 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Text Categorization Using Recursive K-means Clustering
Jun 24, 2017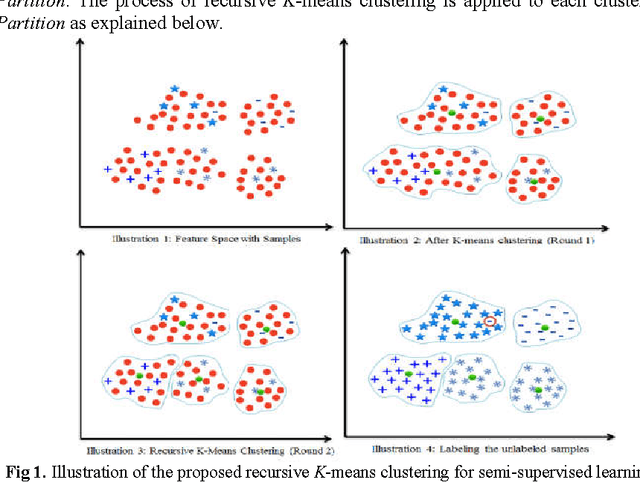
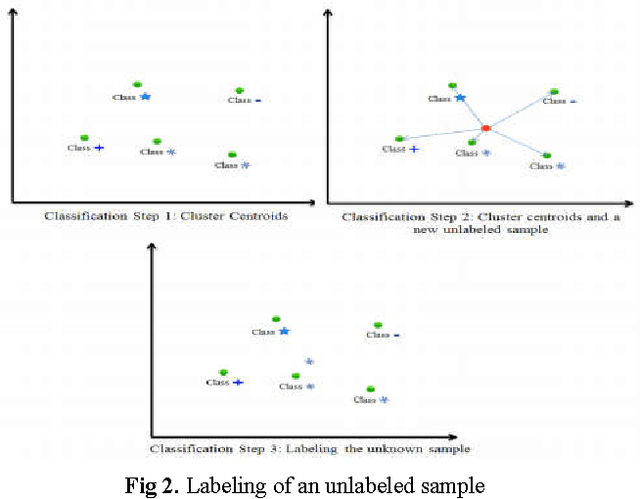
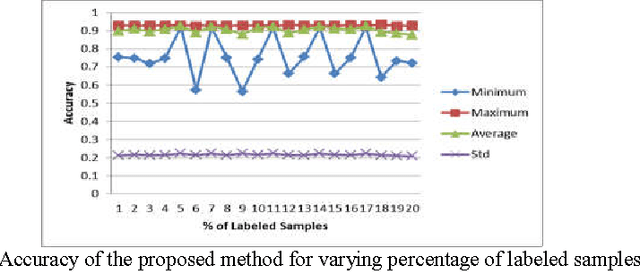
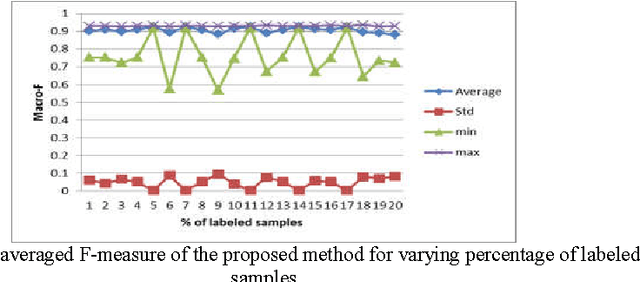
In this paper, we present a semi-supervised learning algorithm for classification of text documents. A method of labeling unlabeled text documents is presented. The presented method is based on the principle of divide and conquer strategy. It uses recursive K-means algorithm for partitioning both labeled and unlabeled data collection. The K-means algorithm is applied recursively on each partition till a desired level partition is achieved such that each partition contains labeled documents of a single class. Once the desired clusters are obtained, the respective cluster centroids are considered as representatives of the clusters and the nearest neighbor rule is used for classifying an unknown text document. Series of experiments have been conducted to bring out the superiority of the proposed model over other recent state of the art models on 20Newsgroups dataset.
Cluster Based Symbolic Representation for Skewed Text Categorization
Jun 24, 2017

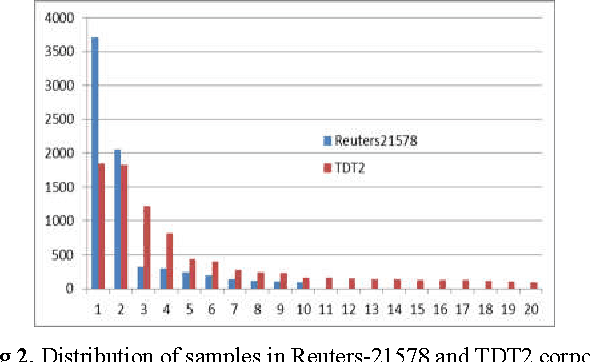

In this work, a problem associated with imbalanced text corpora is addressed. A method of converting an imbalanced text corpus into a balanced one is presented. The presented method employs a clustering algorithm for conversion. Initially to avoid curse of dimensionality, an effective representation scheme based on term class relevancy measure is adapted, which drastically reduces the dimension to the number of classes in the corpus. Subsequently, the samples of larger sized classes are grouped into a number of subclasses of smaller sizes to make the entire corpus balanced. Each subclass is then given a single symbolic vector representation by the use of interval valued features. This symbolic representation in addition to being compact helps in reducing the space requirement and also the classification time. The proposed model has been empirically demonstrated for its superiority on bench marking datasets viz., Reuters 21578 and TDT2. Further, it has been compared against several other existing contemporary models including model based on support vector machine. The comparative analysis indicates that the proposed model outperforms the other existing models.
Term-Class-Max-Support : A Simple Text Document Categorization Approach Using Term-Class Relevance Measure
Oct 16, 2016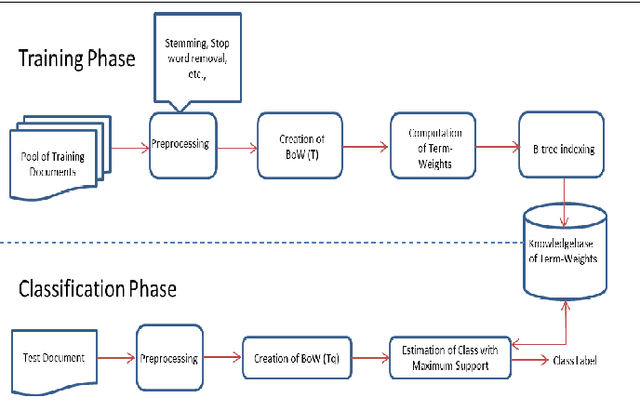
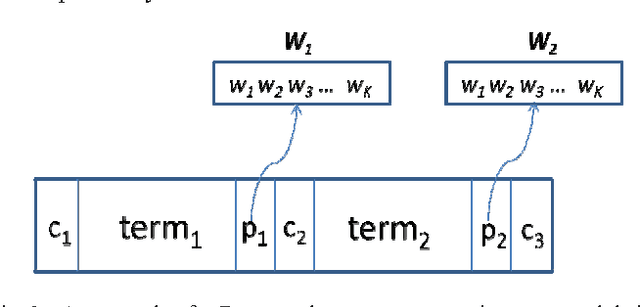
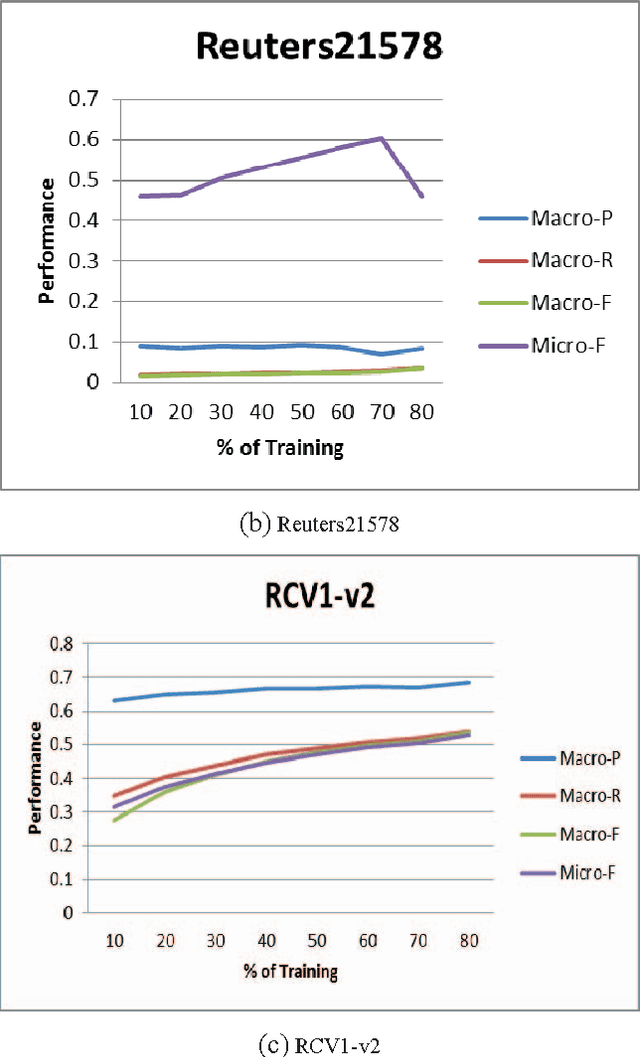
In this paper, a simple text categorization method using term-class relevance measures is proposed. Initially, text documents are processed to extract significant terms present in them. For every term extracted from a document, we compute its importance in preserving the content of a class through a novel term-weighting scheme known as Term_Class Relevance (TCR) measure proposed by Guru and Suhil (2015) [1]. In this way, for every term, its relevance for all the classes present in the corpus is computed and stored in the knowledgebase. During testing, the terms present in the test document are extracted and the term-class relevance of each term is obtained from the stored knowledgebase. To achieve quick search of term weights, Btree indexing data structure has been adapted. Finally, the class which receives maximum support in terms of term-class relevance is decided to be the class of the given test document. The proposed method works in logarithmic complexity in testing time and simple to implement when compared to any other text categorization techniques available in literature. The experiments conducted on various benchmarking datasets have revealed that the performance of the proposed method is satisfactory and encouraging.
A Novel Term_Class Relevance Measure for Text Categorization
Sep 14, 2016


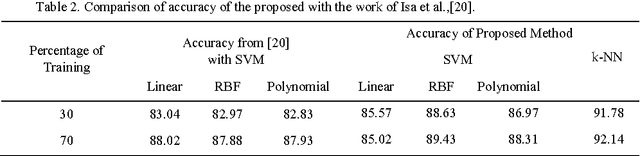
In this paper, we introduce a new measure called Term_Class relevance to compute the relevancy of a term in classifying a document into a particular class. The proposed measure estimates the degree of relevance of a given term, in placing an unlabeled document to be a member of a known class, as a product of Class_Term weight and Class_Term density; where the Class_Term weight is the ratio of the number of documents of the class containing the term to the total number of documents containing the term and the Class_Term density is the relative density of occurrence of the term in the class to the total occurrence of the term in the entire population. Unlike the other existing term weighting schemes such as TF-IDF and its variants, the proposed relevance measure takes into account the degree of relative participation of the term across all documents of the class to the entire population. To demonstrate the significance of the proposed measure experimentation has been conducted on the 20 Newsgroups dataset. Further, the superiority of the novel measure is brought out through a comparative analysis.
* 12 pages, 6 figures, 2 tables
Segmentation and Classification of Skin Lesions for Disease Diagnosis
Sep 12, 2016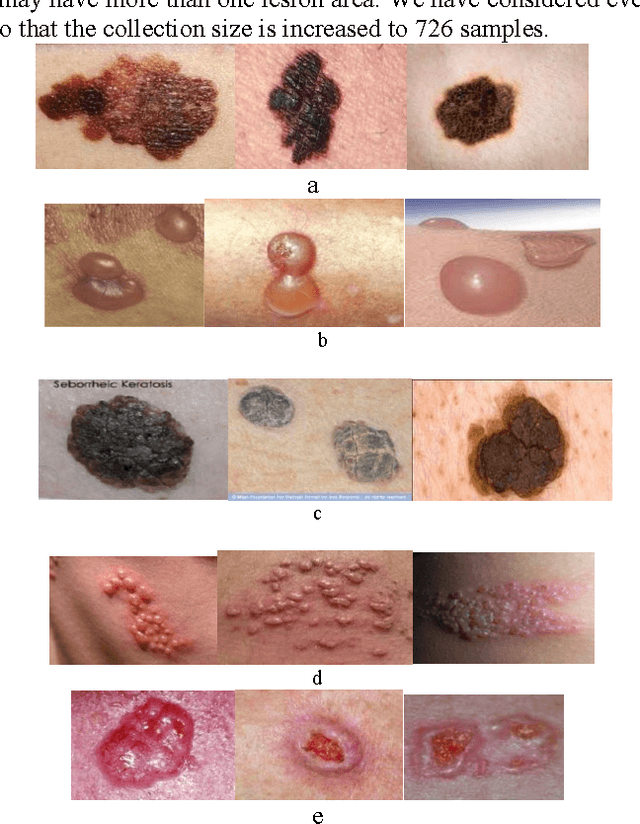
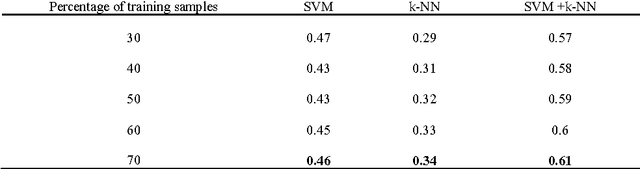
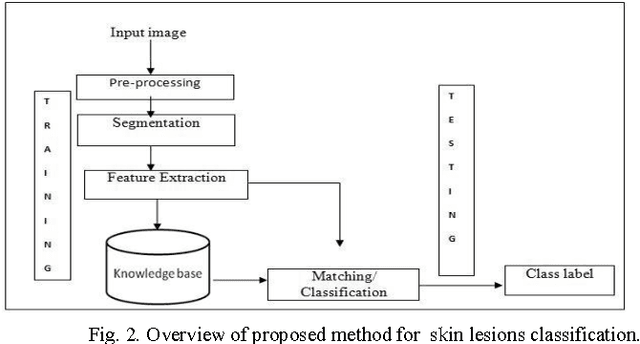
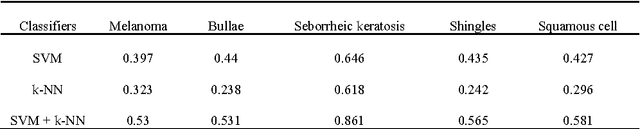
In this paper, a novel approach for automatic segmentation and classification of skin lesions is proposed. Initially, skin images are filtered to remove unwanted hairs and noise and then the segmentation process is carried out to extract lesion areas. For segmentation, a region growing method is applied by automatic initialization of seed points. The segmentation performance is measured with different well known measures and the results are appreciable. Subsequently, the extracted lesion areas are represented by color and texture features. SVM and k-NN classifiers are used along with their fusion for the classification using the extracted features. The performance of the system is tested on our own dataset of 726 samples from 141 images consisting of 5 different classes of diseases. The results are very promising with 46.71% and 34% of F-measure using SVM and k-NN classifier respectively and with 61% of F-measure for fusion of SVM and k-NN.
A Novel Approach for Shot Boundary Detection in Videos
Aug 24, 2016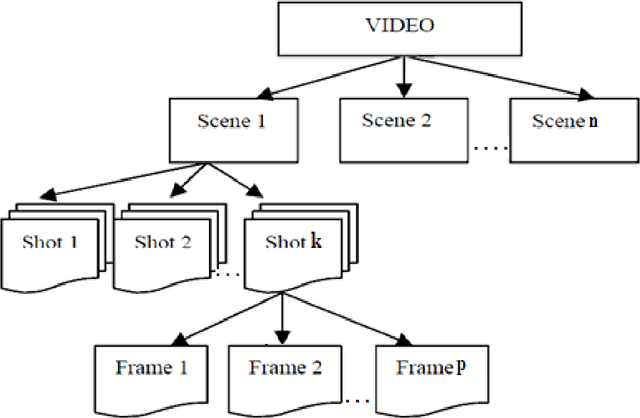
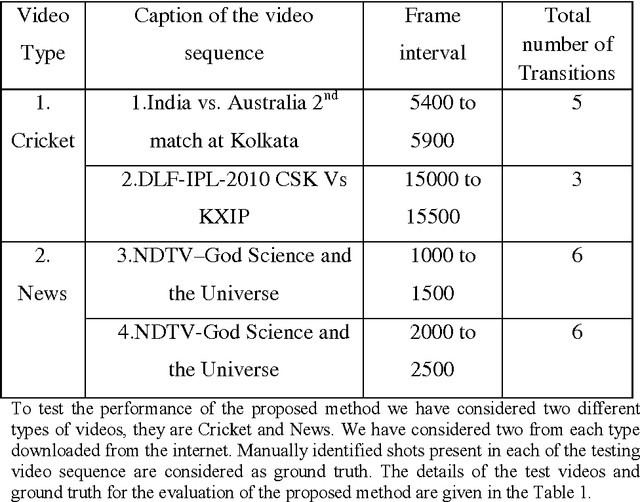
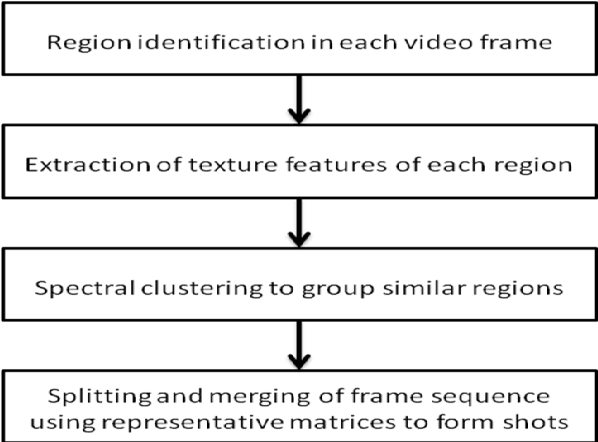
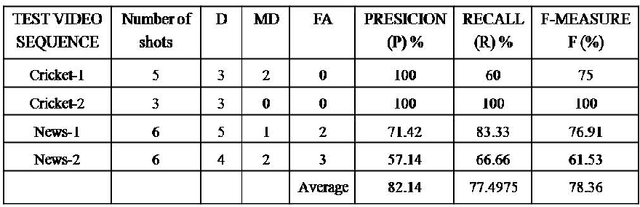
This paper presents a novel approach for video shot boundary detection. The proposed approach is based on split and merge concept. A fisher linear discriminant criterion is used to guide the process of both splitting and merging. For the purpose of capturing the between class and within class scatter we employ 2D2 FLD method which works on texture feature of regions in each frame of a video. Further to reduce the complexity of the process we propose to employ spectral clustering to group related regions together to a single there by achieving reduction in dimension. The proposed method is experimentally also validated on a cricket video. It is revealed that shots obtained by the proposed approach are highly cohesive and loosely coupled
* 12 pages, 2 figures, 2 tables; Conference: Multimedia Processing, Communication and Computing Applications, 2012