 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape Representation and Classification through Pattern Spectrum and Local Binary Pattern - A Decision Level Fusion Approach
Apr 27, 2015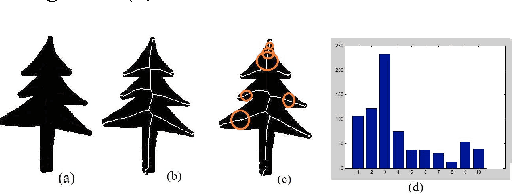
In this paper, we present a decision level fused local Morphological Pattern Spectrum(PS) and Local Binary Pattern (LBP) approach for an efficient shape representation and classification. This method makes use of Earth Movers Distance(EMD) as the measure in feature matching and shape retrieval process. The proposed approach has three major phases : Feature Extraction, Construction of hybrid spectrum knowledge base and Classification. In the first phase, feature extraction of the shape is done using pattern spectrum and local binary pattern method. In the second phase, the histograms of both pattern spectrum and local binary pattern are fused and stored in the knowledge base. In the third phase, the comparison and matching of the features, which are represented in the form of histograms, is done using Earth Movers Distance(EMD) as metric. The top-n shapes are retrieved for each query shape. The accuracy is tested by means of standard Bulls eye score method. The experiments are conducted on publicly available shape datasets like Kimia-99, Kimia-216 and MPEG-7. The comparative study is also provided with the well known approaches to exhibit the retrieval accuracy of the proposed approach.
Text Localization in Video Using Multiscale Weber's Local Descriptor
Apr 15, 2015



In this paper, we propose a novel approach for detecting the text present in videos and scene images based on the Multiscale Weber's Local Descriptor (MWLD). Given an input video, the shots are identified and the key frames are extracted based on their spatio-temporal relationship. From each key frame, we detect the local region information using WLD with different radius and neighborhood relationship of pixel values and hence obtained intensity enhanced key frames at multiple scales. These multiscale WLD key frames are merged together and then the horizontal gradients are computed using morphological operations. The obtained results are then binarized and the false positives are eliminated based on geometrical properties. Finally, we employ connected component analysis and morphological dilation operation to determine the text regions that aids in text localization. The experimental results obtained on publicly available standard Hua, Horizontal-1 and Horizontal-2 video dataset illustrate that the proposed method can accurately detect and localize texts of various sizes, fonts and colors in videos.
Discrete Wavelet Transform and Gradient Difference based approach for text localization in videos
Feb 24, 2015



The text detection and localization is important for video analysis and understanding. The scene text in video contains semantic information and thus can contribute significantly to video retrieval and understanding. However, most of the approaches detect scene text in still images or single video frame. Videos differ from images in temporal redundancy. This paper proposes a novel hybrid method to robustly localize the texts in natural scene images and videos based on fusion of discrete wavelet transform and gradient difference. A set of rules and geometric properties have been devised to localize the actual text regions. Then, morphological operation is performed to generate the text regions and finally the connected component analysis is employed to localize the text in a video frame. The experimental results obtained on publicly available standard ICDAR 2003 and Hua dataset illustrate that the proposed method can accurately detect and localize texts of various sizes, fonts and colors. The experimentation on huge collection of video databases reveal the suitability of the proposed method to video databases.
Video Text Localization with an emphasis on Edge Features
Feb 22, 2015



The text detection and localization plays a major role in video analysis and understanding. The scene text embedded in video consist of high-level semantics and hence contributes significantly to visual content analysis and retrieval. This paper proposes a novel method to robustly localize the texts in natural scene images and videos based on sobel edge emphasizing approach. The input image is preprocessed and edge emphasis is done to detect the text clusters. Further, a set of rules have been devised using morphological operators for false positive elimination and connected component analysis is performed to detect the text regions and hence text localization is performed. The experimental results obtained on publicly available standard datasets illustrate that the proposed method can detect and localize the texts of various sizes, fonts and colors.
Gradient Difference based approach for Text Localization in Compressed domain
Feb 13, 2015



In this paper, we propose a gradient difference based approach to text localization in videos and scene images. The input video frame/ image is first compressed using multilevel 2-D wavelet transform. The edge information of the reconstructed image is found which is further used for finding the maximum gradient difference between the pixels and then the boundaries of the detected text blocks are computed using zero crossing technique. We perform logical AND operation of the text blocks obtained by gradient difference and the zero crossing technique followed by connected component analysis to eliminate the false positives. Finally, the morphological dilation operation is employed on the detected text blocks for scene text localization. The experimental results obtained on publicly available standard datasets illustrate that the proposed method can detect and localize the texts of various sizes, fonts and colors.
Skeleton Matching based approach for Text Localization in Scene Images
Feb 13, 2015



In this paper, we propose a skeleton matching based approach which aids in text localization in scene images. The input image is preprocessed and segmented into blocks using connected component analysis. We obtain the skeleton of the segmented block using morphology based approach. The skeletonized images are compared with the trained templates in the database to categorize into text and non-text blocks. Further, the newly designed geometrical rules and morphological operations are employed on the detected text blocks for scene text localization. The experimental results obtained on publicly available standard datasets illustrate that the proposed method can detect and localize the texts of various sizes, fonts and colors.
3D Face Recognition using Significant Point based SULD Descriptor
Oct 26, 2012



In this work, we present a new 3D face recognition method based on Speeded-Up Local Descriptor (SULD) of significant points extracted from the range images of faces. The proposed model consists of a method for extracting distinctive invariant features from range images of faces that can be used to perform reliable matching between different poses of range images of faces. For a given 3D face scan, range images are computed and the potential interest points are identified by searching at all scales. Based on the stability of the interest point, significant points are extracted. For each significant point we compute the SULD descriptor which consists of vector made of values from the convolved Haar wavelet responses located on concentric circles centred on the significant point, and where the amount of Gaussian smoothing is proportional to the radii of the circles. Experimental results show that the newly proposed method provides higher recognition rate compared to other existing contemporary models developed for 3D face recognition.