 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphological Reinflection with Multiple Arguments: An Extended Annotation schema and a Georgian Case Study
Paper and Code
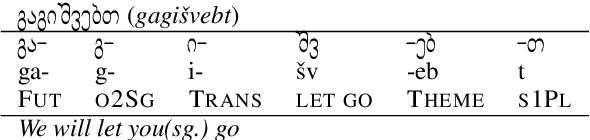
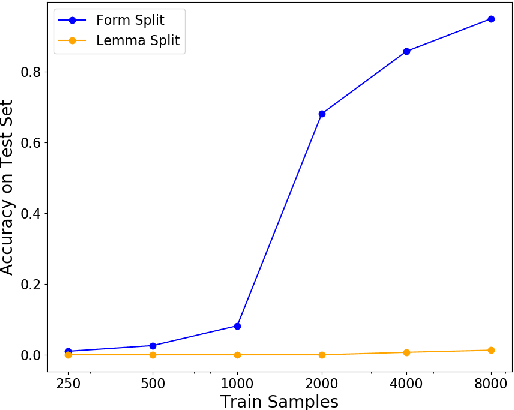
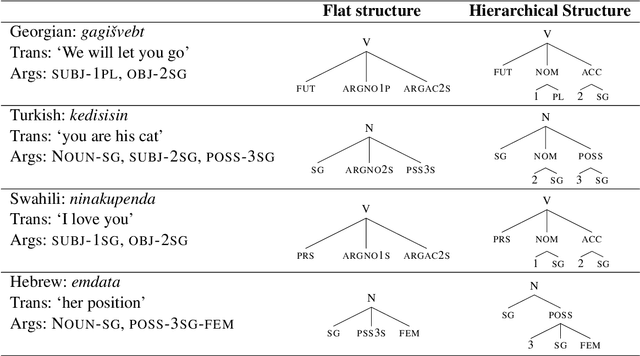

In recent years, a flurry of morphological datasets had emerged, most notably UniMorph, a multi-lingual repository of inflection tables. However, the flat structure of the current morphological annotation schema makes the treatment of some languages quirky, if not impossible, specifically in cases of polypersonal agreement, where verbs agree with multiple arguments using true affixes. In this paper, we propose to address this phenomenon by expanding the UniMorph annotation schema to a hierarchical feature structure that naturally accommodates complex argument marking. We apply this extended schema to one such language, Georgian, and provide a human-verified, accurate and balanced morphological dataset for Georgian verbs. The dataset has 4 times more tables and 6 times more verb forms compared to the existing UniMorph dataset, covering all possible variants of argument marking, demonstrating the adequacy of our proposed scheme. Experiments with a standard reinflection model show that generalization is easy when the data is split at the form level, but extremely hard when splitting along lemma lines. Expanding the other languages in UniMorph to this schema is expected to improve both the coverage, consistency and interpretability of this benchmark.