 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Alternative Name Spellings
May 07, 2014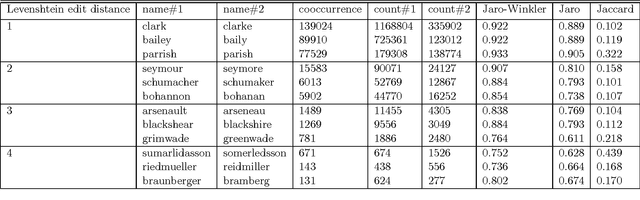
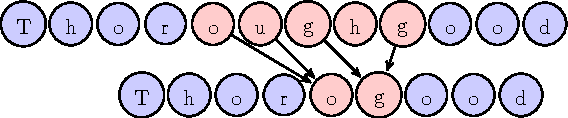

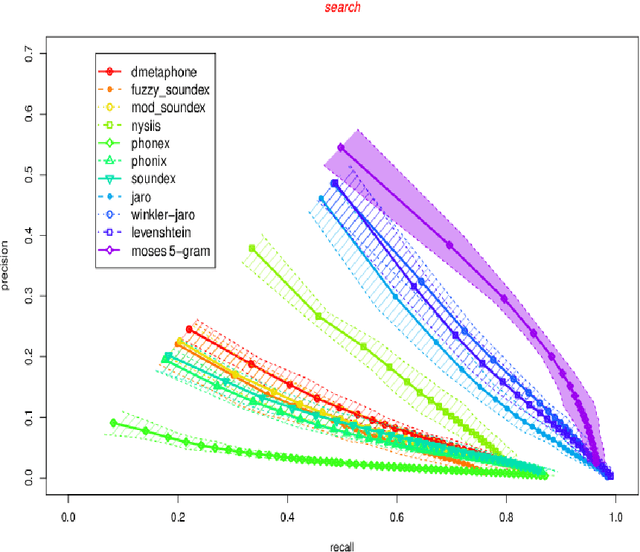
Name matching is a key component of systems for entity resolution or record linkage. Alternative spellings of the same names are a com- mon occurrence in many applications. We use the largest collection of genealogy person records in the world together with user search query logs to build name matching models. The procedure for building a crowd-sourced training set is outlined together with the presentation of our method. We cast the problem of learning alternative spellings as a machine translation problem at the character level. We use in- formation retrieval evaluation methodology to show that this method substantially outperforms on our data a number of standard well known phonetic and string similarity methods in terms of precision and re- call. Additionally, we rigorously compare the performance of standard methods when compared with each other. Our result can lead to a significant practical impact in entity resolution applications.
Probabilistic Models for Unified Collaborative and Content-Based Recommendation in Sparse-Data Environments
Jan 10, 2013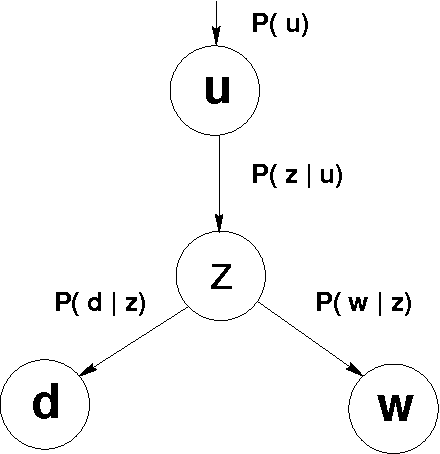


Recommender systems leverage product and community information to target products to consumers. Researchers have developed collaborative recommenders, content-based recommenders, and (largely ad-hoc) hybrid systems. We propose a unified probabilistic framework for merging collaborative and content-based recommendations. We extend Hofmann's [1999] aspect model to incorporate three-way co-occurrence data among users, items, and item content. The relative influence of collaboration data versus content data is not imposed as an exogenous parameter, but rather emerges naturally from the given data sources. Global probabilistic models coupled with standard Expectation Maximization (EM) learning algorithms tend to drastically overfit in sparse-data situations, as is typical in recommendation applications. We show that secondary content information can often be used to overcome sparsity. Experiments on data from the ResearchIndex library of Computer Science publications show that appropriate mixture models incorporating secondary data produce significantly better quality recommenders than k-nearest neighbors (k-NN). Global probabilistic models also allow more general inferences than local methods like k-NN.