 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Value of PHH3 for Mitotic Figure Detection on H&E-stained Images
Jun 28, 2024The count of mitotic figures (MFs) observed in hematoxylin and eosin (H&E)-stained slides is an important prognostic marker as it is a measure for tumor cell proliferation. However, the identification of MFs has a known low inter-rater agreement. Deep learning algorithms can standardize this task, but they require large amounts of annotated data for training and validation. Furthermore, label noise introduced during the annotation process may impede the algorithm's performance. Unlike H&E, the mitosis-specific antibody phospho-histone H3 (PHH3) specifically highlights MFs. Counting MFs on slides stained against PHH3 leads to higher agreement among raters and has therefore recently been used as a ground truth for the annotation of MFs in H&E. However, as PHH3 facilitates the recognition of cells indistinguishable from H&E stain alone, the use of this ground truth could potentially introduce noise into the H&E-related dataset, impacting model performance. This study analyzes the impact of PHH3-assisted MF annotation on inter-rater reliability and object level agreement through an extensive multi-rater experiment. We found that the annotators' object-level agreement increased when using PHH3-assisted labeling. Subsequently, MF detectors were evaluated on the resulting datasets to investigate the influence of PHH3-assisted labeling on the models' performance. Additionally, a novel dual-stain MF detector was developed to investigate the interpretation-shift of PHH3-assisted labels used in H&E, which clearly outperformed single-stain detectors. However, the PHH3-assisted labels did not have a positive effect on solely H&E-based models. The high performance of our dual-input detector reveals an information mismatch between the H&E and PHH3-stained images as the cause of this effect.
How Many Annotators Do We Need? -- A Study on the Influence of Inter-Observer Variability on the Reliability of Automatic Mitotic Figure Assessment
Jan 08, 2021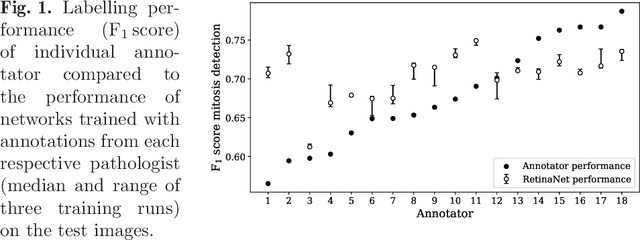
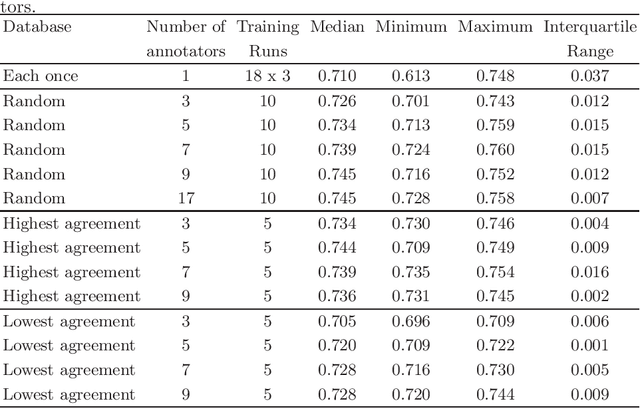
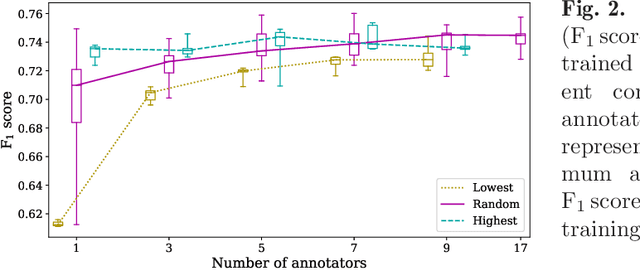
Density of mitotic figures in histologic sections is a prognostically relevant characteristic for many tumours. Due to high inter-pathologist variability, deep learning-based algorithms are a promising solution to improve tumour prognostication. Pathologists are the gold standard for database development, however, labelling errors may hamper development of accurate algorithms. In the present work we evaluated the benefit of multi-expert consensus (n = 3, 5, 7, 9, 11) on algorithmic performance. While training with individual databases resulted in highly variable F$_1$ scores, performance was notably increased and more consistent when using the consensus of three annotators. Adding more annotators only resulted in minor improvements. We conclude that databases by few pathologists and high label accuracy may be the best compromise between high algorithmic performance and time investment.