 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Signature Verification Based on Writer Specific Feature Selection and Fuzzy Similarity Measure
May 21, 2019
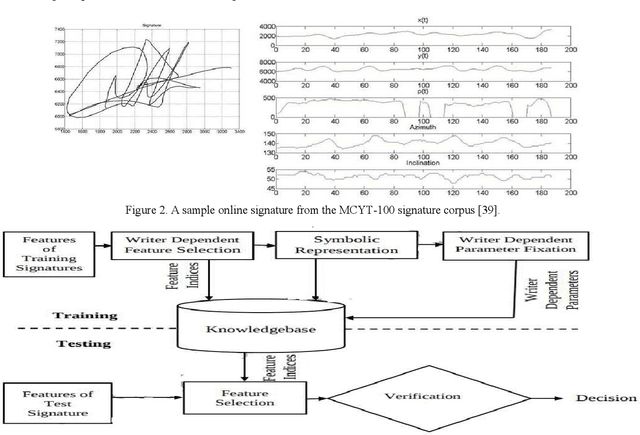

Online Signature Verification (OSV) is a widely used biometric attribute for user behavioral characteristic verification in digital forensics. In this manuscript, owing to large intra-individual variability, a novel method for OSV based on an interval symbolic representation and a fuzzy similarity measure grounded on writer specific parameter selection is proposed. The two parameters, namely, writer specific acceptance threshold and optimal feature set to be used for authenticating the writer are selected based on minimum equal error rate (EER) attained during parameter fixation phase using the training signature samples. This is in variation to current techniques for OSV, which are primarily writer independent, in which a common set of features and acceptance threshold are chosen. To prove the robustness of our system, we have exhaustively assessed our system with four standard datasets i.e. MCYT-100 (DB1), MCYT-330 (DB2), SUSIG-Visual corpus and SVC-2004- Task2. Experimental outcome confirms the effectiveness of fuzzy similarity metric-based writer dependent parameter selection for OSV by achieving a lower error rate as compared to many recent and state-of-the art OSV models.
Color and Gradient Features for Text Segmentation from Video Frames
Aug 22, 2017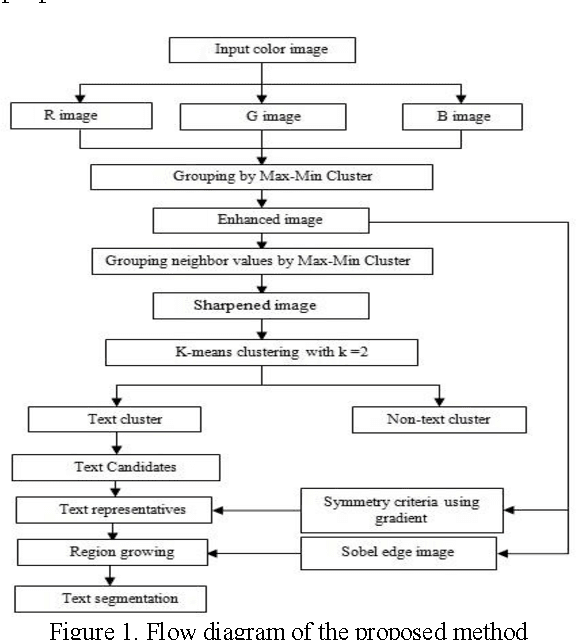



Text segmentation in a video is drawing attention of researchers in the field of image processing, pattern recognition and document image analysis because it helps in annotating and labeling video events accurately. We propose a novel idea of generating an enhanced frame from the R, G, and B channels of an input frame by grouping high and low values using Min-Max clustering criteria. We also perform sliding window on enhanced frame to group high and low values from the neighboring pixel values to further enhance the frame. Subsequently, we use k-means with k=2 clustering algorithm to separate text and non-text regions. The fully connected components will be identified in the skeleton of the frame obtained by k-means clustering. Concept of connected component analysis based on gradient feature has been adapted for the purpose of symmetry verification. The components which satisfy symmetric verification are selected to be the representatives of text regions and they are permitted to grow to cover their respective region fully containing text. The method is tested on variety of video frames to evaluate the performance of the method in terms of recall, precision and f-measure. The results show that method is promising and encouraging.
Semi-supervised Text Categorization Using Recursive K-means Clustering
Jun 24, 2017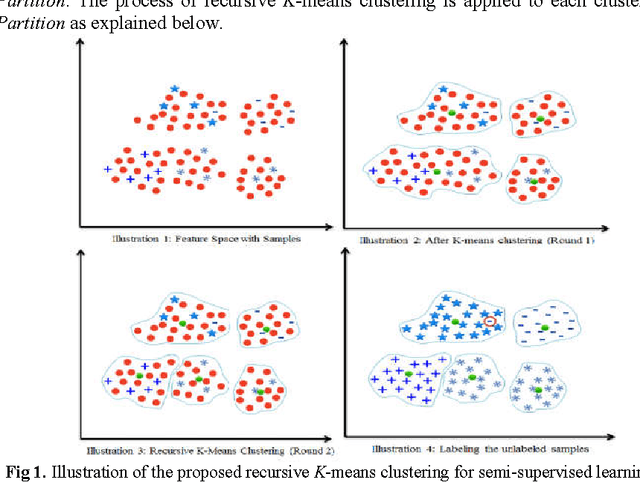
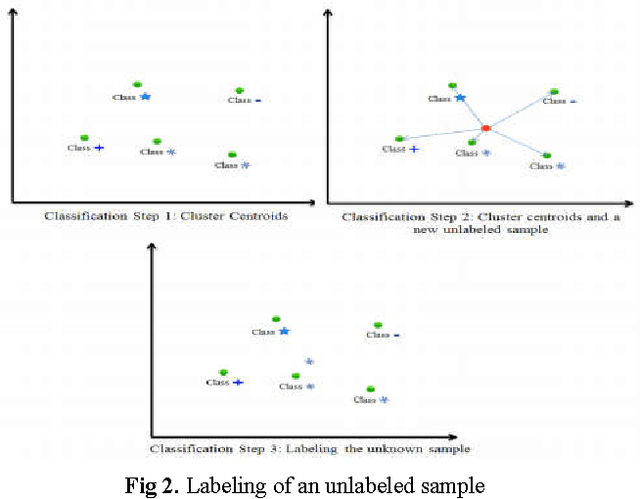
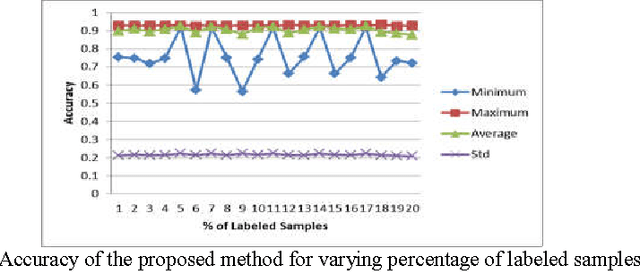
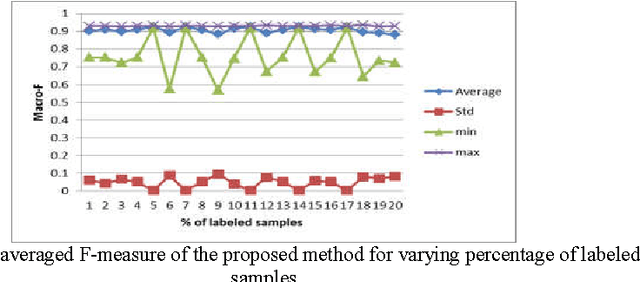
In this paper, we present a semi-supervised learning algorithm for classification of text documents. A method of labeling unlabeled text documents is presented. The presented method is based on the principle of divide and conquer strategy. It uses recursive K-means algorithm for partitioning both labeled and unlabeled data collection. The K-means algorithm is applied recursively on each partition till a desired level partition is achieved such that each partition contains labeled documents of a single class. Once the desired clusters are obtained, the respective cluster centroids are considered as representatives of the clusters and the nearest neighbor rule is used for classifying an unknown text document. Series of experiments have been conducted to bring out the superiority of the proposed model over other recent state of the art models on 20Newsgroups dataset.
Class Specific Feature Selection for Interval Valued Data Through Interval K-Means Clustering
May 31, 2017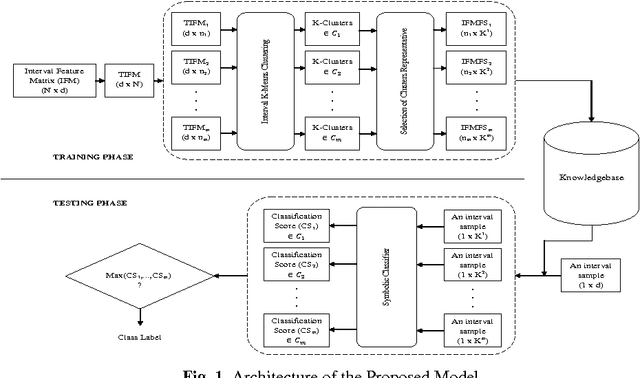
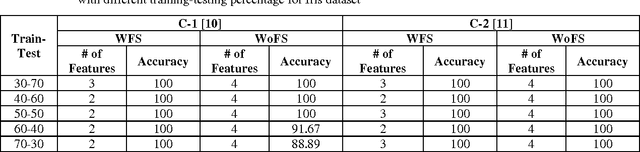
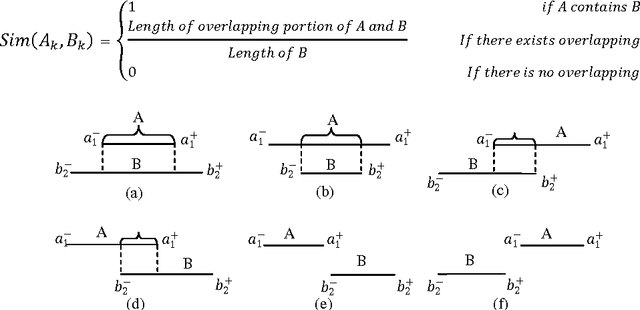
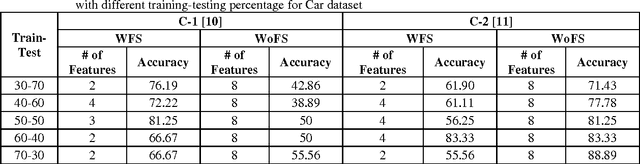
In this paper, a novel feature selection approach for supervised interval valued features is proposed. The proposed approach takes care of selecting the class specific features through interval K-Means clustering. The kernel of K-Means clustering algorithm is modified to adapt interval valued data. During training, a set of samples corresponding to a class is fed into the interval K-Means clustering algorithm, which clusters features into K distinct clusters. Hence, there are K number of features corresponding to each class. Subsequently, corresponding to each class, the cluster representatives are chosen. This procedure is repeated for all the samples of remaining classes. During testing the feature indices correspond to each class are used for validating the given dataset through classification using suitable symbolic classifiers. For experimentation, four standard supervised interval datasets are used. The results show the superiority of the proposed model when compared with the other existing state-of-the-art feature selection methods.
* 12 Pages, 3 figures, 7 tables
Symbolic Representation and Classification of Logos
Dec 28, 2016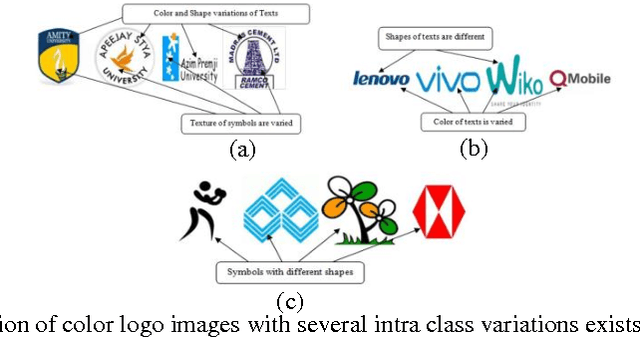
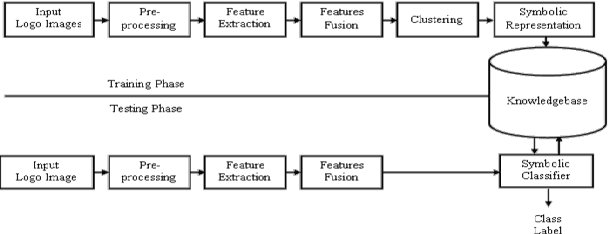
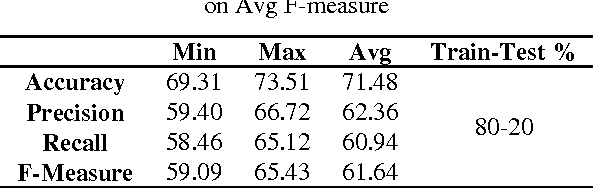

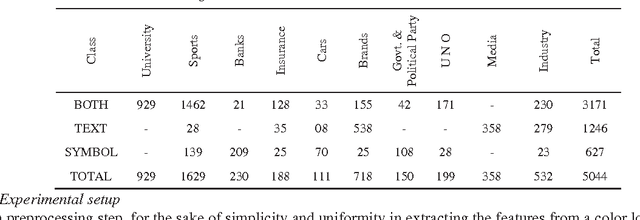
In this paper, a model for classification of logos based on symbolic representation of features is presented. The proposed model makes use of global features of logo images such as color, texture, and shape features for classification. The logo images are broadly classified into three different classes, viz., logo image containing only text, an image with only symbol, and an image with both text and a symbol. In each class, the similar looking logo images are clustered using K-means clustering algorithm. The intra-cluster variations present in each cluster corresponding to each class are then preserved using symbolic interval data. Thus referenced logo images are represented in the form of interval data. A sample logo image is then classified using suitable symbolic classifier. For experimentation purpose, relatively large amount of color logo images is created consisting of 5044 logo images. The classification results are validated with the help of accuracy, precision, recall, F-measure, and time. To check the efficacy of the proposed model, the comparative analyses are given against the other models. The results show that the proposed model outperforms the other models with respect to time and F-measure.
User Dependent Features in Online Signature Verification
Nov 30, 2016
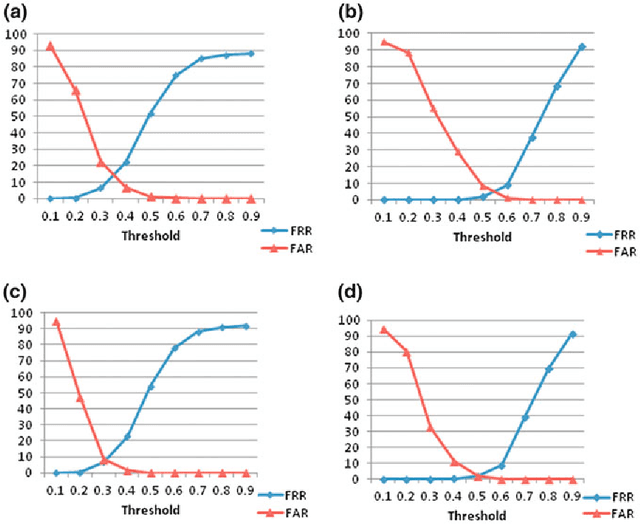
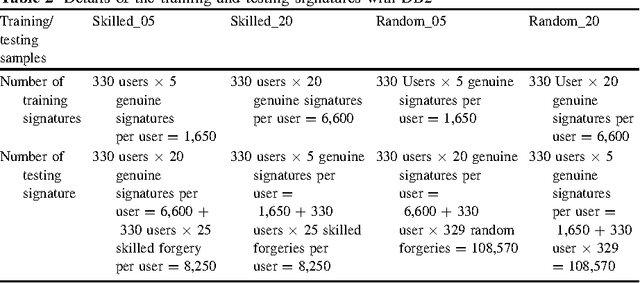

In this paper, we propose a novel approach for verification of on-line signatures based on user dependent feature selection and symbolic representation. Unlike other signature verification methods, which work with same features for all users, the proposed approach introduces the concept of user dependent features. It exploits the typicality of each and every user to select different features for different users. Initially all possible features are extracted for all users and a method of feature selection is employed for selecting user dependent features. The selected features are clustered using Fuzzy C means algorithm. In order to preserve the intra-class variation within each user, we recommend to represent each cluster in the form of an interval valued symbolic feature vector. A method of signature verification based on the proposed cluster based symbolic representation is also presented. Extensive experimentations are conducted on MCYT-100 User (DB1) and MCYT-330 User (DB2) online signature data sets to demonstrate the effectiveness of the proposed novel approach.
Segmentation and Classification of Skin Lesions for Disease Diagnosis
Sep 12, 2016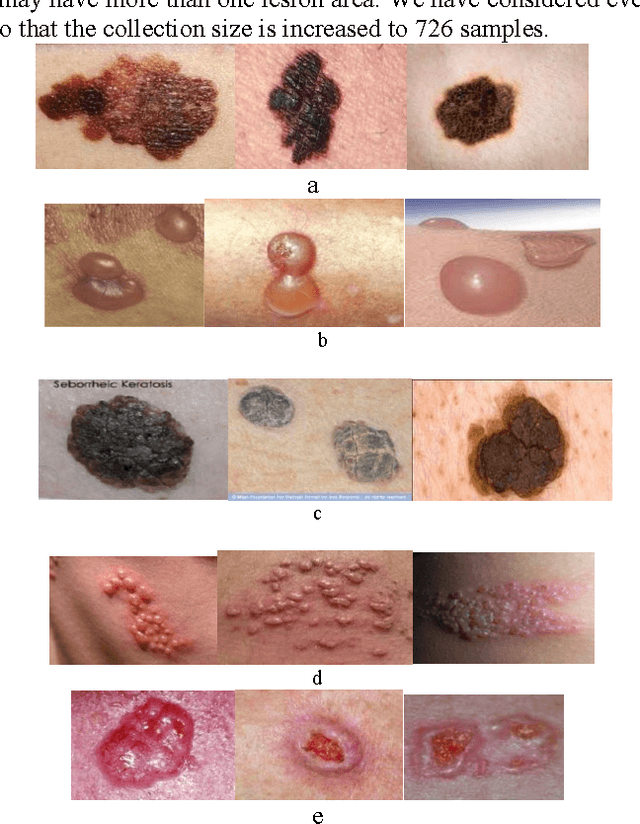
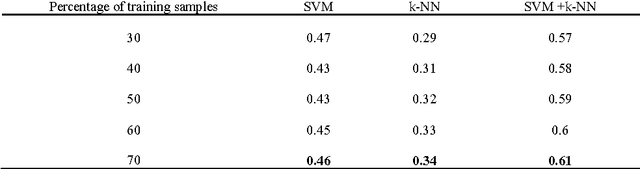
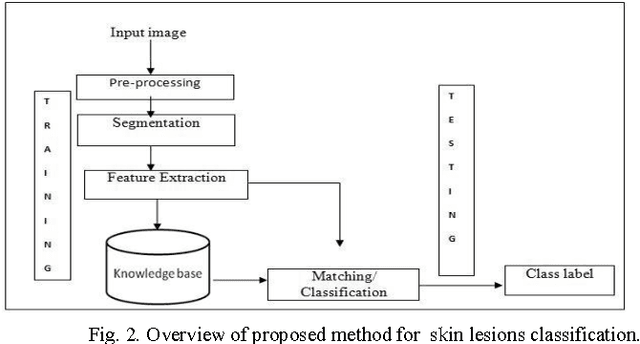
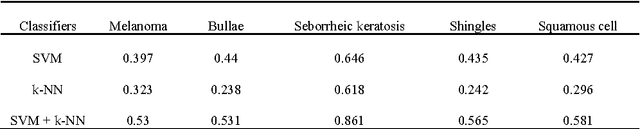
In this paper, a novel approach for automatic segmentation and classification of skin lesions is proposed. Initially, skin images are filtered to remove unwanted hairs and noise and then the segmentation process is carried out to extract lesion areas. For segmentation, a region growing method is applied by automatic initialization of seed points. The segmentation performance is measured with different well known measures and the results are appreciable. Subsequently, the extracted lesion areas are represented by color and texture features. SVM and k-NN classifiers are used along with their fusion for the classification using the extracted features. The performance of the system is tested on our own dataset of 726 samples from 141 images consisting of 5 different classes of diseases. The results are very promising with 46.71% and 34% of F-measure using SVM and k-NN classifier respectively and with 61% of F-measure for fusion of SVM and k-NN.
Features Fusion for Classification of Logos
Sep 06, 2016
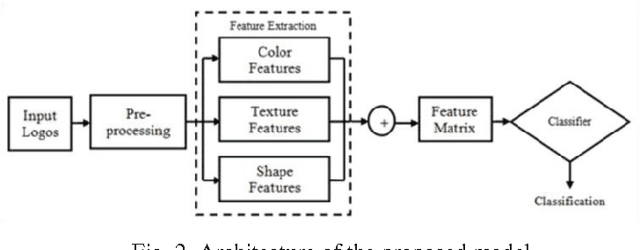

In this paper, a logo classification system based on the appearance of logo images is proposed. The proposed classification system makes use of global characteristics of logo images for classification. Color, texture, and shape of a logo wholly describe the global characteristics of logo images. The various combinations of these characteristics are used for classification. The combination contains only with single feature or with fusion of two features or fusion of all three features considered at a time respectively. Further, the system categorizes the logo image into: a logo image with fully text or with fully symbols or containing both symbols and texts.. The K-Nearest Neighbour (K-NN) classifier is used for classification. Due to the lack of color logo image dataset in the literature, the same is created consisting 5044 color logo images. Finally, the performance of the classification system is evaluated through accuracy, precision, recall and F-measure computed from the confusion matrix. The experimental results show that the most promising results are obtained for fusion of features.
* 10 pages, 5 figures, 9 tables
A Novel Approach for Shot Boundary Detection in Videos
Aug 24, 2016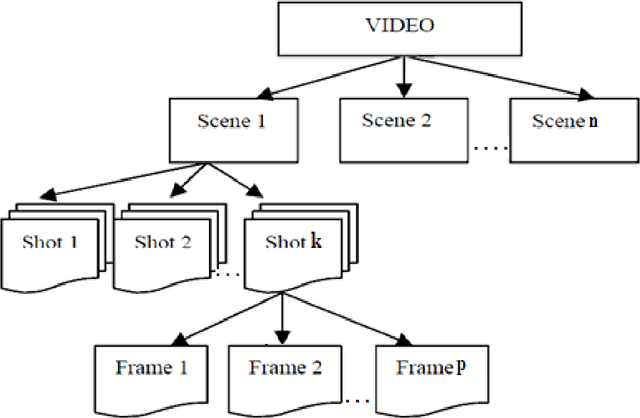
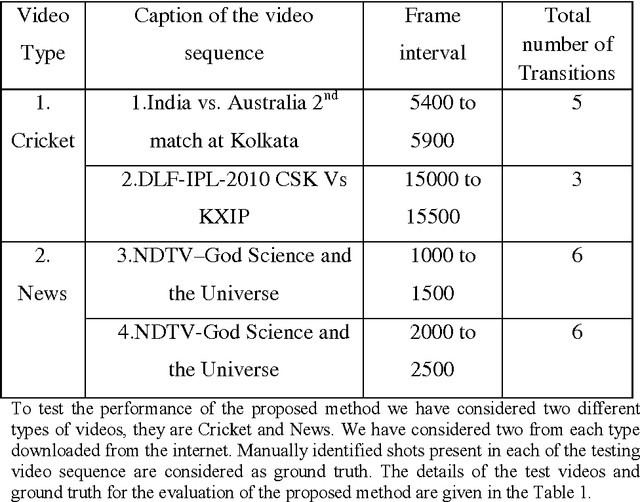
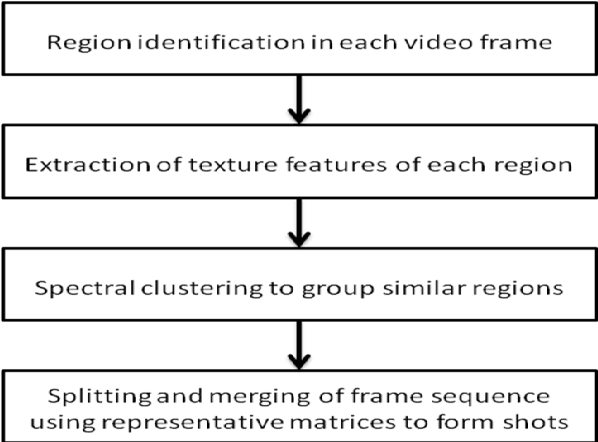
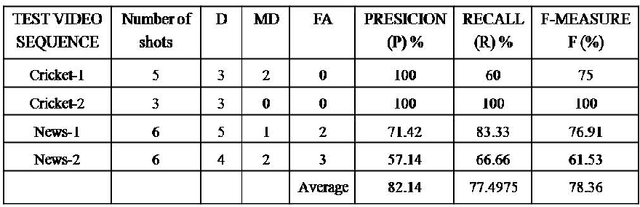
This paper presents a novel approach for video shot boundary detection. The proposed approach is based on split and merge concept. A fisher linear discriminant criterion is used to guide the process of both splitting and merging. For the purpose of capturing the between class and within class scatter we employ 2D2 FLD method which works on texture feature of regions in each frame of a video. Further to reduce the complexity of the process we propose to employ spectral clustering to group related regions together to a single there by achieving reduction in dimension. The proposed method is experimentally also validated on a cricket video. It is revealed that shots obtained by the proposed approach are highly cohesive and loosely coupled
* 12 pages, 2 figures, 2 tables; Conference: Multimedia Processing, Communication and Computing Applications, 2012