 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Models for Unified Collaborative and Content-Based Recommendation in Sparse-Data Environments
Jan 10, 2013

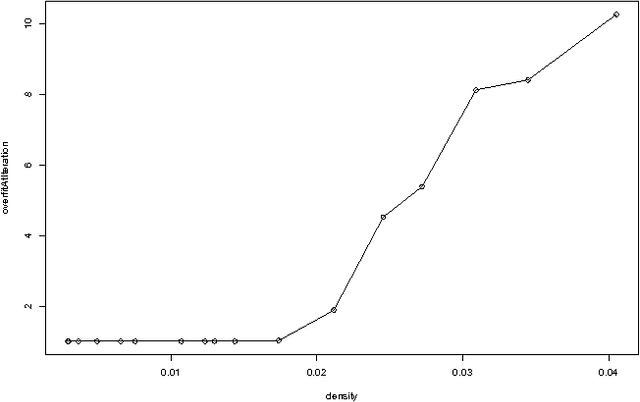

Recommender systems leverage product and community information to target products to consumers. Researchers have developed collaborative recommenders, content-based recommenders, and (largely ad-hoc) hybrid systems. We propose a unified probabilistic framework for merging collaborative and content-based recommendations. We extend Hofmann's [1999] aspect model to incorporate three-way co-occurrence data among users, items, and item content. The relative influence of collaboration data versus content data is not imposed as an exogenous parameter, but rather emerges naturally from the given data sources. Global probabilistic models coupled with standard Expectation Maximization (EM) learning algorithms tend to drastically overfit in sparse-data situations, as is typical in recommendation applications. We show that secondary content information can often be used to overcome sparsity. Experiments on data from the ResearchIndex library of Computer Science publications show that appropriate mixture models incorporating secondary data produce significantly better quality recommenders than k-nearest neighbors (k-NN). Global probabilistic models also allow more general inferences than local methods like k-NN.
Modelling Information Incorporation in Markets, with Application to Detecting and Explaining Events
Dec 12, 2012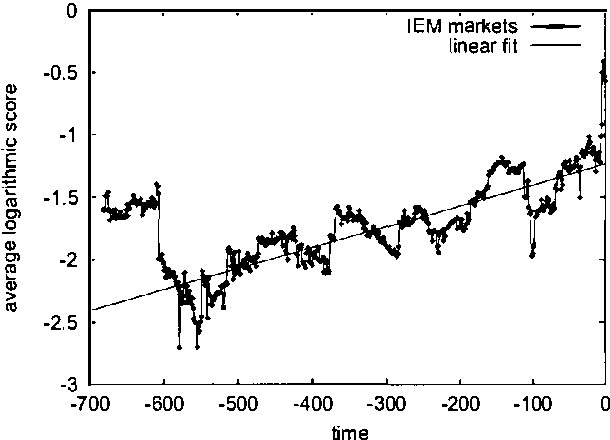
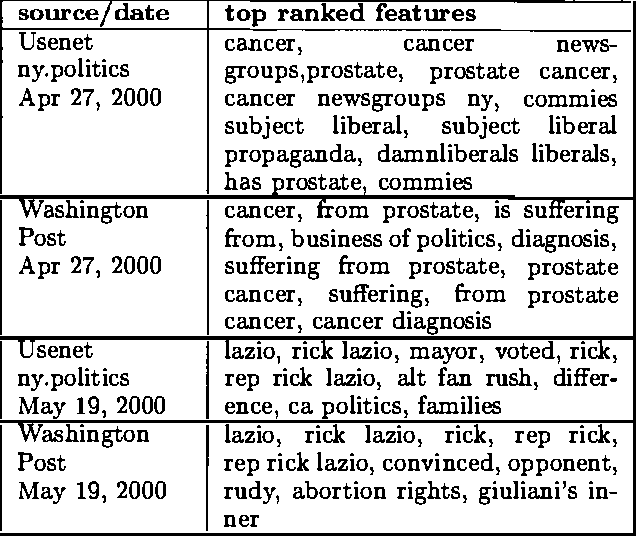
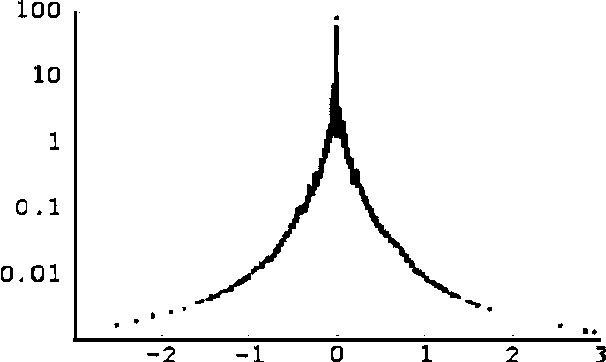

We develop a model of how information flows into a market, and derive algorithms for automatically detecting and explaining relevant events. We analyze data from twenty-two "political stock markets" (i.e., betting markets on political outcomes) on the Iowa Electronic Market (IEM). We prove that, under certain efficiency assumptions, prices in such betting markets will on average approach the correct outcomes over time, and show that IEM data conforms closely to the theory. We present a simple model of a betting market where information is revealed over time, and show a qualitative correspondence between the model and real market data. We also present an algorithm for automatically detecting significant events and generating semantic explanations of their origin. The algorithm operates by discovering significant changes in vocabulary on online news sources (using expected entropy loss) that align with major price spikes in related betting markets.
1 Billion Pages = 1 Million Dollars? Mining the Web to Play "Who Wants to be a Millionaire?"
Oct 19, 2012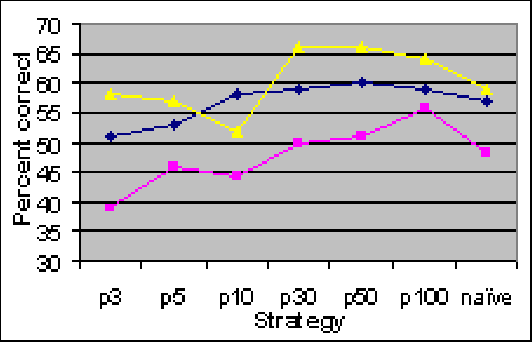
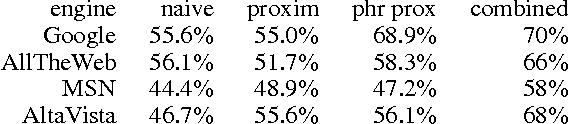
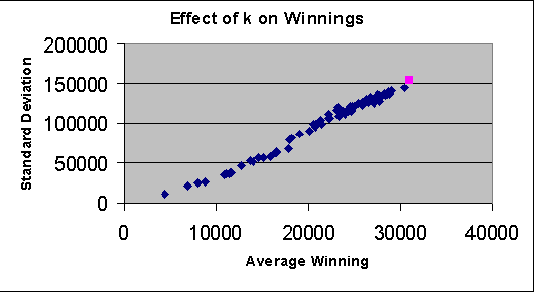
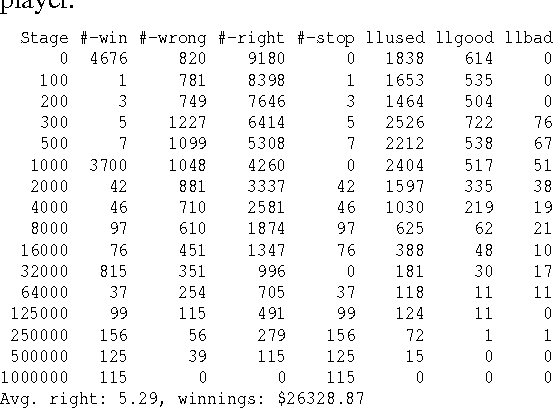
We exploit the redundancy and volume of information on the web to build a computerized player for the ABC TV game show 'Who Wants To Be A Millionaire?' The player consists of a question-answering module and a decision-making module. The question-answering module utilizes question transformation techniques, natural language parsing, multiple information retrieval algorithms, and multiple search engines; results are combined in the spirit of ensemble learning using an adaptive weighting scheme. Empirically, the system correctly answers about 75% of questions from the Millionaire CD-ROM, 3rd edition - general-interest trivia questions often about popular culture and common knowledge. The decision-making module chooses from allowable actions in the game in order to maximize expected risk-adjusted winnings, where the estimated probability of answering correctly is a function of past performance and confidence in in correctly answering the current question. When given a six question head start (i.e., when starting from the $2,000 level), we find that the system performs about as well on average as humans starting at the beginning. Our system demonstrates the potential of simple but well-chosen techniques for mining answers from unstructured information such as the web.
An Empirical Comparison of Algorithms for Aggregating Expert Predictions
Jun 27, 2012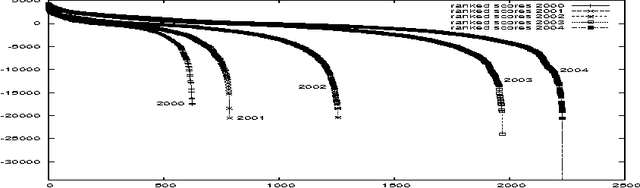
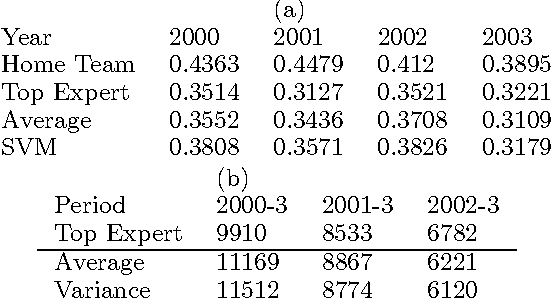
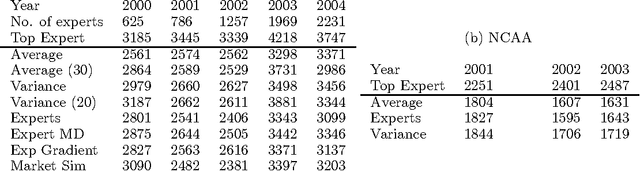
Predicting the outcomes of future events is a challenging problem for which a variety of solution methods have been explored and attempted. We present an empirical comparison of a variety of online and offline adaptive algorithms for aggregating experts' predictions of the outcomes of five years of US National Football League games (1319 games) using expert probability elicitations obtained from an Internet contest called ProbabilitySports. We find that it is difficult to improve over simple averaging of the predictions in terms of prediction accuracy, but that there is room for improvement in quadratic loss. Somewhat surprisingly, a Bayesian estimation algorithm which estimates the variance of each expert's prediction exhibits the most consistent superior performance over simple averaging among our collection of algorithms.