 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering the Data-Related Limits of Human Reasoning Research: An Analysis based on Recommender Systems
Mar 11, 2020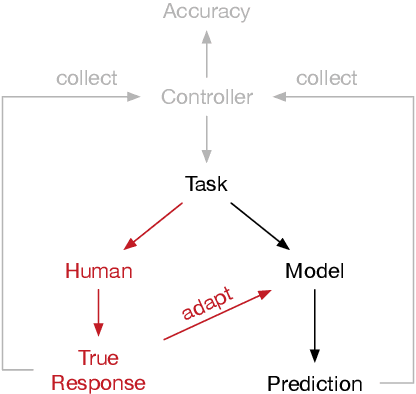
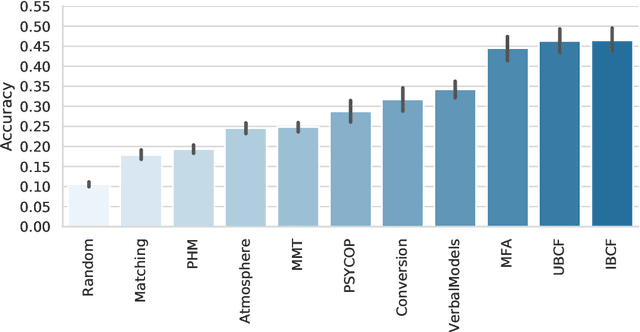
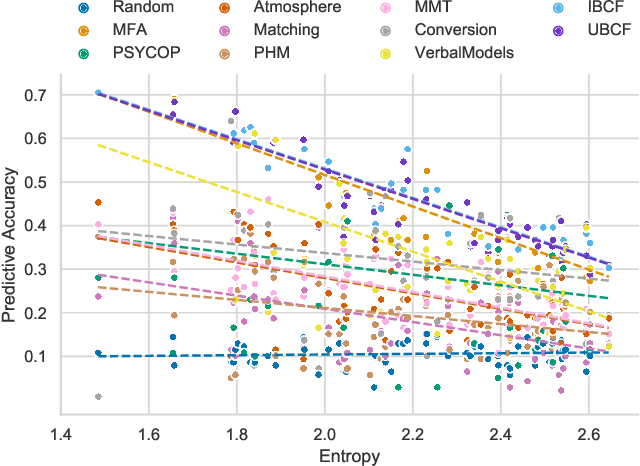
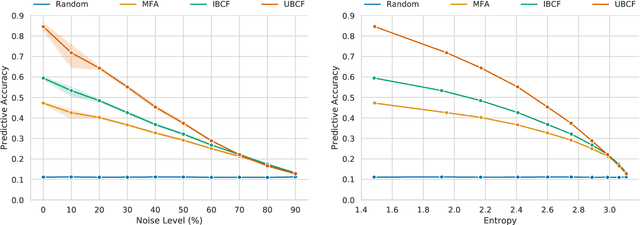
Understanding the fundamentals of human reasoning is central to the development of any system built to closely interact with humans. Cognitive science pursues the goal of modeling human-like intelligence from a theory-driven perspective with a strong focus on explainability. Syllogistic reasoning as one of the core domains of human reasoning research has seen a surge of computational models being developed over the last years. However, recent analyses of models' predictive performances revealed a stagnation in improvement. We believe that most of the problems encountered in cognitive science are not due to the specific models that have been developed but can be traced back to the peculiarities of behavioral data instead. Therefore, we investigate potential data-related reasons for the problems in human reasoning research by comparing model performances on human and artificially generated datasets. In particular, we apply collaborative filtering recommenders to investigate the adversarial effects of inconsistencies and noise in data and illustrate the potential for data-driven methods in a field of research predominantly concerned with gaining high-level theoretical insight into a domain. Our work (i) provides insight into the levels of noise to be expected from human responses in reasoning data, (ii) uncovers evidence for an upper-bound of performance that is close to being reached urging for an extension of the modeling task, and (iii) introduces the tools and presents initial results to pioneer a new paradigm for investigating and modeling reasoning focusing on predicting responses for individual human reasoners.
Training Deep Neural Networks with 8-bit Floating Point Numbers
Dec 19, 2018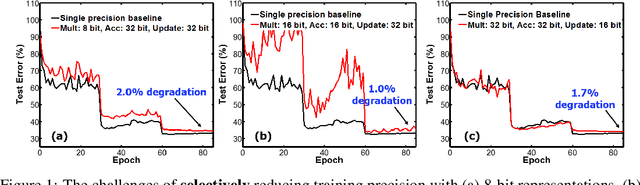

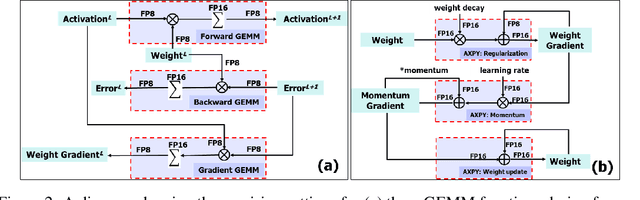
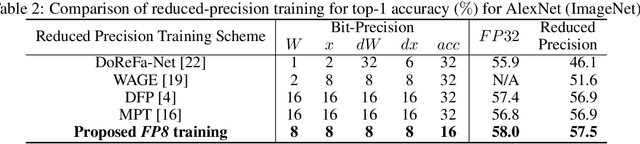
The state-of-the-art hardware platforms for training Deep Neural Networks (DNNs) are moving from traditional single precision (32-bit) computations towards 16 bits of precision -- in large part due to the high energy efficiency and smaller bit storage associated with using reduced-precision representations. However, unlike inference, training with numbers represented with less than 16 bits has been challenging due to the need to maintain fidelity of the gradient computations during back-propagation. Here we demonstrate, for the first time, the successful training of DNNs using 8-bit floating point numbers while fully maintaining the accuracy on a spectrum of Deep Learning models and datasets. In addition to reducing the data and computation precision to 8 bits, we also successfully reduce the arithmetic precision for additions (used in partial product accumulation and weight updates) from 32 bits to 16 bits through the introduction of a number of key ideas including chunk-based accumulation and floating point stochastic rounding. The use of these novel techniques lays the foundation for a new generation of hardware training platforms with the potential for 2-4x improved throughput over today's systems.
AdaComp : Adaptive Residual Gradient Compression for Data-Parallel Distributed Training
Dec 07, 2017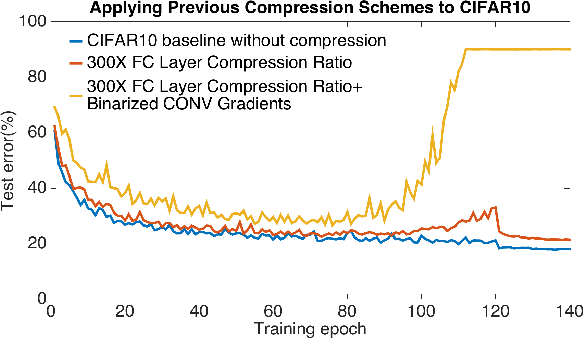
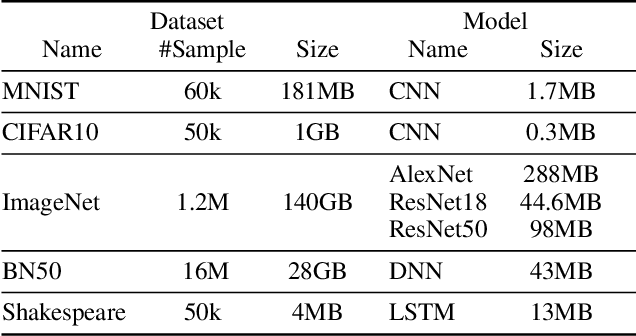
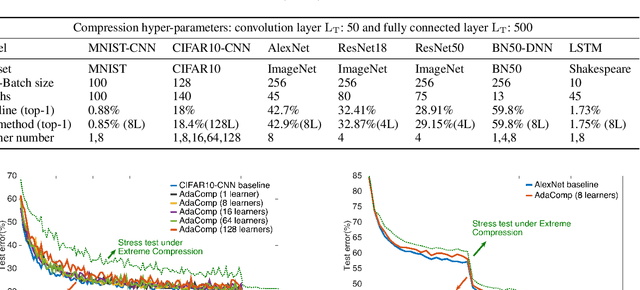
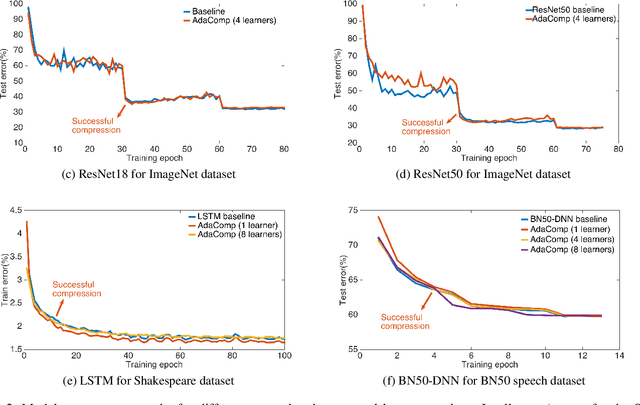
Highly distributed training of Deep Neural Networks (DNNs) on future compute platforms (offering 100 of TeraOps/s of computational capacity) is expected to be severely communication constrained. To overcome this limitation, new gradient compression techniques are needed that are computationally friendly, applicable to a wide variety of layers seen in Deep Neural Networks and adaptable to variations in network architectures as well as their hyper-parameters. In this paper we introduce a novel technique - the Adaptive Residual Gradient Compression (AdaComp) scheme. AdaComp is based on localized selection of gradient residues and automatically tunes the compression rate depending on local activity. We show excellent results on a wide spectrum of state of the art Deep Learning models in multiple domains (vision, speech, language), datasets (MNIST, CIFAR10, ImageNet, BN50, Shakespeare), optimizers (SGD with momentum, Adam) and network parameters (number of learners, minibatch-size etc.). Exploiting both sparsity and quantization, we demonstrate end-to-end compression rates of ~200X for fully-connected and recurrent layers, and ~40X for convolutional layers, without any noticeable degradation in model accuracies.
MEC: Memory-efficient Convolution for Deep Neural Network
Jun 21, 2017
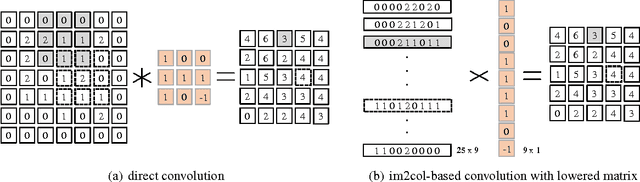
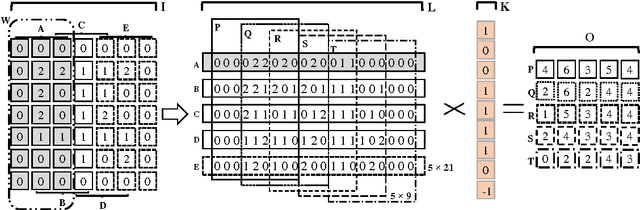
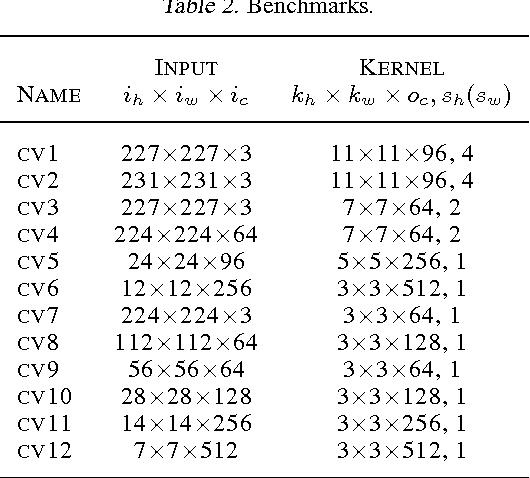
Convolution is a critical component in modern deep neural networks, thus several algorithms for convolution have been developed. Direct convolution is simple but suffers from poor performance. As an alternative, multiple indirect methods have been proposed including im2col-based convolution, FFT-based convolution, or Winograd-based algorithm. However, all these indirect methods have high memory-overhead, which creates performance degradation and offers a poor trade-off between performance and memory consumption. In this work, we propose a memory-efficient convolution or MEC with compact lowering, which reduces memory-overhead substantially and accelerates convolution process. MEC lowers the input matrix in a simple yet efficient/compact way (i.e., much less memory-overhead), and then executes multiple small matrix multiplications in parallel to get convolution completed. Additionally, the reduced memory footprint improves memory sub-system efficiency, improving performance. Our experimental results show that MEC reduces memory consumption significantly with good speedup on both mobile and server platforms, compared with other indirect convolution algorithms.