 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Manually-Generated Boilerplate from Electronic Texts: Experiments with Project Gutenberg e-Books
Aug 22, 2016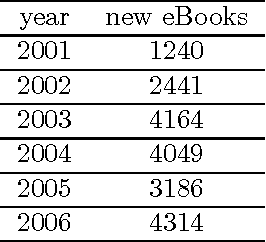
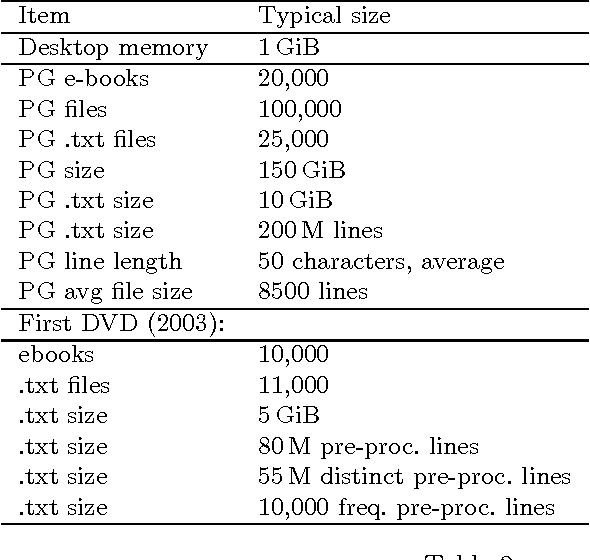
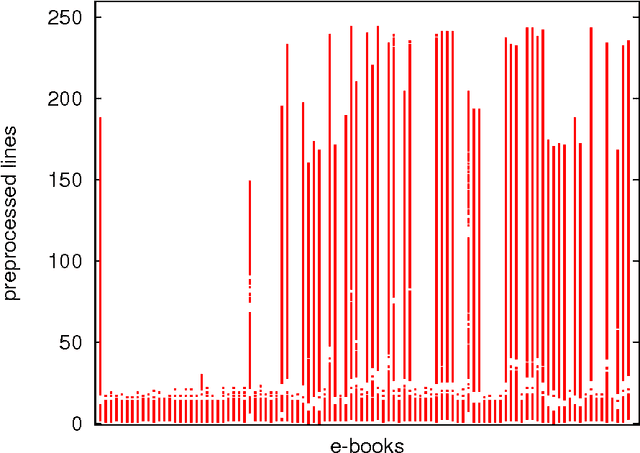
Collaborative work on unstructured or semi-structured documents, such as in literature corpora or source code, often involves agreed upon templates containing metadata. These templates are not consistent across users and over time. Rule-based parsing of these templates is expensive to maintain and tends to fail as new documents are added. Statistical techniques based on frequent occurrences have the potential to identify automatically a large fraction of the templates, thus reducing the burden on the programmers. We investigate the case of the Project Gutenberg corpus, where most documents are in ASCII format with preambles and epilogues that are often copied and pasted or manually typed. We show that a statistical approach can solve most cases though some documents require knowledge of English. We also survey various technical solutions that make our approach applicable to large data sets.
Recursive n-gram hashing is pairwise independent, at best
Jun 06, 2016
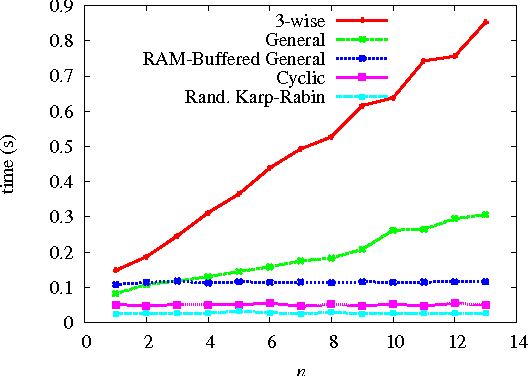
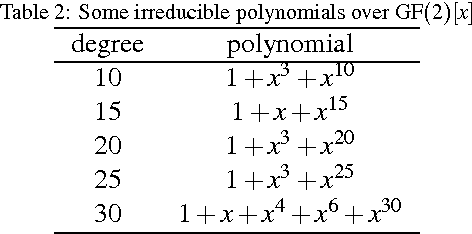
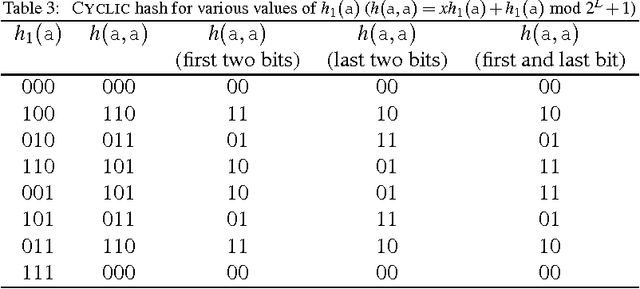
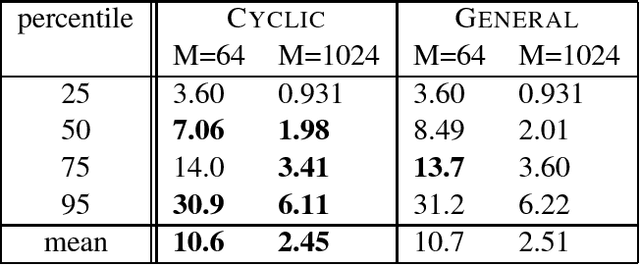
Many applications use sequences of n consecutive symbols (n-grams). Hashing these n-grams can be a performance bottleneck. For more speed, recursive hash families compute hash values by updating previous values. We prove that recursive hash families cannot be more than pairwise independent. While hashing by irreducible polynomials is pairwise independent, our implementations either run in time O(n) or use an exponential amount of memory. As a more scalable alternative, we make hashing by cyclic polynomials pairwise independent by ignoring n-1 bits. Experimentally, we show that hashing by cyclic polynomials is is twice as fast as hashing by irreducible polynomials. We also show that randomized Karp-Rabin hash families are not pairwise independent.
* See software at https://github.com/lemire/rollinghashcpp
Measuring academic influence: Not all citations are equal
Jan 26, 2015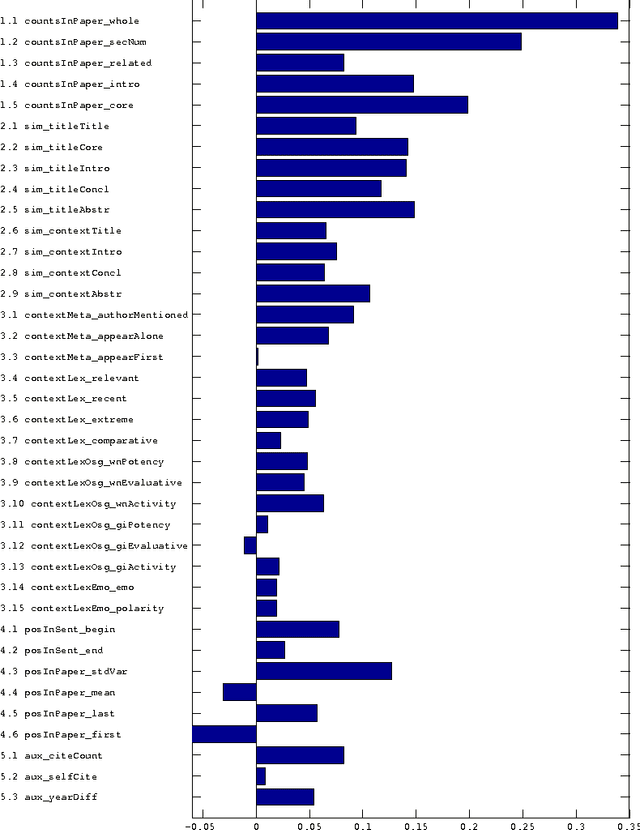
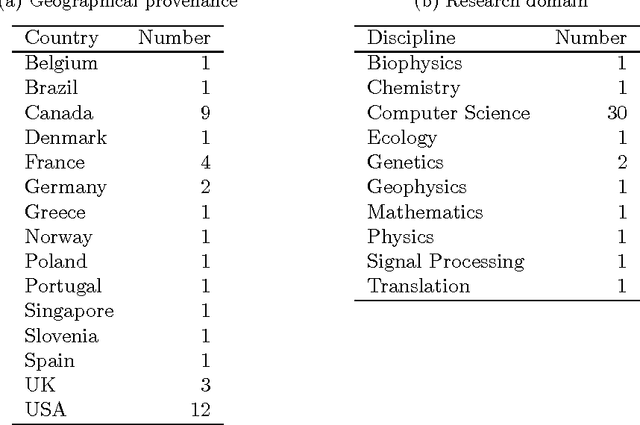

The importance of a research article is routinely measured by counting how many times it has been cited. However, treating all citations with equal weight ignores the wide variety of functions that citations perform. We want to automatically identify the subset of references in a bibliography that have a central academic influence on the citing paper. For this purpose, we examine the effectiveness of a variety of features for determining the academic influence of a citation. By asking authors to identify the key references in their own work, we created a data set in which citations were labeled according to their academic influence. Using automatic feature selection with supervised machine learning, we found a model for predicting academic influence that achieves good performance on this data set using only four features. The best features, among those we evaluated, were those based on the number of times a reference is mentioned in the body of a citing paper. The performance of these features inspired us to design an influence-primed h-index (the hip-index). Unlike the conventional h-index, it weights citations by how many times a reference is mentioned. According to our experiments, the hip-index is a better indicator of researcher performance than the conventional h-index.
One-Pass, One-Hash n-Gram Statistics Estimation
Feb 04, 2014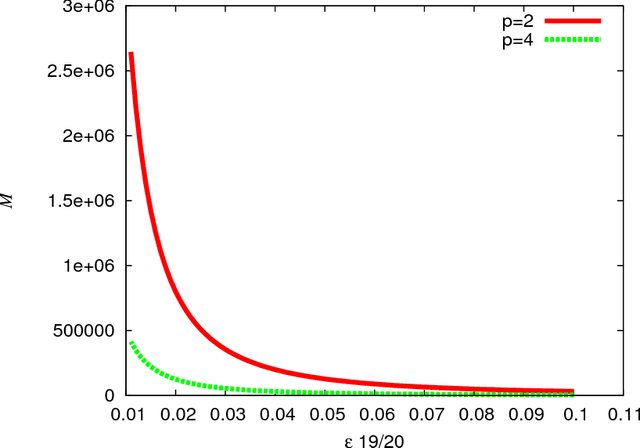
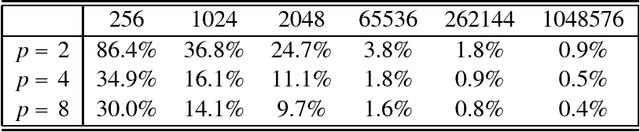
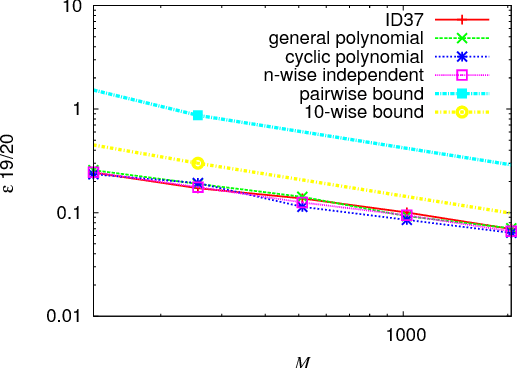
In multimedia, text or bioinformatics databases, applications query sequences of n consecutive symbols called n-grams. Estimating the number of distinct n-grams is a view-size estimation problem. While view sizes can be estimated by sampling under statistical assumptions, we desire an unassuming algorithm with universally valid accuracy bounds. Most related work has focused on repeatedly hashing the data, which is prohibitive for large data sources. We prove that a one-pass one-hash algorithm is sufficient for accurate estimates if the hashing is sufficiently independent. To reduce costs further, we investigate recursive random hashing algorithms and show that they are sufficiently independent in practice. We compare our running times with exact counts using suffix arrays and show that, while we use hardly any storage, we are an order of magnitude faster. The approach further is extended to a one-pass/one-hash computation of n-gram entropy and iceberg counts. The experiments use a large collection of English text from the Gutenberg Project as well as synthetic data.
Time Series Classification by Class-Specific Mahalanobis Distance Measures
Jul 02, 2012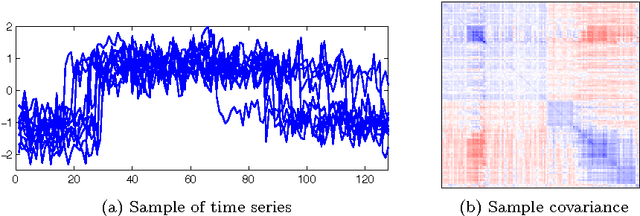
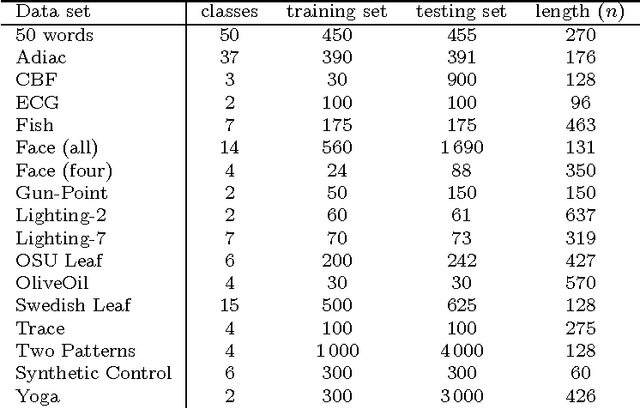
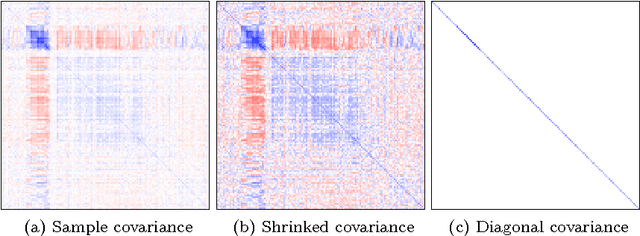
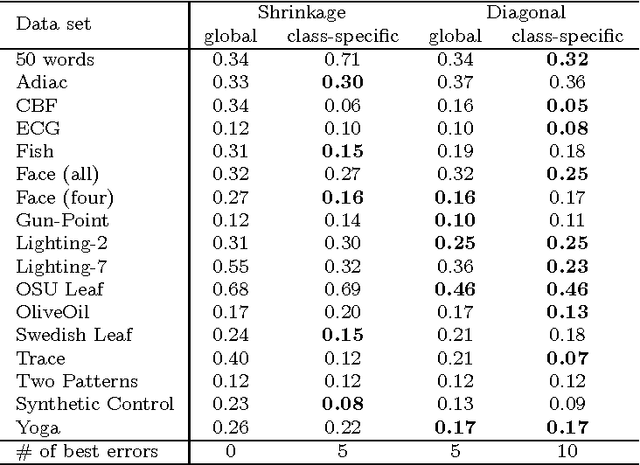
To classify time series by nearest neighbors, we need to specify or learn one or several distance measures. We consider variations of the Mahalanobis distance measures which rely on the inverse covariance matrix of the data. Unfortunately --- for time series data --- the covariance matrix has often low rank. To alleviate this problem we can either use a pseudoinverse, covariance shrinking or limit the matrix to its diagonal. We review these alternatives and benchmark them against competitive methods such as the related Large Margin Nearest Neighbor Classification (LMNN) and the Dynamic Time Warping (DTW) distance. As we expected, we find that the DTW is superior, but the Mahalanobis distance measures are one to two orders of magnitude faster. To get best results with Mahalanobis distance measures, we recommend learning one distance measure per class using either covariance shrinking or the diagonal approach.
Faster Retrieval with a Two-Pass Dynamic-Time-Warping Lower Bound
Jun 10, 2009
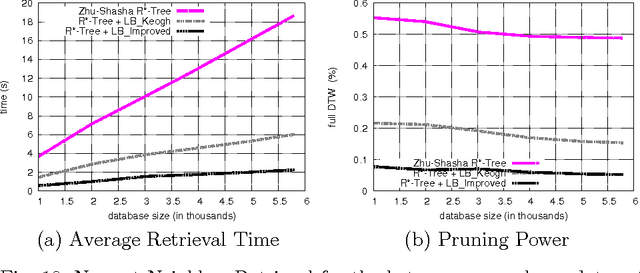
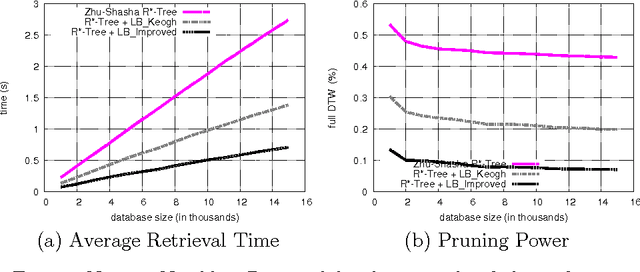
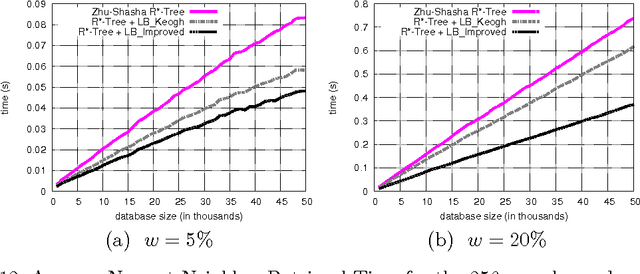
The Dynamic Time Warping (DTW) is a popular similarity measure between time series. The DTW fails to satisfy the triangle inequality and its computation requires quadratic time. Hence, to find closest neighbors quickly, we use bounding techniques. We can avoid most DTW computations with an inexpensive lower bound (LB Keogh). We compare LB Keogh with a tighter lower bound (LB Improved). We find that LB Improved-based search is faster. As an example, our approach is 2-3 times faster over random-walk and shape time series.
* Accepted in Pattern Recognition on November 20th, 2008
Slope One Predictors for Online Rating-Based Collaborative Filtering
Sep 15, 2008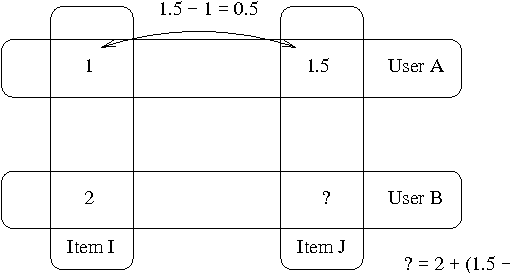
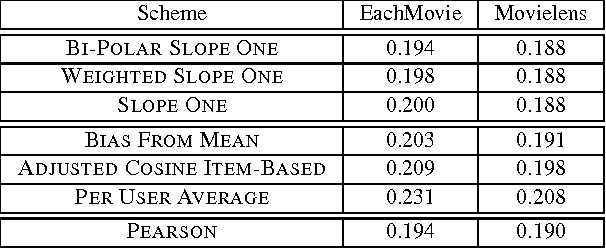
Rating-based collaborative filtering is the process of predicting how a user would rate a given item from other user ratings. We propose three related slope one schemes with predictors of the form f(x) = x + b, which precompute the average difference between the ratings of one item and another for users who rated both. Slope one algorithms are easy to implement, efficient to query, reasonably accurate, and they support both online queries and dynamic updates, which makes them good candidates for real-world systems. The basic slope one scheme is suggested as a new reference scheme for collaborative filtering. By factoring in items that a user liked separately from items that a user disliked, we achieve results competitive with slower memory-based schemes over the standard benchmark EachMovie and Movielens data sets while better fulfilling the desiderata of CF applications.
A Better Alternative to Piecewise Linear Time Series Segmentation
Apr 28, 2007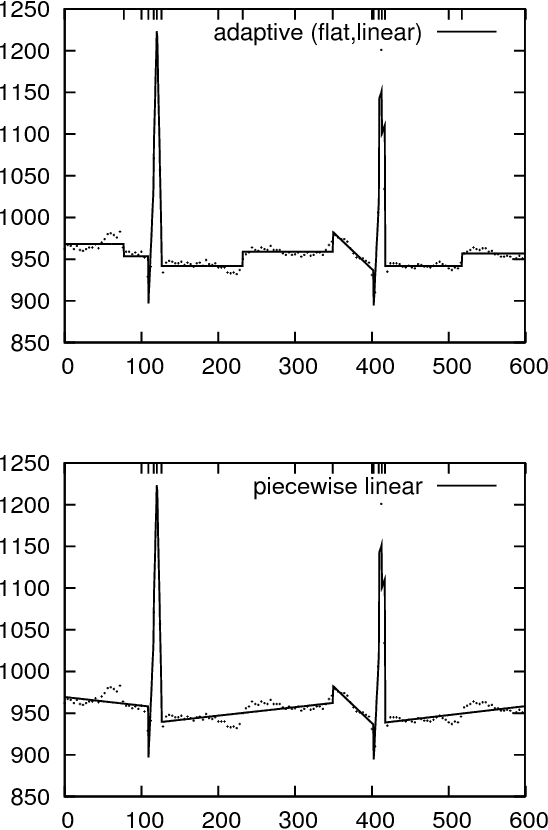
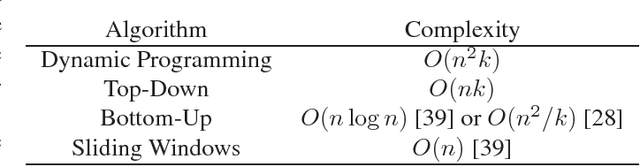
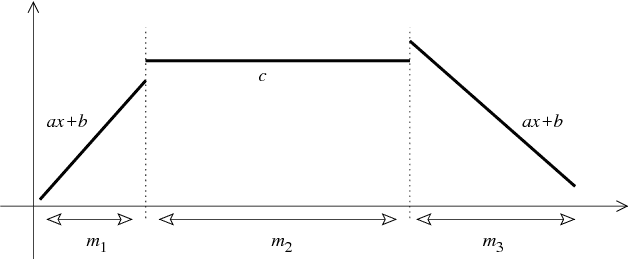
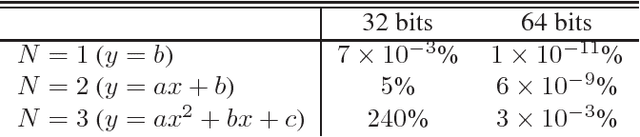
Time series are difficult to monitor, summarize and predict. Segmentation organizes time series into few intervals having uniform characteristics (flatness, linearity, modality, monotonicity and so on). For scalability, we require fast linear time algorithms. The popular piecewise linear model can determine where the data goes up or down and at what rate. Unfortunately, when the data does not follow a linear model, the computation of the local slope creates overfitting. We propose an adaptive time series model where the polynomial degree of each interval vary (constant, linear and so on). Given a number of regressors, the cost of each interval is its polynomial degree: constant intervals cost 1 regressor, linear intervals cost 2 regressors, and so on. Our goal is to minimize the Euclidean (l_2) error for a given model complexity. Experimentally, we investigate the model where intervals can be either constant or linear. Over synthetic random walks, historical stock market prices, and electrocardiograms, the adaptive model provides a more accurate segmentation than the piecewise linear model without increasing the cross-validation error or the running time, while providing a richer vocabulary to applications. Implementation issues, such as numerical stability and real-world performance, are discussed.