 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Networks as Paths through the Space of Representations
Jun 22, 2022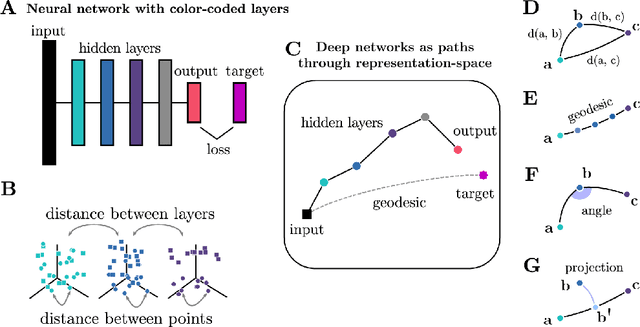
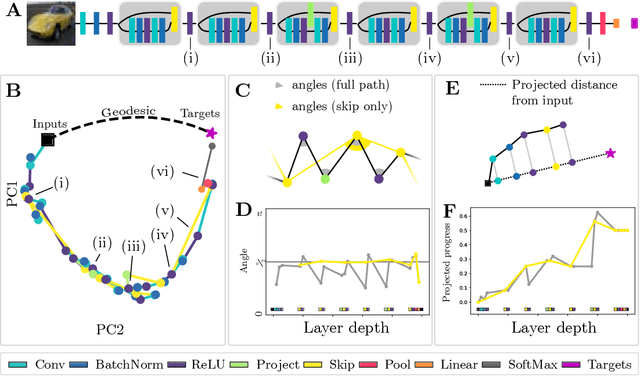
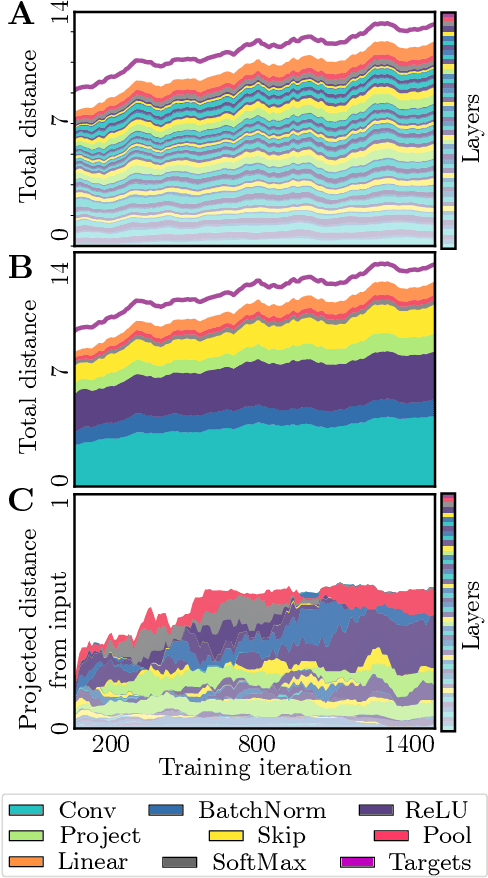
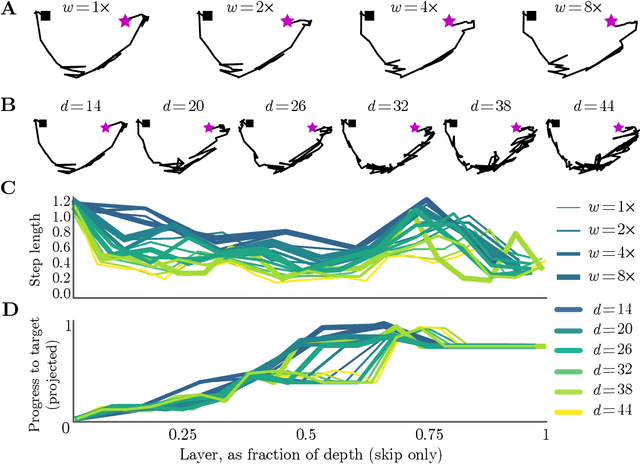
Deep neural networks implement a sequence of layer-by-layer operations that are each relatively easy to understand, but the resulting overall computation is generally difficult to understand. We develop a simple idea for interpreting the layer-by-layer construction of useful representations: the role of each layer is to reformat information to reduce the "distance" to the target outputs. We formalize this intuitive idea of "distance" by leveraging recent work on metric representational similarity, and show how it leads to a rich space of geometric concepts. With this framework, the layer-wise computation implemented by a deep neural network can be viewed as a path in a high-dimensional representation space. We develop tools to characterize the geometry of these in terms of distances, angles, and geodesics. We then ask three sets of questions of residual networks trained on CIFAR-10: (1) how straight are paths, and how does each layer contribute towards the target? (2) how do these properties emerge over training? and (3) how similar are the paths taken by wider versus deeper networks? We conclude by sketching additional ways that this kind of representational geometry can be used to understand and interpret network training, or to prescriptively improve network architectures to suit a task.
Clustering units in neural networks: upstream vs downstream information
Mar 22, 2022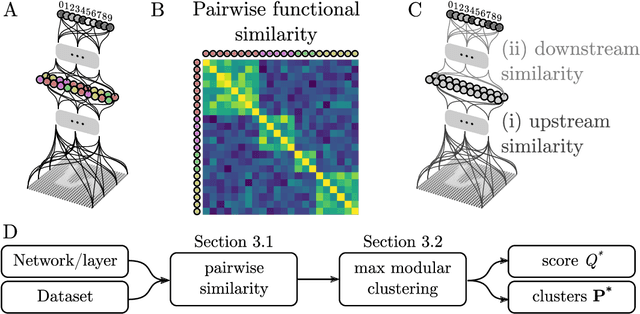
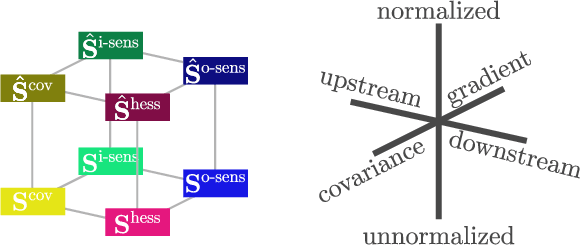
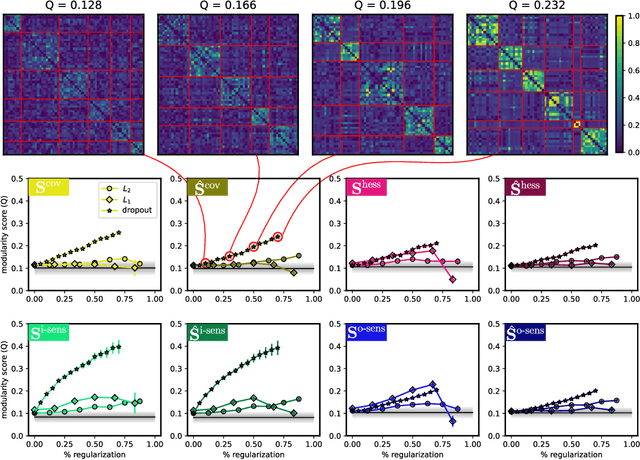
It has been hypothesized that some form of "modular" structure in artificial neural networks should be useful for learning, compositionality, and generalization. However, defining and quantifying modularity remains an open problem. We cast the problem of detecting functional modules into the problem of detecting clusters of similar-functioning units. This begs the question of what makes two units functionally similar. For this, we consider two broad families of methods: those that define similarity based on how units respond to structured variations in inputs ("upstream"), and those based on how variations in hidden unit activations affect outputs ("downstream"). We conduct an empirical study quantifying modularity of hidden layer representations of simple feedforward, fully connected networks, across a range of hyperparameters. For each model, we quantify pairwise associations between hidden units in each layer using a variety of both upstream and downstream measures, then cluster them by maximizing their "modularity score" using established tools from network science. We find two surprising results: first, dropout dramatically increased modularity, while other forms of weight regularization had more modest effects. Second, although we observe that there is usually good agreement about clusters within both upstream methods and downstream methods, there is little agreement about the cluster assignments across these two families of methods. This has important implications for representation-learning, as it suggests that finding modular representations that reflect structure in inputs (e.g. disentanglement) may be a distinct goal from learning modular representations that reflect structure in outputs (e.g. compositionality).