 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Text Categorization Using Recursive K-means Clustering
Jun 24, 2017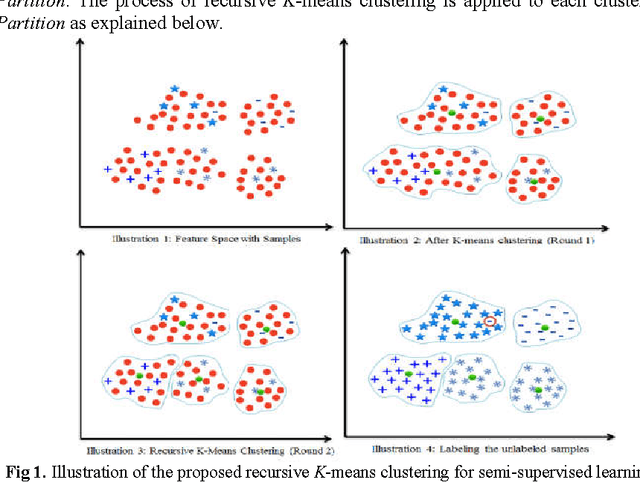
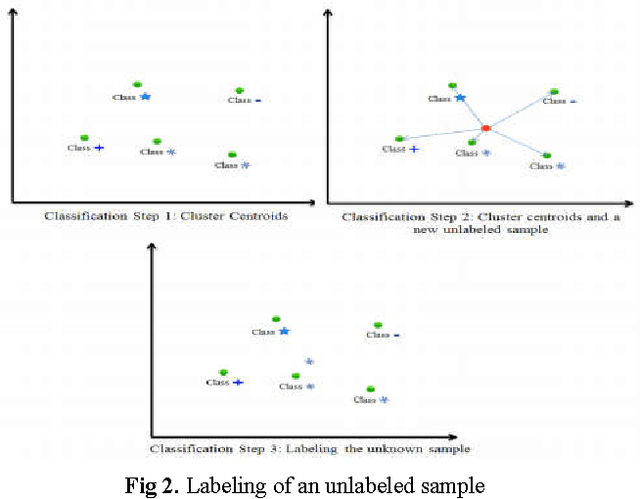
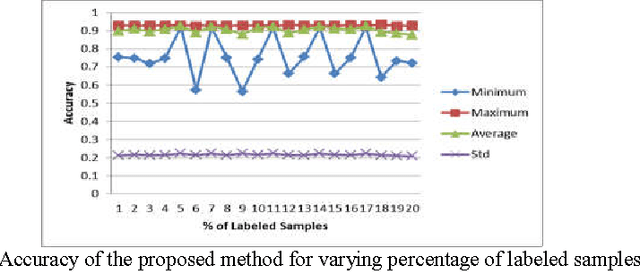
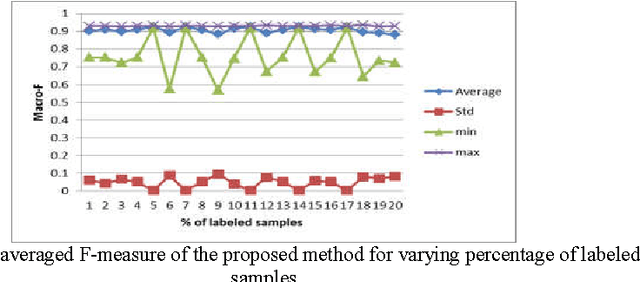
In this paper, we present a semi-supervised learning algorithm for classification of text documents. A method of labeling unlabeled text documents is presented. The presented method is based on the principle of divide and conquer strategy. It uses recursive K-means algorithm for partitioning both labeled and unlabeled data collection. The K-means algorithm is applied recursively on each partition till a desired level partition is achieved such that each partition contains labeled documents of a single class. Once the desired clusters are obtained, the respective cluster centroids are considered as representatives of the clusters and the nearest neighbor rule is used for classifying an unknown text document. Series of experiments have been conducted to bring out the superiority of the proposed model over other recent state of the art models on 20Newsgroups dataset.
Cluster Based Symbolic Representation for Skewed Text Categorization
Jun 24, 2017

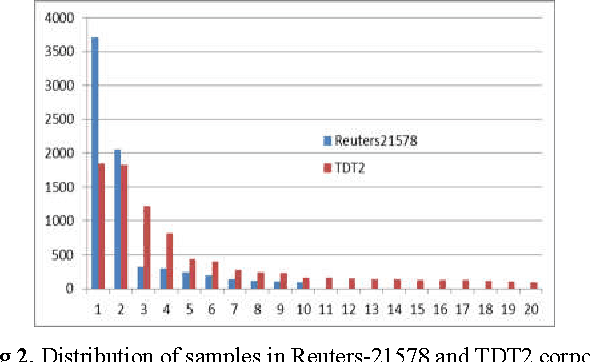

In this work, a problem associated with imbalanced text corpora is addressed. A method of converting an imbalanced text corpus into a balanced one is presented. The presented method employs a clustering algorithm for conversion. Initially to avoid curse of dimensionality, an effective representation scheme based on term class relevancy measure is adapted, which drastically reduces the dimension to the number of classes in the corpus. Subsequently, the samples of larger sized classes are grouped into a number of subclasses of smaller sizes to make the entire corpus balanced. Each subclass is then given a single symbolic vector representation by the use of interval valued features. This symbolic representation in addition to being compact helps in reducing the space requirement and also the classification time. The proposed model has been empirically demonstrated for its superiority on bench marking datasets viz., Reuters 21578 and TDT2. Further, it has been compared against several other existing contemporary models including model based on support vector machine. The comparative analysis indicates that the proposed model outperforms the other existing models.