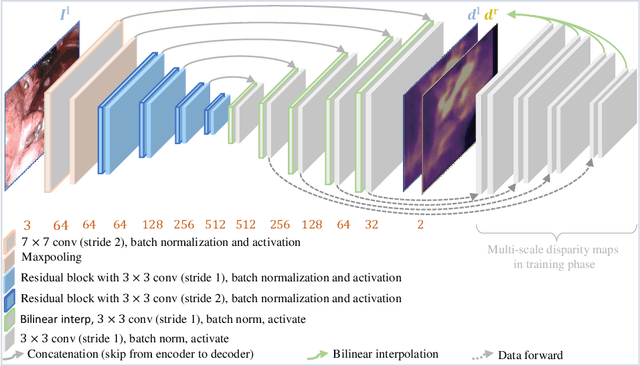

Depth estimation is a crucial step for image-guided intervention in robotic surgery and laparoscopic imaging system. Since per-pixel depth ground truth is difficult to acquire for laparoscopic image data, it is rarely possible to apply supervised depth estimation to surgical applications. As an alternative, self-supervised methods have been introduced to train depth estimators using only synchronized stereo image pairs. However, most recent work focused on the left-right consistency in 2D and ignored valuable inherent 3D information on the object in real world coordinates, meaning that the left-right 3D geometric structural consistency is not fully utilized. To overcome this limitation, we present M3Depth, a self-supervised depth estimator to leverage 3D geometric structural information hidden in stereo pairs while keeping monocular inference. The method also removes the influence of border regions unseen in at least one of the stereo images via masking, to enhance the correspondences between left and right images in overlapping areas. Intensive experiments show that our method outperforms previous self-supervised approaches on both a public dataset and a newly acquired dataset by a large margin, indicating a good generalization across different samples and laparoscopes.
Self-Supervised Generative Adversarial Network for Depth Estimation in Laparoscopic Images
Jul 09, 2021
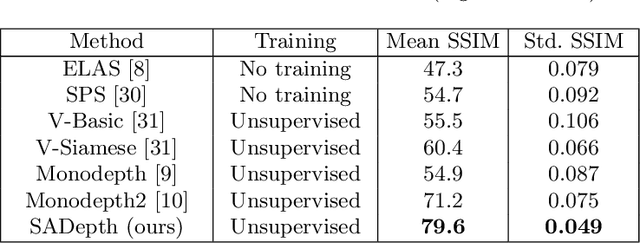
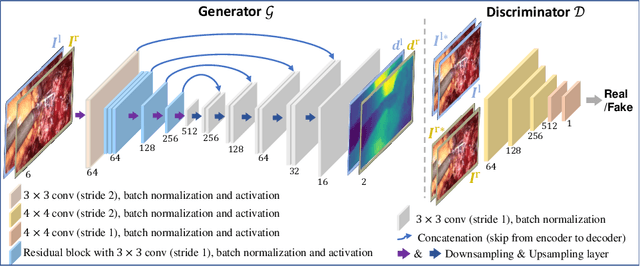
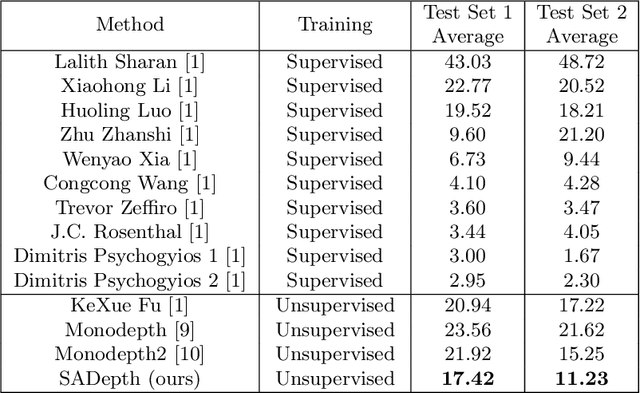
Dense depth estimation and 3D reconstruction of a surgical scene are crucial steps in computer assisted surgery. Recent work has shown that depth estimation from a stereo images pair could be solved with convolutional neural networks. However, most recent depth estimation models were trained on datasets with per-pixel ground truth. Such data is especially rare for laparoscopic imaging, making it hard to apply supervised depth estimation to real surgical applications. To overcome this limitation, we propose SADepth, a new self-supervised depth estimation method based on Generative Adversarial Networks. It consists of an encoder-decoder generator and a discriminator to incorporate geometry constraints during training. Multi-scale outputs from the generator help to solve the local minima caused by the photometric reprojection loss, while the adversarial learning improves the framework generation quality. Extensive experiments on two public datasets show that SADepth outperforms recent state-of-the-art unsupervised methods by a large margin, and reduces the gap between supervised and unsupervised depth estimation in laparoscopic images.