 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphological Inflection with Phonological Features
Jun 21, 2023



Recent years have brought great advances into solving morphological tasks, mostly due to powerful neural models applied to various tasks as (re)inflection and analysis. Yet, such morphological tasks cannot be considered solved, especially when little training data is available or when generalizing to previously unseen lemmas. This work explores effects on performance obtained through various ways in which morphological models get access to subcharacter phonological features that are the targets of morphological processes. We design two methods to achieve this goal: one that leaves models as is but manipulates the data to include features instead of characters, and another that manipulates models to take phonological features into account when building representations for phonemes. We elicit phonemic data from standard graphemic data using language-specific grammars for languages with shallow grapheme-to-phoneme mapping, and we experiment with two reinflection models over eight languages. Our results show that our methods yield comparable results to the grapheme-based baseline overall, with minor improvements in some of the languages. All in all, we conclude that patterns in character distributions are likely to allow models to infer the underlying phonological characteristics, even when phonemes are not explicitly represented.
UniMorph 4.0: Universal Morphology
May 10, 2022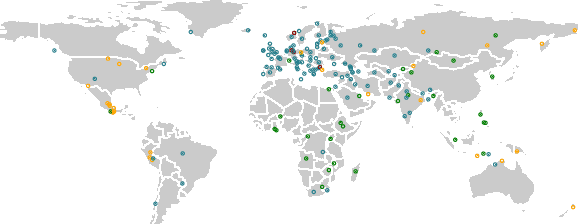

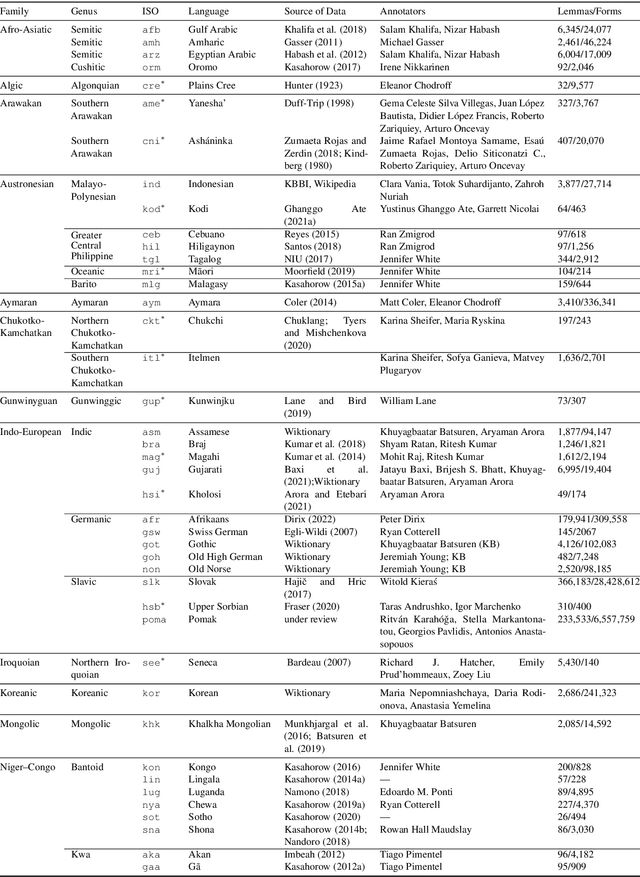
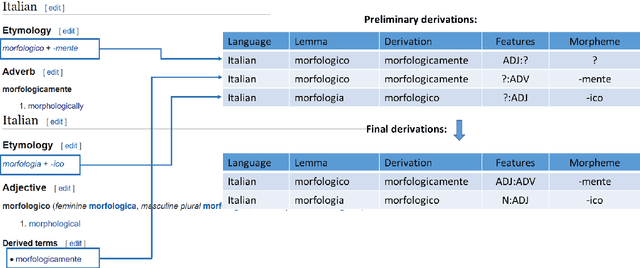
The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Morphological Reinflection with Multiple Arguments: An Extended Annotation schema and a Georgian Case Study
Mar 20, 2022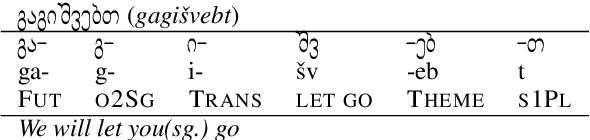
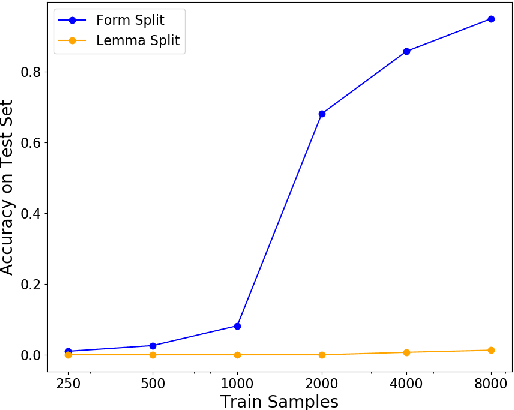
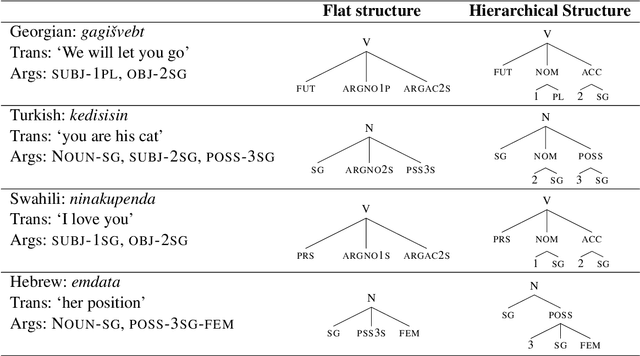

In recent years, a flurry of morphological datasets had emerged, most notably UniMorph, a multi-lingual repository of inflection tables. However, the flat structure of the current morphological annotation schema makes the treatment of some languages quirky, if not impossible, specifically in cases of polypersonal agreement, where verbs agree with multiple arguments using true affixes. In this paper, we propose to address this phenomenon by expanding the UniMorph annotation schema to a hierarchical feature structure that naturally accommodates complex argument marking. We apply this extended schema to one such language, Georgian, and provide a human-verified, accurate and balanced morphological dataset for Georgian verbs. The dataset has 4 times more tables and 6 times more verb forms compared to the existing UniMorph dataset, covering all possible variants of argument marking, demonstrating the adequacy of our proposed scheme. Experiments with a standard reinflection model show that generalization is easy when the data is split at the form level, but extremely hard when splitting along lemma lines. Expanding the other languages in UniMorph to this schema is expected to improve both the coverage, consistency and interpretability of this benchmark.
(Un)solving Morphological Inflection: Lemma Overlap Artificially Inflates Models' Performance
Aug 12, 2021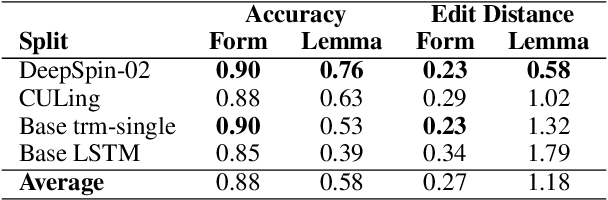
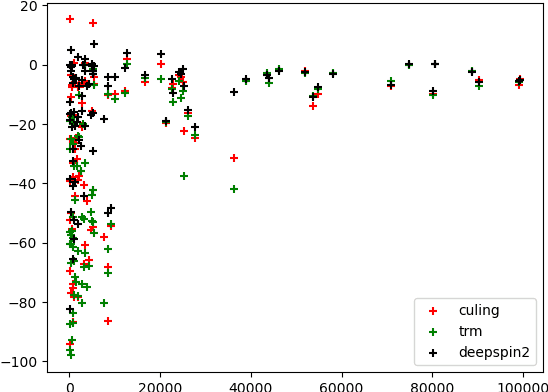
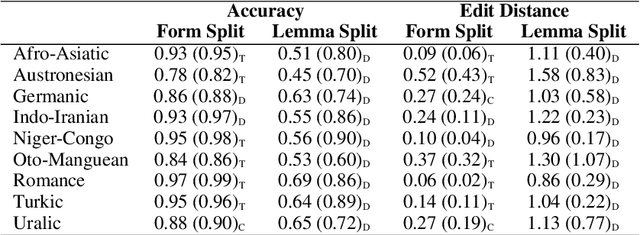
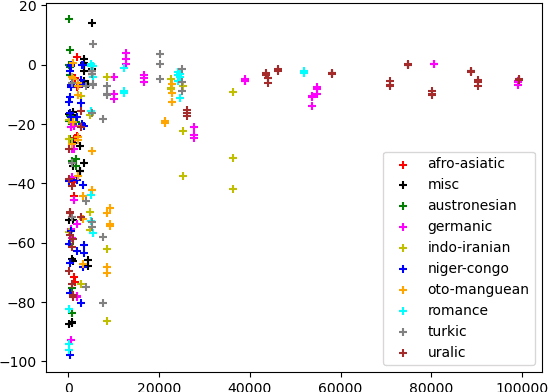
In the domain of Morphology, Inflection is a fundamental and important task that gained a lot of traction in recent years, mostly via SIGMORPHON's shared-tasks. With average accuracy above 0.9 over the scores of all languages, the task is considered mostly solved using relatively generic neural sequence-to-sequence models, even with little data provided. In this work, we propose to re-evaluate morphological inflection models by employing harder train-test splits that will challenge the generalization capacity of the models. In particular, as opposed to the na\"ive split-by-form, we propose a split-by-lemma method to challenge the performance on existing benchmarks. Our experiments with the three top-ranked systems on the SIGMORPHON's 2020 shared-task show that the lemma-split presents an average drop of 30 percentage points in macro-average for the 90 languages included. The effect is most significant for low-resourced languages with a drop as high as 95 points, but even high-resourced languages lose about 10 points on average. Our results clearly show that generalizing inflection to unseen lemmas is far from being solved, presenting a simple yet effective means to promote more sophisticated models.