 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbounded Differentially Private Quantile and Maximum Estimation
May 02, 2023In this work we consider the problem of differentially private computation of quantiles for the data, especially the highest quantiles such as maximum, but with an unbounded range for the dataset. We show that this can be done efficiently through a simple invocation of $\texttt{AboveThreshold}$, a subroutine that is iteratively called in the fundamental Sparse Vector Technique, even when there is no upper bound on the data. In particular, we show that this procedure can give more accurate and robust estimates on the highest quantiles with applications towards clipping that is essential for differentially private sum and mean estimation. In addition, we show how two invocations can handle the fully unbounded data setting. Within our study, we show that an improved analysis of $\texttt{AboveThreshold}$ can improve the privacy guarantees for the widely used Sparse Vector Technique that is of independent interest. We give a more general characterization of privacy loss for $\texttt{AboveThreshold}$ which we immediately apply to our method for improved privacy guarantees. Our algorithm only requires one $O(n)$ pass through the data, which can be unsorted, and each subsequent query takes $O(1)$ time. We empirically compare our unbounded algorithm with the state-of-the-art algorithms in the bounded setting. For inner quantiles, we find that our method often performs better on non-synthetic datasets. For the maximal quantiles, which we apply to differentially private sum computation, we find that our method performs significantly better.
mSAM: Micro-Batch-Averaged Sharpness-Aware Minimization
Feb 19, 2023
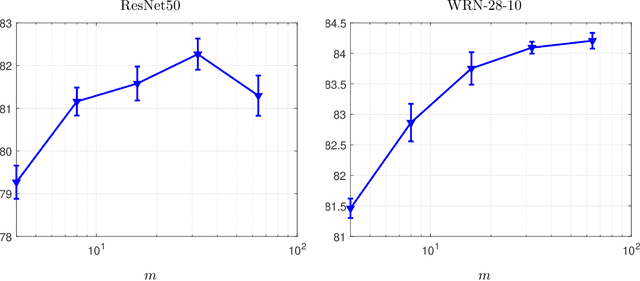
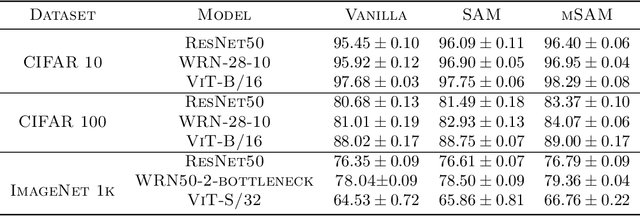

Modern deep learning models are over-parameterized, where different optima can result in widely varying generalization performance. To account for this, Sharpness-Aware Minimization (SAM) modifies the underlying loss function to guide descent methods towards flatter minima, which arguably have better generalization abilities. In this paper, we focus on a variant of SAM known as micro-batch SAM (mSAM), which, during training, averages the updates generated by adversarial perturbations across several disjoint shards (micro batches) of a mini-batch. We extend a recently developed and well-studied general framework for flatness analysis to show that distributed gradient computation for sharpness-aware minimization theoretically achieves even flatter minima. In order to support this theoretical superiority, we provide a thorough empirical evaluation on a variety of image classification and natural language processing tasks. We also show that contrary to previous work, mSAM can be implemented in a flexible and parallelizable manner without significantly increasing computational costs. Our practical implementation of mSAM yields superior generalization performance across a wide range of tasks compared to SAM, further supporting our theoretical framework.
Improved Deep Neural Network Generalization Using m-Sharpness-Aware Minimization
Dec 07, 2022
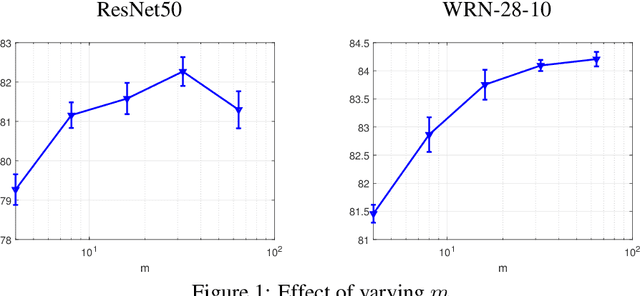
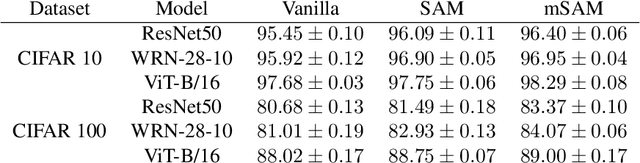

Modern deep learning models are over-parameterized, where the optimization setup strongly affects the generalization performance. A key element of reliable optimization for these systems is the modification of the loss function. Sharpness-Aware Minimization (SAM) modifies the underlying loss function to guide descent methods towards flatter minima, which arguably have better generalization abilities. In this paper, we focus on a variant of SAM known as mSAM, which, during training, averages the updates generated by adversarial perturbations across several disjoint shards of a mini-batch. Recent work suggests that mSAM can outperform SAM in terms of test accuracy. However, a comprehensive empirical study of mSAM is missing from the literature -- previous results have mostly been limited to specific architectures and datasets. To that end, this paper presents a thorough empirical evaluation of mSAM on various tasks and datasets. We provide a flexible implementation of mSAM and compare the generalization performance of mSAM to the performance of SAM and vanilla training on different image classification and natural language processing tasks. We also conduct careful experiments to understand the computational cost of training with mSAM, its sensitivity to hyperparameters and its correlation with the flatness of the loss landscape. Our analysis reveals that mSAM yields superior generalization performance and flatter minima, compared to SAM, across a wide range of tasks without significantly increasing computational costs.
Heterogeneous Calibration: A post-hoc model-agnostic framework for improved generalization
Feb 10, 2022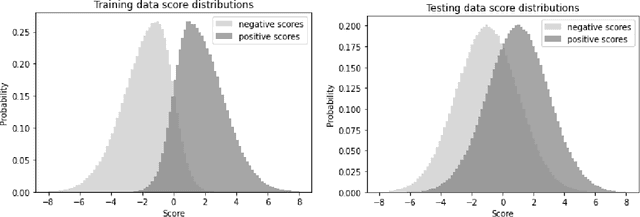



We introduce the notion of heterogeneous calibration that applies a post-hoc model-agnostic transformation to model outputs for improving AUC performance on binary classification tasks. We consider overconfident models, whose performance is significantly better on training vs test data and give intuition onto why they might under-utilize moderately effective simple patterns in the data. We refer to these simple patterns as heterogeneous partitions of the feature space and show theoretically that perfectly calibrating each partition separately optimizes AUC. This gives a general paradigm of heterogeneous calibration as a post-hoc procedure by which heterogeneous partitions of the feature space are identified through tree-based algorithms and post-hoc calibration techniques are applied to each partition to improve AUC. While the theoretical optimality of this framework holds for any model, we focus on deep neural networks (DNNs) and test the simplest instantiation of this paradigm on a variety of open-source datasets. Experiments demonstrate the effectiveness of this framework and the future potential for applying higher-performing partitioning schemes along with more effective calibration techniques.
Efficient Second-Order Shape-Constrained Function Fitting
May 28, 2019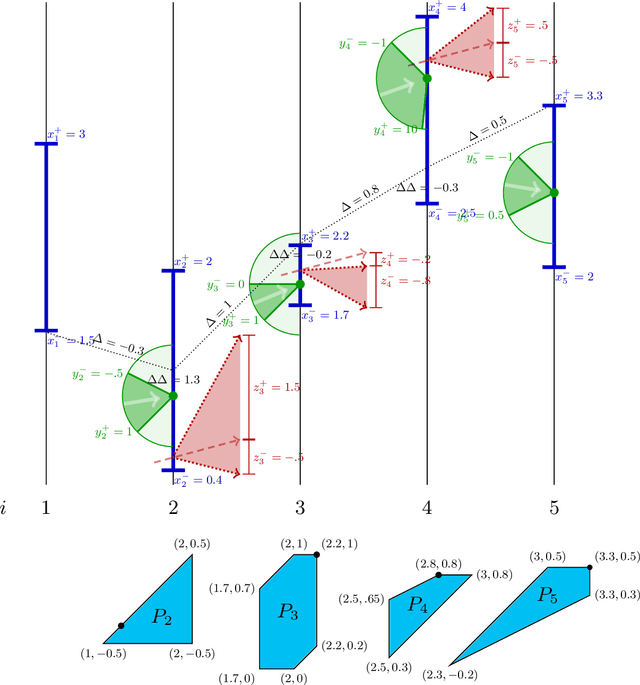
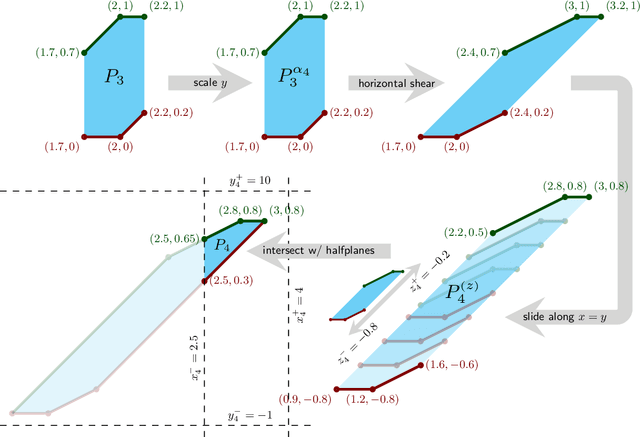
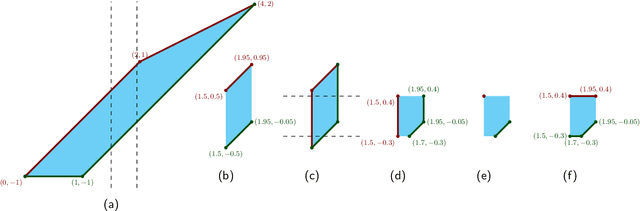
We give an algorithm to compute a one-dimensional shape-constrained function that best fits given data in weighted-$L_{\infty}$ norm. We give a single algorithm that works for a variety of commonly studied shape constraints including monotonicity, Lipschitz-continuity and convexity, and more generally, any shape constraint expressible by bounds on first- and/or second-order differences. Our algorithm computes an approximation with additive error $\varepsilon$ in $O\left(n \log \frac{U}{\varepsilon} \right)$ time, where $U$ captures the range of input values. We also give a simple greedy algorithm that runs in $O(n)$ time for the special case of unweighted $L_{\infty}$ convex regression. These are the first (near-)linear-time algorithms for second-order-constrained function fitting. To achieve these results, we use a novel geometric interpretation of the underlying dynamic programming problem. We further show that a generalization of the corresponding problems to directed acyclic graphs (DAGs) is as difficult as linear programming.