 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Binary Encoded Crime Linkage Analysis Using Siamese Network
Nov 10, 2025Effective crime linkage analysis is crucial for identifying serial offenders and enhancing public safety. To address limitations of traditional crime linkage methods in handling high-dimensional, sparse, and heterogeneous data, we propose a Siamese Autoencoder framework that learns meaningful latent representations and uncovers correlations in complex crime data. Using data from the Violent Crime Linkage Analysis System (ViCLAS), maintained by the Serious Crime Analysis Section of the UK's National Crime Agency, our approach mitigates signal dilution in sparse feature spaces by integrating geographic-temporal features at the decoder stage. This design amplifies behavioral representations rather than allowing them to be overshadowed at the input level, yielding consistent improvements across multiple evaluation metrics. We further analyze how different domain-informed data reduction strategies influence model performance, providing practical guidance for preprocessing in crime linkage contexts. Our results show that advanced machine learning approaches can substantially enhance linkage accuracy, improving AUC by up to 9% over traditional methods while offering interpretable insights to support investigative decision-making.
Towards User-Centred Design of AI-Assisted Decision-Making in Law Enforcement
Apr 24, 2025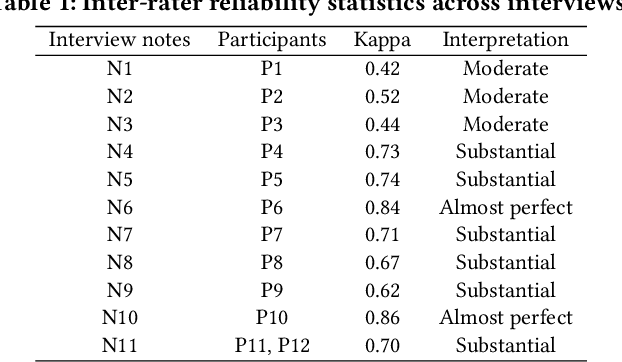
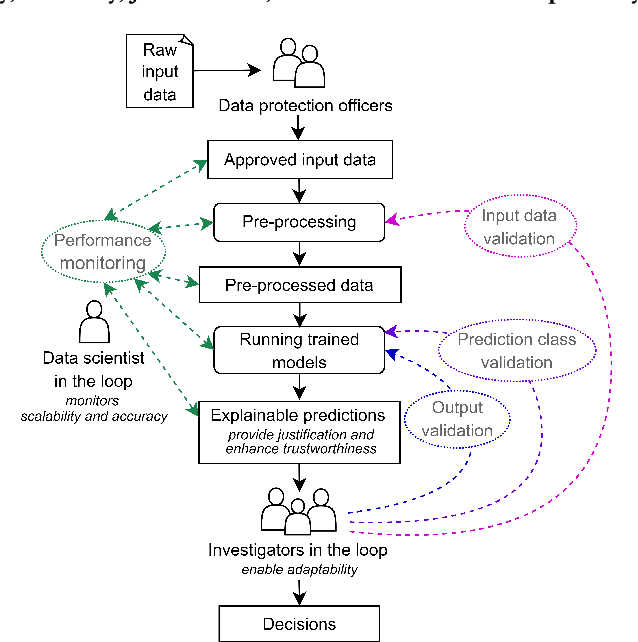
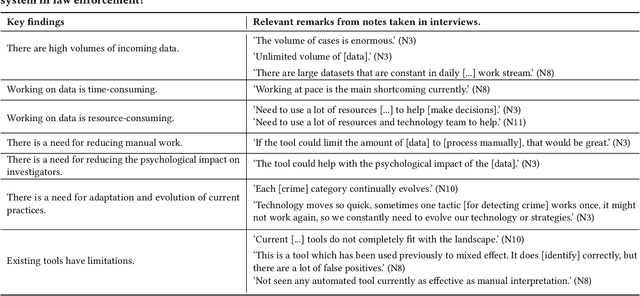
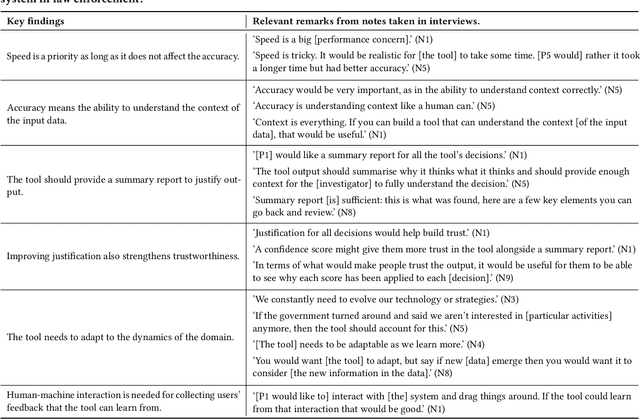
Artificial Intelligence (AI) has become an important part of our everyday lives, yet user requirements for designing AI-assisted systems in law enforcement remain unclear. To address this gap, we conducted qualitative research on decision-making within a law enforcement agency. Our study aimed to identify limitations of existing practices, explore user requirements and understand the responsibilities that humans expect to undertake in these systems. Participants in our study highlighted the need for a system capable of processing and analysing large volumes of data efficiently to help in crime detection and prevention. Additionally, the system should satisfy requirements for scalability, accuracy, justification, trustworthiness and adaptability to be adopted in this domain. Participants also emphasised the importance of having end users review the input data that might be challenging for AI to interpret, and validate the generated output to ensure the system's accuracy. To keep up with the evolving nature of the law enforcement domain, end users need to help the system adapt to the changes in criminal behaviour and government guidance, and technical experts need to regularly oversee and monitor the system. Furthermore, user-friendly human interaction with the system is essential for its adoption and some of the participants confirmed they would be happy to be in the loop and provide necessary feedback that the system can learn from. Finally, we argue that it is very unlikely that the system will ever achieve full automation due to the dynamic and complex nature of the law enforcement domain.
RECAP-KG: Mining Knowledge Graphs from Raw GP Notes for Remote COVID-19 Assessment in Primary Care
Jun 17, 2023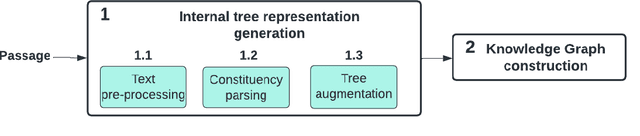

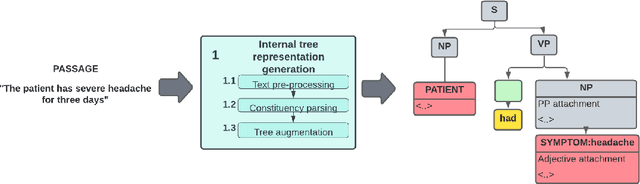
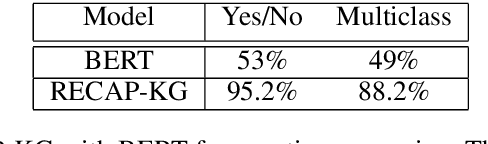
Clinical decision-making is a fundamental stage in delivering appropriate care to patients. In recent years several decision-making systems designed to aid the clinician in this process have been developed. However, technical solutions currently in use are based on simple regression models and are only able to take into account simple pre-defined multiple-choice features, such as patient age, pre-existing conditions, smoker status, etc. One particular source of patient data, that available decision-making systems are incapable of processing is the collection of patient consultation GP notes. These contain crucial signs and symptoms - the information used by clinicians in order to make a final decision and direct the patient to the appropriate care. Extracting information from GP notes is a technically challenging problem, as they tend to include abbreviations, typos, and incomplete sentences. This paper addresses this open challenge. We present a framework that performs knowledge graph construction from raw GP medical notes written during or after patient consultations. By relying on support phrases mined from the SNOMED ontology, as well as predefined supported facts from values used in the RECAP (REmote COVID-19 Assessment in Primary Care) patient risk prediction tool, our graph generative framework is able to extract structured knowledge graphs from the highly unstructured and inconsistent format that consultation notes are written in. Our knowledge graphs include information about existing patient symptoms, their duration, and their severity. We apply our framework to consultation notes of COVID-19 patients in the UK COVID-19 Clinical Assesment Servcie (CCAS) patient dataset. We provide a quantitative evaluation of the performance of our framework, demonstrating that our approach has better accuracy than traditional NLP methods when answering questions about patients.
Combining Experts' Causal Judgments
May 20, 2020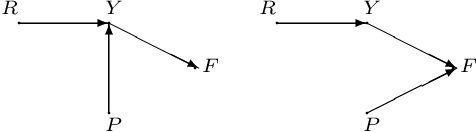
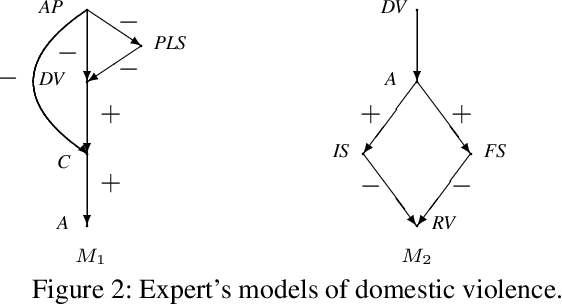
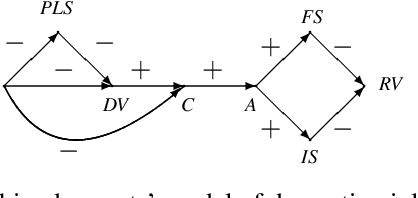
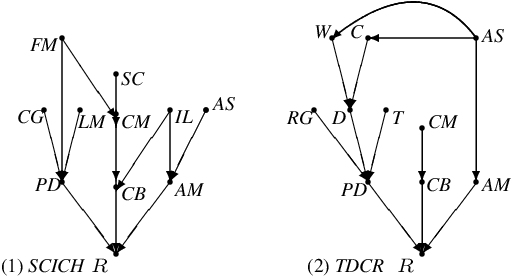
Consider a policymaker who wants to decide which intervention to perform in order to change a currently undesirable situation. The policymaker has at her disposal a team of experts, each with their own understanding of the causal dependencies between different factors contributing to the outcome. The policymaker has varying degrees of confidence in the experts' opinions. She wants to combine their opinions in order to decide on the most effective intervention. We formally define the notion of an effective intervention, and then consider how experts' causal judgments can be combined in order to determine the most effective intervention. We define a notion of two causal models being \emph{compatible}, and show how compatible causal models can be merged. We then use it as the basis for combining experts' causal judgments. We also provide a definition of decomposition for causal models to cater for cases when models are incompatible. We illustrate our approach on a number of real-life examples.
Learning Neural Search Policies for Classical Planning
Nov 27, 2019
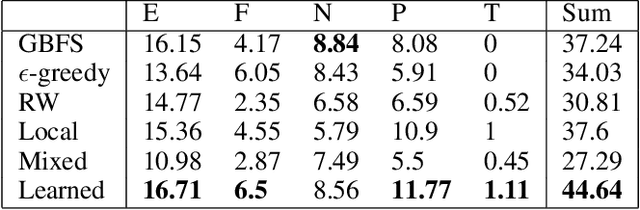
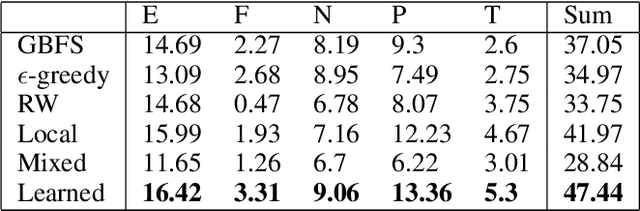
Heuristic forward search is currently the dominant paradigm in classical planning. Forward search algorithms typically rely on a single, relatively simple variation of best-first search and remain fixed throughout the process of solving a planning problem. Existing work combining multiple search techniques usually aims at supporting best-first search with an additional exploratory mechanism, triggered using a handcrafted criterion. A notable exception is very recent work which combines various search techniques using a trainable policy. It is, however, confined to a discrete action space comprising several fixed subroutines. In this paper, we introduce a parametrized search algorithm template which combines various search techniques within a single routine. The template's parameter space defines an infinite space of search algorithms, including, among others, BFS, local and random search. We further introduce a neural architecture for designating the values of the search parameters given the state of the search. This enables expressing neural search policies that change the values of the parameters as the search progresses. The policies can be learned automatically, with the objective of maximizing the planner's performance on a given distribution of planning problems. We consider a training setting based on a stochastic optimization algorithm known as the cross-entropy method (CEM). Experimental evaluation of our approach shows that it is capable of finding effective distribution-specific search policies, outperforming the relevant baselines.
Learning Classical Planning Strategies with Policy Gradient
Oct 23, 2018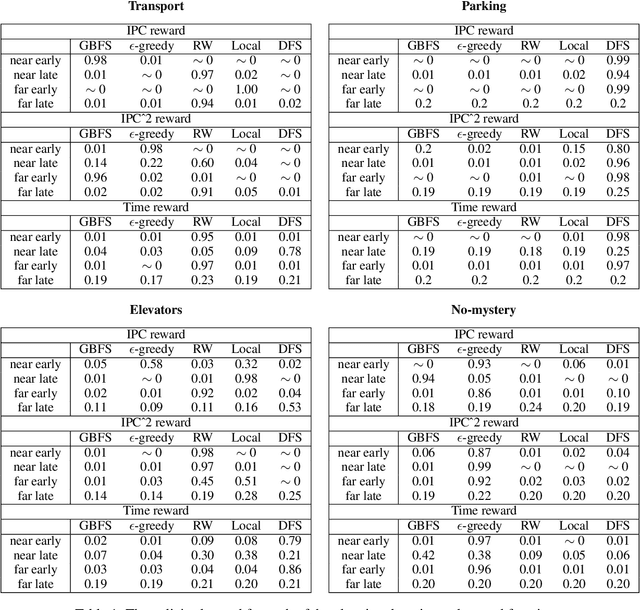
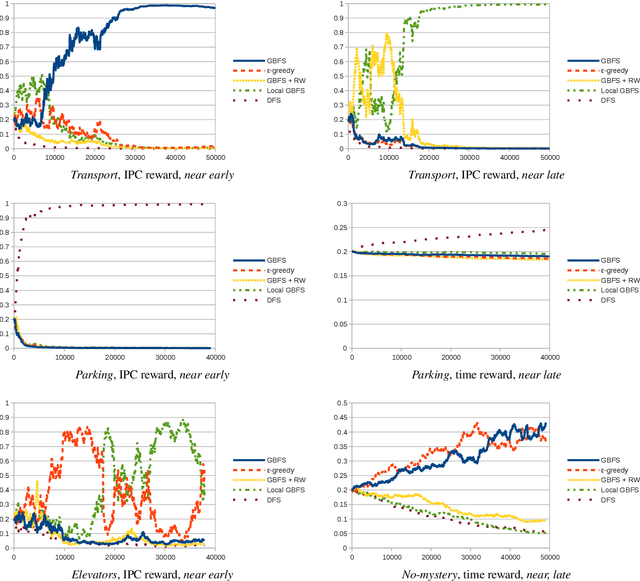
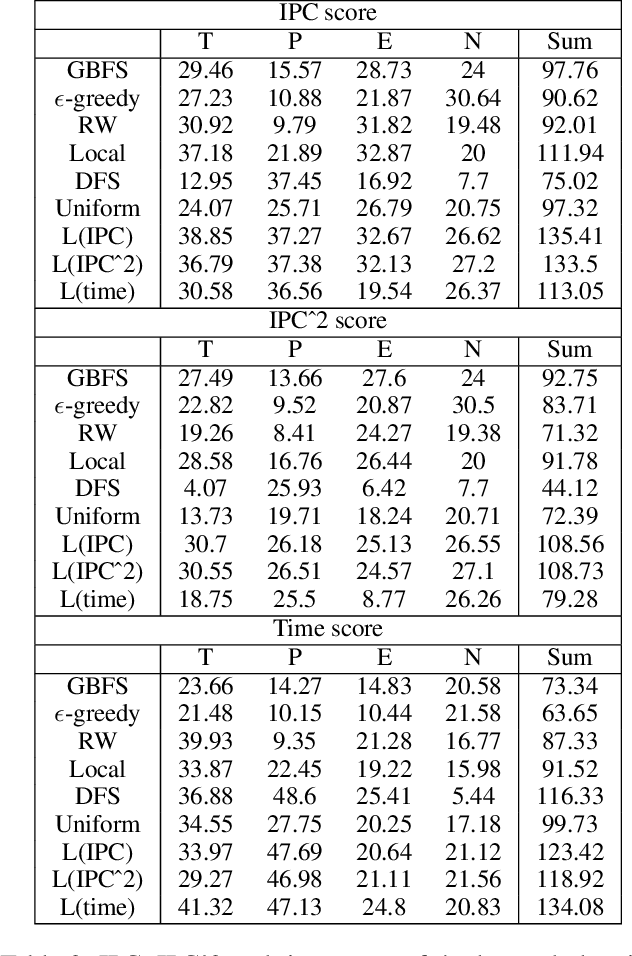
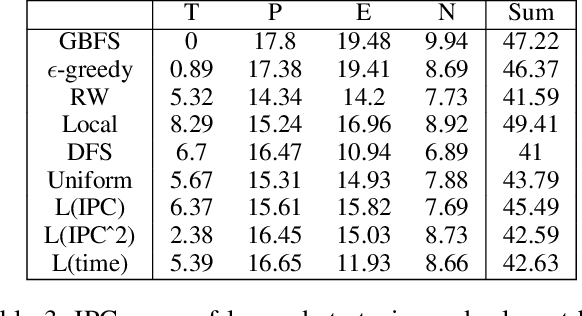
A common paradigm in classical planning is heuristic forward search. Forward search planners often rely on relatively simple best-first search algorithm, which remains fixed throughout the search process. In this paper, we introduce a novel search framework capable of alternating between several forward search approaches while solving a particular planning problem. Selection of the approach is performed using a trainable stochastic policy. This enables tailoring the search strategy to a particular distribution of planning problems and a selected performance metric, such as the IPC score or running time. We construct a strategy space using five search algorithms and a two-dimensional representation of the planner's state. Strategies are then trained on randomly generated planning problems using policy gradient. Experimental results show that the learner is able to discover domain-specific search strategies, thus improving the planner's performance with respect to the chosen metric.
Towards learning domain-independent planning heuristics
Jul 21, 2017
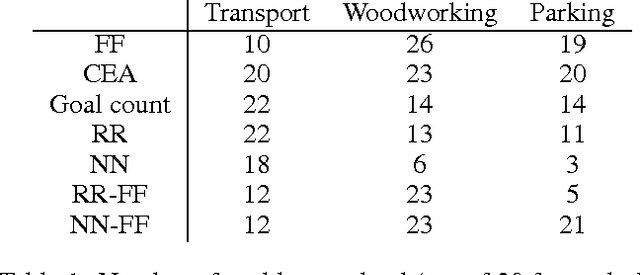
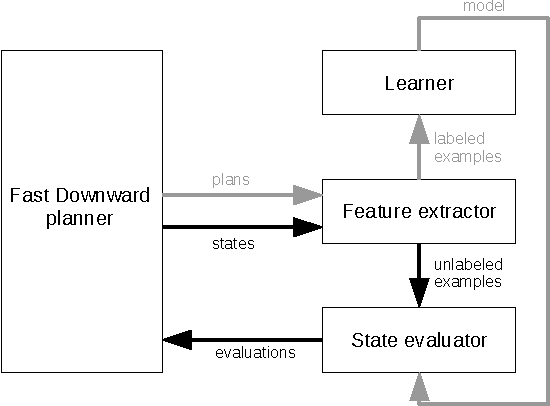
Automated planning remains one of the most general paradigms in Artificial Intelligence, providing means of solving problems coming from a wide variety of domains. One of the key factors restricting the applicability of planning is its computational complexity resulting from exponentially large search spaces. Heuristic approaches are necessary to solve all but the simplest problems. In this work, we explore the possibility of obtaining domain-independent heuristic functions using machine learning. This is a part of a wider research program whose objective is to improve practical applicability of planning in systems for which the planning domains evolve at run time. The challenge is therefore the learning of (corrections of) domain-independent heuristics that can be reused across different planning domains.