 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuclear Morphometry using a Deep Learning-based Algorithm has Prognostic Relevance for Canine Cutaneous Mast Cell Tumors
Sep 26, 2023Variation in nuclear size and shape is an important criterion of malignancy for many tumor types; however, categorical estimates by pathologists have poor reproducibility. Measurements of nuclear characteristics (morphometry) can improve reproducibility, but manual methods are time consuming. In this study, we evaluated fully automated morphometry using a deep learning-based algorithm in 96 canine cutaneous mast cell tumors with information on patient survival. Algorithmic morphometry was compared with karyomegaly estimates by 11 pathologists, manual nuclear morphometry of 12 cells by 9 pathologists, and the mitotic count as a benchmark. The prognostic value of automated morphometry was high with an area under the ROC curve regarding the tumor-specific survival of 0.943 (95% CI: 0.889 - 0.996) for the standard deviation (SD) of nuclear area, which was higher than manual morphometry of all pathologists combined (0.868, 95% CI: 0.737 - 0.991) and the mitotic count (0.885, 95% CI: 0.765 - 1.00). At the proposed thresholds, the hazard ratio for algorithmic morphometry (SD of nuclear area $\geq 9.0 \mu m^2$) was 18.3 (95% CI: 5.0 - 67.1), for manual morphometry (SD of nuclear area $\geq 10.9 \mu m^2$) 9.0 (95% CI: 6.0 - 13.4), for karyomegaly estimates 7.6 (95% CI: 5.7 - 10.1), and for the mitotic count 30.5 (95% CI: 7.8 - 118.0). Inter-rater reproducibility for karyomegaly estimates was fair ($\kappa$ = 0.226) with highly variable sensitivity/specificity values for the individual pathologists. Reproducibility for manual morphometry (SD of nuclear area) was good (ICC = 0.654). This study supports the use of algorithmic morphometry as a prognostic test to overcome the limitations of estimates and manual measurements.
How Many Annotators Do We Need? -- A Study on the Influence of Inter-Observer Variability on the Reliability of Automatic Mitotic Figure Assessment
Jan 08, 2021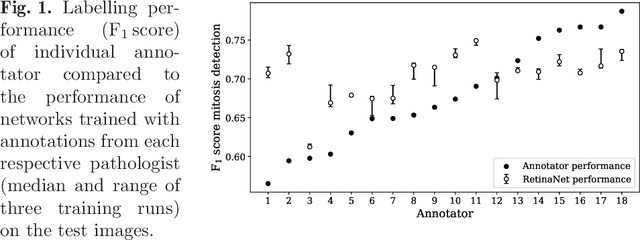
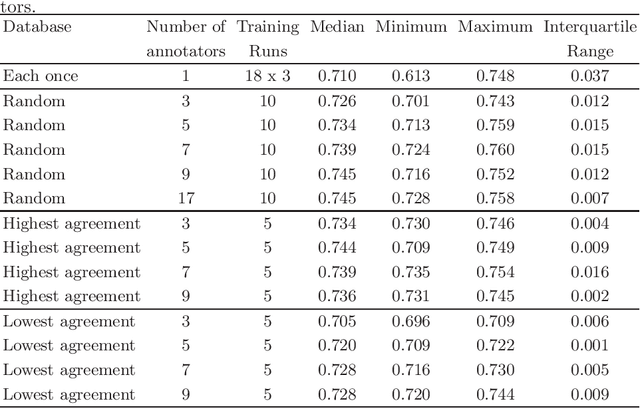
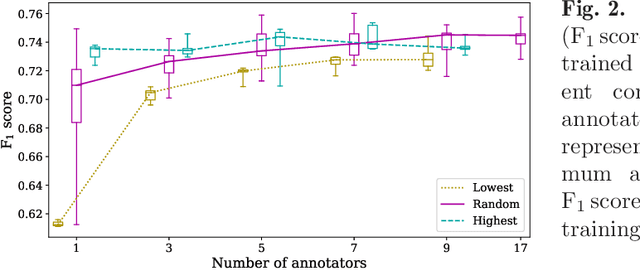
Density of mitotic figures in histologic sections is a prognostically relevant characteristic for many tumours. Due to high inter-pathologist variability, deep learning-based algorithms are a promising solution to improve tumour prognostication. Pathologists are the gold standard for database development, however, labelling errors may hamper development of accurate algorithms. In the present work we evaluated the benefit of multi-expert consensus (n = 3, 5, 7, 9, 11) on algorithmic performance. While training with individual databases resulted in highly variable F$_1$ scores, performance was notably increased and more consistent when using the consensus of three annotators. Adding more annotators only resulted in minor improvements. We conclude that databases by few pathologists and high label accuracy may be the best compromise between high algorithmic performance and time investment.