 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Classification by Class-Specific Mahalanobis Distance Measures
Paper and Code
Jul 02, 2012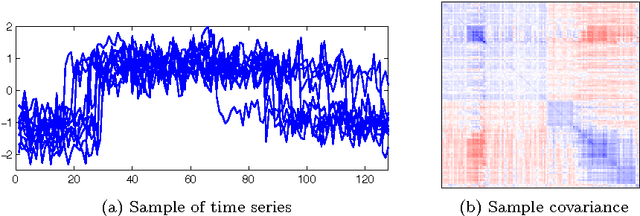
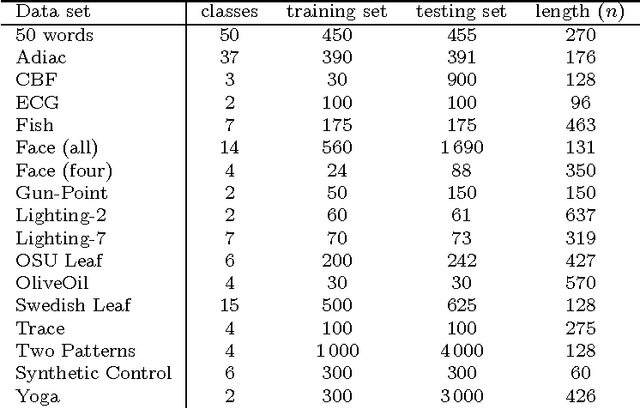
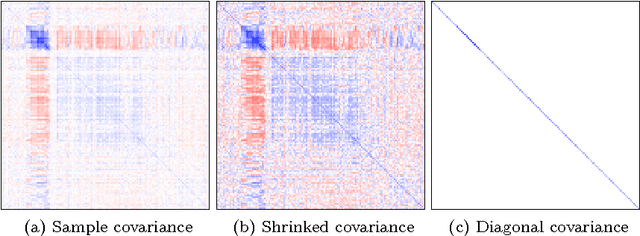
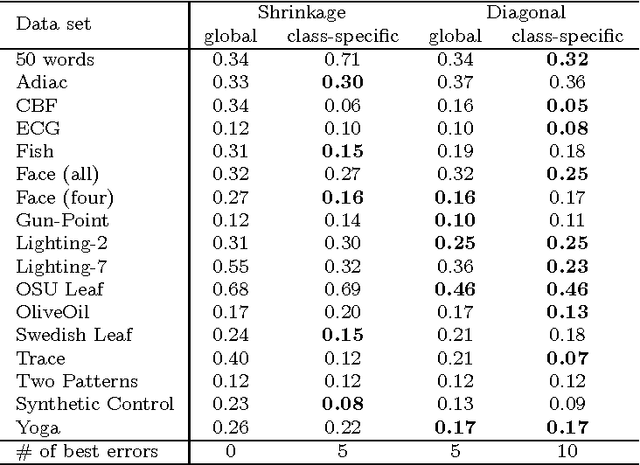
To classify time series by nearest neighbors, we need to specify or learn one or several distance measures. We consider variations of the Mahalanobis distance measures which rely on the inverse covariance matrix of the data. Unfortunately --- for time series data --- the covariance matrix has often low rank. To alleviate this problem we can either use a pseudoinverse, covariance shrinking or limit the matrix to its diagonal. We review these alternatives and benchmark them against competitive methods such as the related Large Margin Nearest Neighbor Classification (LMNN) and the Dynamic Time Warping (DTW) distance. As we expected, we find that the DTW is superior, but the Mahalanobis distance measures are one to two orders of magnitude faster. To get best results with Mahalanobis distance measures, we recommend learning one distance measure per class using either covariance shrinking or the diagonal approach.