 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemSAM: Micro-Batch-Averaged Sharpness-Aware Minimization
Paper and Code
Feb 19, 2023
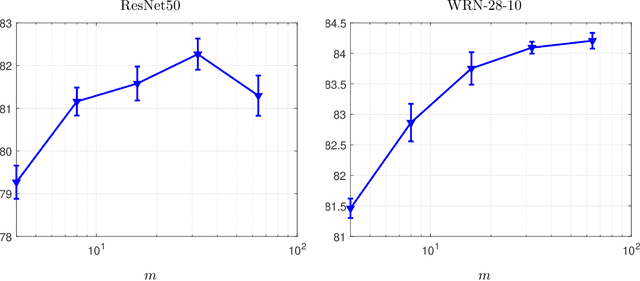
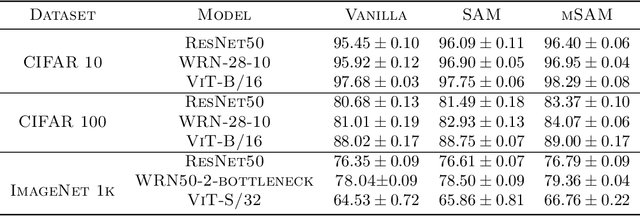

Modern deep learning models are over-parameterized, where different optima can result in widely varying generalization performance. To account for this, Sharpness-Aware Minimization (SAM) modifies the underlying loss function to guide descent methods towards flatter minima, which arguably have better generalization abilities. In this paper, we focus on a variant of SAM known as micro-batch SAM (mSAM), which, during training, averages the updates generated by adversarial perturbations across several disjoint shards (micro batches) of a mini-batch. We extend a recently developed and well-studied general framework for flatness analysis to show that distributed gradient computation for sharpness-aware minimization theoretically achieves even flatter minima. In order to support this theoretical superiority, we provide a thorough empirical evaluation on a variety of image classification and natural language processing tasks. We also show that contrary to previous work, mSAM can be implemented in a flexible and parallelizable manner without significantly increasing computational costs. Our practical implementation of mSAM yields superior generalization performance across a wide range of tasks compared to SAM, further supporting our theoretical framework.