 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor and Gradient Features for Text Segmentation from Video Frames
Aug 22, 2017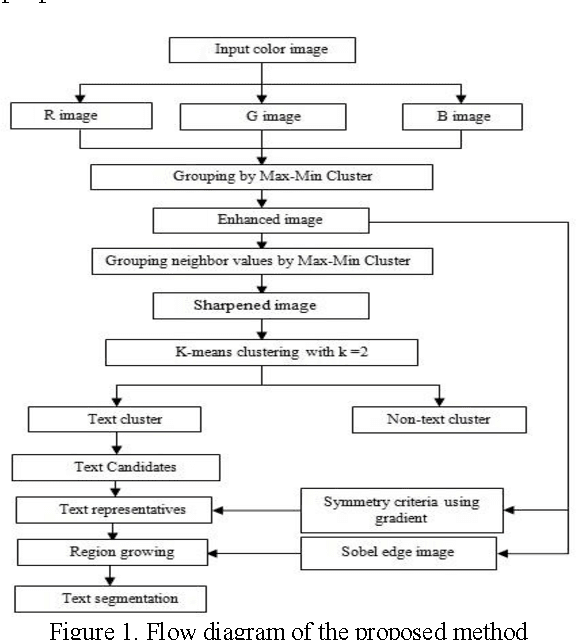



Text segmentation in a video is drawing attention of researchers in the field of image processing, pattern recognition and document image analysis because it helps in annotating and labeling video events accurately. We propose a novel idea of generating an enhanced frame from the R, G, and B channels of an input frame by grouping high and low values using Min-Max clustering criteria. We also perform sliding window on enhanced frame to group high and low values from the neighboring pixel values to further enhance the frame. Subsequently, we use k-means with k=2 clustering algorithm to separate text and non-text regions. The fully connected components will be identified in the skeleton of the frame obtained by k-means clustering. Concept of connected component analysis based on gradient feature has been adapted for the purpose of symmetry verification. The components which satisfy symmetric verification are selected to be the representatives of text regions and they are permitted to grow to cover their respective region fully containing text. The method is tested on variety of video frames to evaluate the performance of the method in terms of recall, precision and f-measure. The results show that method is promising and encouraging.
Discrete Wavelet Transform and Gradient Difference based approach for text localization in videos
Feb 24, 2015



The text detection and localization is important for video analysis and understanding. The scene text in video contains semantic information and thus can contribute significantly to video retrieval and understanding. However, most of the approaches detect scene text in still images or single video frame. Videos differ from images in temporal redundancy. This paper proposes a novel hybrid method to robustly localize the texts in natural scene images and videos based on fusion of discrete wavelet transform and gradient difference. A set of rules and geometric properties have been devised to localize the actual text regions. Then, morphological operation is performed to generate the text regions and finally the connected component analysis is employed to localize the text in a video frame. The experimental results obtained on publicly available standard ICDAR 2003 and Hua dataset illustrate that the proposed method can accurately detect and localize texts of various sizes, fonts and colors. The experimentation on huge collection of video databases reveal the suitability of the proposed method to video databases.