 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaComp : Adaptive Residual Gradient Compression for Data-Parallel Distributed Training
Paper and Code
Dec 07, 2017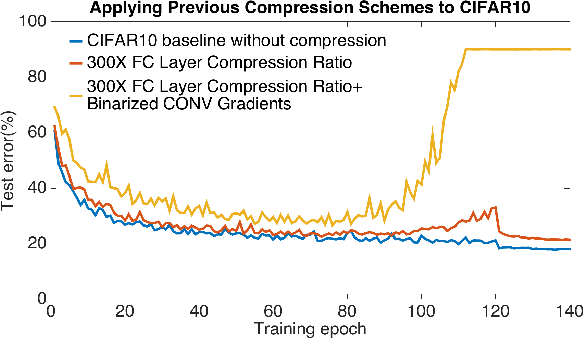
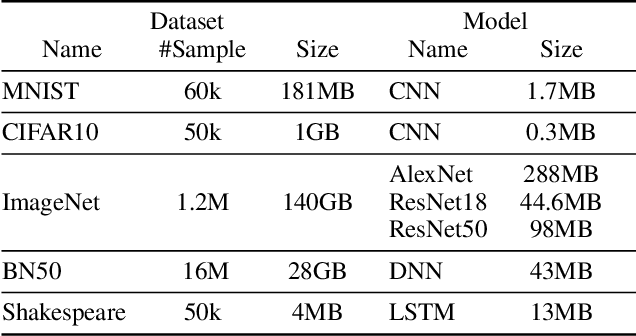
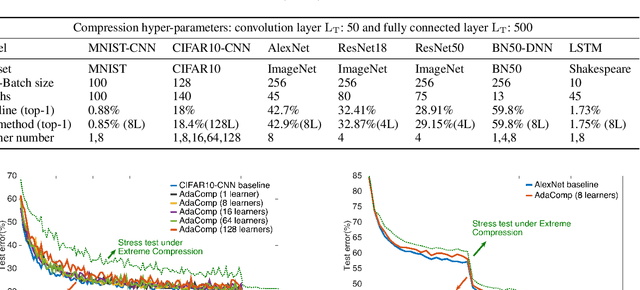
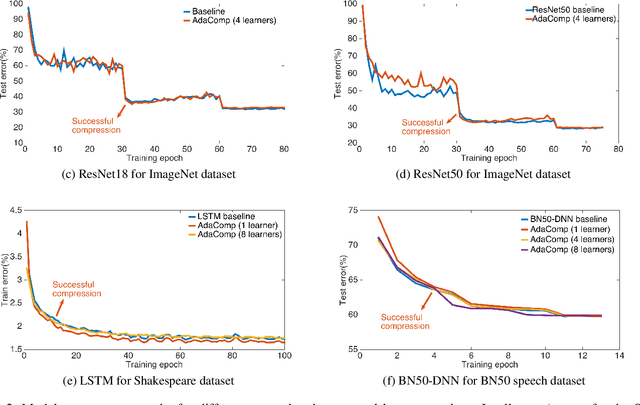
Highly distributed training of Deep Neural Networks (DNNs) on future compute platforms (offering 100 of TeraOps/s of computational capacity) is expected to be severely communication constrained. To overcome this limitation, new gradient compression techniques are needed that are computationally friendly, applicable to a wide variety of layers seen in Deep Neural Networks and adaptable to variations in network architectures as well as their hyper-parameters. In this paper we introduce a novel technique - the Adaptive Residual Gradient Compression (AdaComp) scheme. AdaComp is based on localized selection of gradient residues and automatically tunes the compression rate depending on local activity. We show excellent results on a wide spectrum of state of the art Deep Learning models in multiple domains (vision, speech, language), datasets (MNIST, CIFAR10, ImageNet, BN50, Shakespeare), optimizers (SGD with momentum, Adam) and network parameters (number of learners, minibatch-size etc.). Exploiting both sparsity and quantization, we demonstrate end-to-end compression rates of ~200X for fully-connected and recurrent layers, and ~40X for convolutional layers, without any noticeable degradation in model accuracies.