 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerm-Class-Max-Support : A Simple Text Document Categorization Approach Using Term-Class Relevance Measure
Paper and Code
Oct 16, 2016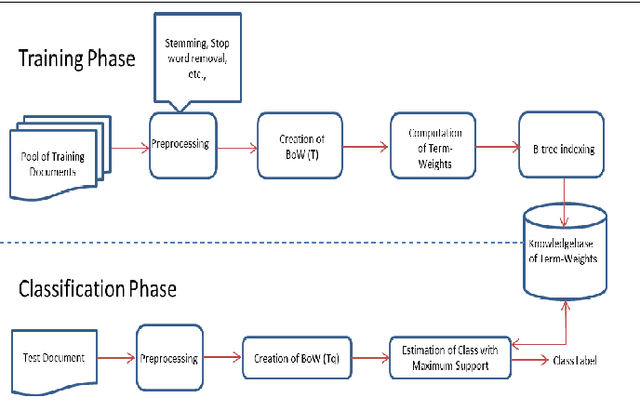
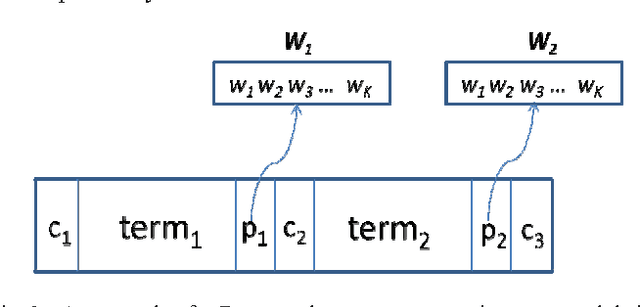
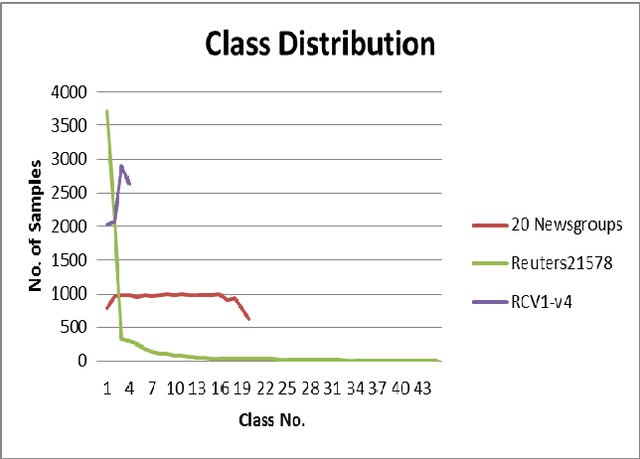
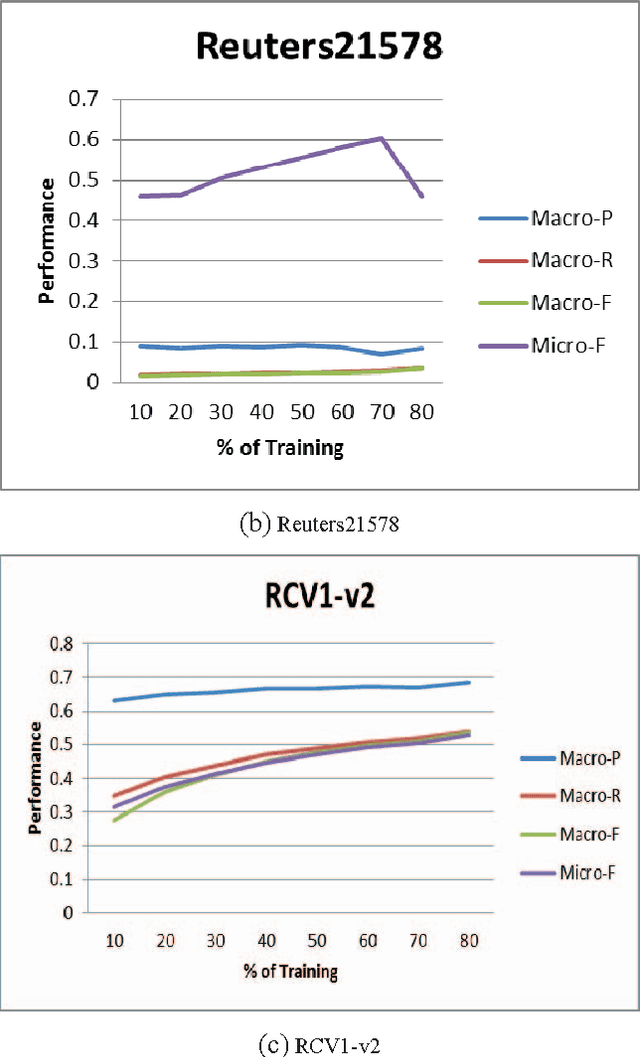
In this paper, a simple text categorization method using term-class relevance measures is proposed. Initially, text documents are processed to extract significant terms present in them. For every term extracted from a document, we compute its importance in preserving the content of a class through a novel term-weighting scheme known as Term_Class Relevance (TCR) measure proposed by Guru and Suhil (2015) [1]. In this way, for every term, its relevance for all the classes present in the corpus is computed and stored in the knowledgebase. During testing, the terms present in the test document are extracted and the term-class relevance of each term is obtained from the stored knowledgebase. To achieve quick search of term weights, Btree indexing data structure has been adapted. Finally, the class which receives maximum support in terms of term-class relevance is decided to be the class of the given test document. The proposed method works in logarithmic complexity in testing time and simple to implement when compared to any other text categorization techniques available in literature. The experiments conducted on various benchmarking datasets have revealed that the performance of the proposed method is satisfactory and encouraging.